When many first learn to program computers, they are often introduced to ASCII with or without knowing it. ASCII stands for "American Standard Code for Information Interchange" and when programmers use it, they are often talking about the character encoding scheme for the English alphabet. If you're using C or C++ and use the char data type to write strings, you're probably using ASCII. ASCII actually only uses 7 bits and is from 0 - 127. (There is an extended ASCII set, but in this article, only the original set will be considered.) This works well when you only want to use Latin letters in your programs, but in our more global world, we need to thinking about making programs that can display characters in other characters such as Korean, Chinese, or Japanese.
UNICODE was developed as a way to encode all of the characters for every language, but when we consider languages like Korean and Chinese, 8 bit characters just isn't enough. Windows programmers maybe familiar with USC-2. USC-2 is a 16 bit version of UNICODE and it can encode the values for all of the most common UNICODE characters. In USC-2, all characters are exactly 16 bits. These days, Windows also supports UTF-16 as well which uses 16 bit values, but some characters can be composed of two 16 bit units. This works well on Windows and fits perfectly with the Windows 16 bit wchar_t type. For many who want to support different language characters and at the same time be able to support multiple platforms, this is not enough..
wchar_t has some disadvantages. For example, wchar_t is 16 bits on Windows, but 32 on some other platforms. Also when using wchar_t and even with UTF-16 and UTF-32, you have to worry about endianess. UTF-8 can be used as an alternative to this.
UTF-8 is a way to encode the UNICODE values. From this point forward, the word character in this article will be used to refer to the value of the character in unicode which goes from 1 through 1,112,064 with zero, which can be used as a string terminator. UTF-8 is a variable-sized encoding. In UTF-8, characters will code into eito either 1, 2, 3, or 4 bytes. 1 byte encodings are only for characters from 0 to 127 meaning if it's a 1 byte encoding it'll be equivilent to ASCII. 2 byte encodings are for characters from 128 to 2047. 3 byte encodings are for characters from 2048 to 65535 and 4 byte encodings are for characters from 65536 to 1,112,064. To understand how the encoding works, we'll need to examine the binary representation of each character's numeric value. To do this easily, I'll also use hexadecimal notation as one hexadecimal digit always corresponds to a 4 bit nibble. Here's a quick table.
So 2C (hexadecimal) = (2 X 16) + (12 X 1) = 48(decimal) and 0010 1100(binary)
I understand that many may know this already, but I want to make sure new programmers will be able to understand.
In UTF-8, the high-order bits in binary are important. UTF-8 works by using the leading high-order bits of the first byte to tell how many bytes were used to encode the value. For 8 bit encoding from 0 to 127, the high-order bit will always be zero. Because of this, if the high-order bit is zero, the byte will always be treated as a single byte encoding. Therefore, all single byte encodings have the following form: 0XXX XXXX
7 bits are available to code the number. Here is the format for all of the encodings:
Once you know the format of UTF-8, converting back and forth between it is fairly simple. To convert to UTF-8, you can easily see if it will encode to 1, 2, 3, or 4 bytes by checking the numerical range. Then copy the bits to the correct location.
Let's try an example. I'm going to use hexadecimal value 1FACBD for this example. Now, I don't believe this is a real UNICODE character, but it'll help us see how to encode values. The number is greater than FFFF so it will require a 4-byte encoding. Let's see how it'll work. First, here's the value in binary.
This will be a 4-byte encoding so we'll need to use the following format.
Now converting to UTF-8 is as simple as copying the bits from right to left into the correct positions.
Like I said, UTF-8 is a fairly straight-forward format.
If you want to support non-Latin characters, UTF-8 has a lot of advantages. Since it codes characters using one byte chunks and since UTF-8 strings will never contain a "null" byte, you can use UTF-8 strings with most traditional null-terminated string processing functions. More and more things are being encoded in UTF-8, especially things that are sent over the Internet. Many web pages are coded in UTF-8, and UTF-8 is often used with XML and JSON. Supporting UTF-8 will allow developers to retrieve text data from other sources without conversions. UTF-8 is also byte oriented and as long as it is read one byte at a time, you don't have to worry about endianess.
Now it's not difficult converting back and forth between UTF-8. As a programmer who wants to use UNICODE, you have to decided whether or not it would it be better to continue to store things as wide character string, using UTF-8 only to store things in files or to use UTF-8 all of the time. If you want to support non-Latin characters, UTF-8 has a lot of advantages. Unless you need to do a lot of string manipulation, you can keep your strings in UTF-8 until you need to display them. Typical string operations like concatenation, copying, and finding sub-strings can be done directly in UTF-8. If you want to parse through all of the characters to show them in a GUI for example, you can create an iterator to go through each character. (Comment From Aressera). Using UTF-8 in code is not difficult to implement and if you're wondering how to add support for non-Latin characters, it's worth considering.
ASCII Wiki - http://en.wikipedia.org/wiki/ASCII
UTF-8 Encoding - http://www.fileformat.info/info/unicode/utf8.htm
UTF-8 Wiki - http://en.wikipedia.org/wiki/UTF-8
4 Aug 2013: Initial Draft
6 Aug 2013: Updated Introductions and Conclusions
This article was originally posted on the Squared'D Blog
UNICODE was developed as a way to encode all of the characters for every language, but when we consider languages like Korean and Chinese, 8 bit characters just isn't enough. Windows programmers maybe familiar with USC-2. USC-2 is a 16 bit version of UNICODE and it can encode the values for all of the most common UNICODE characters. In USC-2, all characters are exactly 16 bits. These days, Windows also supports UTF-16 as well which uses 16 bit values, but some characters can be composed of two 16 bit units. This works well on Windows and fits perfectly with the Windows 16 bit wchar_t type. For many who want to support different language characters and at the same time be able to support multiple platforms, this is not enough..
wchar_t has some disadvantages. For example, wchar_t is 16 bits on Windows, but 32 on some other platforms. Also when using wchar_t and even with UTF-16 and UTF-32, you have to worry about endianess. UTF-8 can be used as an alternative to this.
What is UTF8 and how is it encoded?
UTF-8 is a way to encode the UNICODE values. From this point forward, the word character in this article will be used to refer to the value of the character in unicode which goes from 1 through 1,112,064 with zero, which can be used as a string terminator. UTF-8 is a variable-sized encoding. In UTF-8, characters will code into eito either 1, 2, 3, or 4 bytes. 1 byte encodings are only for characters from 0 to 127 meaning if it's a 1 byte encoding it'll be equivilent to ASCII. 2 byte encodings are for characters from 128 to 2047. 3 byte encodings are for characters from 2048 to 65535 and 4 byte encodings are for characters from 65536 to 1,112,064. To understand how the encoding works, we'll need to examine the binary representation of each character's numeric value. To do this easily, I'll also use hexadecimal notation as one hexadecimal digit always corresponds to a 4 bit nibble. Here's a quick table.
Image may be NSFW.
Clik here to view.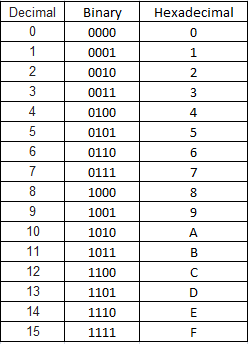
So 2C (hexadecimal) = (2 X 16) + (12 X 1) = 48(decimal) and 0010 1100(binary)
I understand that many may know this already, but I want to make sure new programmers will be able to understand.
The UTF-8 Format
In UTF-8, the high-order bits in binary are important. UTF-8 works by using the leading high-order bits of the first byte to tell how many bytes were used to encode the value. For 8 bit encoding from 0 to 127, the high-order bit will always be zero. Because of this, if the high-order bit is zero, the byte will always be treated as a single byte encoding. Therefore, all single byte encodings have the following form: 0XXX XXXX
7 bits are available to code the number. Here is the format for all of the encodings:
Image may be NSFW.
Clik here to view.
Once you know the format of UTF-8, converting back and forth between it is fairly simple. To convert to UTF-8, you can easily see if it will encode to 1, 2, 3, or 4 bytes by checking the numerical range. Then copy the bits to the correct location.
Example Conversion
Let's try an example. I'm going to use hexadecimal value 1FACBD for this example. Now, I don't believe this is a real UNICODE character, but it'll help us see how to encode values. The number is greater than FFFF so it will require a 4-byte encoding. Let's see how it'll work. First, here's the value in binary.
Image may be NSFW.
Clik here to view.
This will be a 4-byte encoding so we'll need to use the following format.
Image may be NSFW.
Clik here to view.
Now converting to UTF-8 is as simple as copying the bits from right to left into the correct positions.
Image may be NSFW.
Clik here to view.
Like I said, UTF-8 is a fairly straight-forward format.
Advantages of UTF-8
If you want to support non-Latin characters, UTF-8 has a lot of advantages. Since it codes characters using one byte chunks and since UTF-8 strings will never contain a "null" byte, you can use UTF-8 strings with most traditional null-terminated string processing functions. More and more things are being encoded in UTF-8, especially things that are sent over the Internet. Many web pages are coded in UTF-8, and UTF-8 is often used with XML and JSON. Supporting UTF-8 will allow developers to retrieve text data from other sources without conversions. UTF-8 is also byte oriented and as long as it is read one byte at a time, you don't have to worry about endianess.
Conclusion
Now it's not difficult converting back and forth between UTF-8. As a programmer who wants to use UNICODE, you have to decided whether or not it would it be better to continue to store things as wide character string, using UTF-8 only to store things in files or to use UTF-8 all of the time. If you want to support non-Latin characters, UTF-8 has a lot of advantages. Unless you need to do a lot of string manipulation, you can keep your strings in UTF-8 until you need to display them. Typical string operations like concatenation, copying, and finding sub-strings can be done directly in UTF-8. If you want to parse through all of the characters to show them in a GUI for example, you can create an iterator to go through each character. (Comment From Aressera). Using UTF-8 in code is not difficult to implement and if you're wondering how to add support for non-Latin characters, it's worth considering.
Additional References
ASCII Wiki - http://en.wikipedia.org/wiki/ASCII
UTF-8 Encoding - http://www.fileformat.info/info/unicode/utf8.htm
UTF-8 Wiki - http://en.wikipedia.org/wiki/UTF-8
Article Update Log
4 Aug 2013: Initial Draft
6 Aug 2013: Updated Introductions and Conclusions
This article was originally posted on the Squared'D Blog