This post originally available on my devblog.
Did you know computers are stupid machines? They are actually so stupid that they don't know how to multiply; instead, they add - whenever you say 2*5, the computer is really doing 2+2+2+2+2!
What computers can, and have always been capable of, is executing things incredibly quickly. So even if it uses repeated addition, it adds so quickly that you don't even feel it adds repeatedly, it just spits out the answer as if it used its memory like you would have.
However, fast as computers are, sometimes you need it to be faster, and that's what we're going to tackle in this article.
But first, let's consider this:
Here are 7 doors, and behind them are numbers, one of which contains a 36. If I asked you to find it, how would you do it?
Well, what we'd do is open the doors, and hope we're lucky to get the number.
Here we open 4 doors, and find 36. Of course, in the worst case scenario, if we were unlucky, we might have ended up opening all 7 doors before finally finding 36.
Now suppose I give you a clue. This time, I tell you the numbers are sorted, from lowest to highest. You can instantly see that we can work on opening the doors more systematically:
If we open the door in the middle, we know which half the number we are looking for is. In this case we see 24, and we can then tell that 36 should be in the latter half.
We can take the concept even further, and - quite literally - divide our problem in half:
In the picture above, instead of worrying about 6 more doors, we now only worry about 3.
We again open the middle, and find 36 in it.
In the worst case scenario, if we opened the doors wildly, or linearly, opening doors one by one without a care, we would have to open all doors to find what we are looking for.
In our new systematized approach, we would have to open a significantly lower number of doors - even in the worst case scenario. This approach is logarithmic in running time, because we always divide our number of doors by half.
Here is a graph of the doors we have to open, relative to the number of doors.
See how much faster log n is, even on incredibly large input. On the worst case scenario, if we had 1000 doors and we opened them linearly, we would have to open all of them. If we leverage the fact that the numbers are sorted however, we could continually divide the problem in half, and drastically lowering that number.
An Algorithm is a step-by-step procedure for solving a problem, and here we have two basic algorithms.
As you have already seen, our second algorithm is faster than our first in the worst case scenario. We could classify them by running time, the time it needs to take to complete the problem, which we equated here by the numbers of doors opened (since you take time to open doors).
The first algorithm, which is a linear search algorithm, would have to open ALL doors, so we say it's running time is O(n), (pronounced Big-Oh-of-n) where n is the number of doors (input).
The second algorithm, which is a binary search algorithm, would have to open a logarithmic amount of doors, so we say it's running time is O(log n).
In the so called O-Notation, O represents the time needed for your algorithm to complete the task in the worst case scenario.
We haven't looked at the other side of the coin however. What about the best case scenario?
In both of our algorithms, the best case scenario would be to find the what we're looking for in the very first door of course! So, in both our cases, the best case running time would be 1. In O-Notation, theta (O) represents the best case scenario. So in notation, we say O(1)
Here is a table so far of our algorithms:
Now unless all you're going to write in your life are door problems the style of Monty Hall, then we need to study more interesting algorithms.
Let's say I'm making an RTS, and I needed to sort out units by their health.
As you can see here, the positions of our units are a mess!
A human being can sort this out very easily - one can instantly 'see' that it should be arranged like so:
The brain makes some pretty interesting calculations, and in a snap, it sees how the problem can be solved, as if in one step.
In reality though, it actually does a series of steps, an algorithm, to sort out these pigs. Let's try to solve this problem programmatically.
One very straight forward way to solve this problem is to walk through our input, and if they are not sorted, we swap them:
Are the first two pigs sorted? Yes, so we leave them be.
Are the next two pigs sorted?
No, so we swap them.
We will continually do this recursively, until we walk through our input and see that we have in fact sorted it out.
To save you some bandwidth, here is our sorting algorithm in an animation, courtesy of Wikipedia:
(The animation is pretty long, so you might want to refresh the page to start over)
The algorithm we have described here is a Bubble Sort. Let's define its running time shall we?
How many steps do we take to fully sort it out?
First we walk through our input. If our input is n, that is a total of n steps.
But how many times do we start over and walk again? Well, in the worst case scenario, that is, when the numbers are arranged largest to lowest, then we would have to walk through it n times too.
So n steps per walk, and n walks, then that is a total of n2.
In the best case scenario, we would only need to walk through it once (and see it's already sorted). In that case, n steps per walk, and 1 walk, then that is a total of n.
Now you might have noticed this, but n2 is a pretty bad number to have. If we had to sort 100 elements, then that means we have to take 1002 steps, that is 10,000 steps for a 100 elements!
Let's use another approach. This time, we walk through the input left to right, keeping track of the smallest number we find.
After each walkthrough, we swap the smallest number with the left-most one that is not in the correct place yet.
To again save you some bandwidth, here is an animation, again courtesy of Wikipedia:
The red item is the current lowest number that we save, presumably in a variable. After the walk, we put this lowest number to the top of the list, and we know that this is sorted already (yellow).
But what is the running time?
In the worst case scenario, we would have to do n walks. The steps per walk decreases. Since we know that the first few numbers are already sorted, we can skip it. So our walks then become n, n-1, n-2... and so on.
The total running time of this is (n(n-1))/2. However, computers are so fast that a division is negligible, so we can say that this is n2 still.
But what about the best case scenario? If you think about it, we would still need to walk through the input, even if it is already arranged! So our best case scenario is also n2.
Okay, so all of our examples so far have been n2 which we know is bad. Let's take a look at another algorithm shall we?
Imagine you're sorting a deck of cards. Now I don't know about you, but what most would do is walk through the deck, and insert the card in front of them to its right position in another deck.
This might help you visualize it:
This is awesome! We only need to walk through the list once! So the running time is n right?
Not quite. What if we needed to insert 1 to our sorted list? We would have to move every single one of them to make room. If you consider this, the worst case running time is actually n2.
Let's table them shall we:
Are we screwed? Do we have no choice but n2 running time for sorts? Of course not! If you've been vigilant, you'll realize that none of the algorithms introduced so far uses the same 'divide-and-conquer' approach of binary search.
You might want to take a look at this visualization to see just how fast merge sort is to bubble, selection, and insertion sorts.
Note: That little tidbit about computers doing repeated addition is a bit of a lie.
Credits
- Running Time Graph Image taken from: CS50, taught by David J. Malan from Harvard University
- Visualization Animations from Wikipedia.
Did you know computers are stupid machines? They are actually so stupid that they don't know how to multiply; instead, they add - whenever you say 2*5, the computer is really doing 2+2+2+2+2!
What computers can, and have always been capable of, is executing things incredibly quickly. So even if it uses repeated addition, it adds so quickly that you don't even feel it adds repeatedly, it just spits out the answer as if it used its memory like you would have.
However, fast as computers are, sometimes you need it to be faster, and that's what we're going to tackle in this article.
But first, let's consider this:

Here are 7 doors, and behind them are numbers, one of which contains a 36. If I asked you to find it, how would you do it?
Well, what we'd do is open the doors, and hope we're lucky to get the number.

Here we open 4 doors, and find 36. Of course, in the worst case scenario, if we were unlucky, we might have ended up opening all 7 doors before finally finding 36.
Now suppose I give you a clue. This time, I tell you the numbers are sorted, from lowest to highest. You can instantly see that we can work on opening the doors more systematically:

If we open the door in the middle, we know which half the number we are looking for is. In this case we see 24, and we can then tell that 36 should be in the latter half.
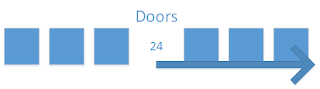
We can take the concept even further, and - quite literally - divide our problem in half:
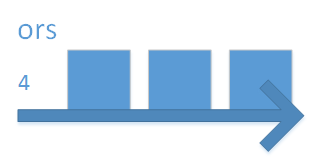
In the picture above, instead of worrying about 6 more doors, we now only worry about 3.
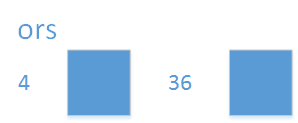
We again open the middle, and find 36 in it.
In the worst case scenario, if we opened the doors wildly, or linearly, opening doors one by one without a care, we would have to open all doors to find what we are looking for.
In our new systematized approach, we would have to open a significantly lower number of doors - even in the worst case scenario. This approach is logarithmic in running time, because we always divide our number of doors by half.
Here is a graph of the doors we have to open, relative to the number of doors.

See how much faster log n is, even on incredibly large input. On the worst case scenario, if we had 1000 doors and we opened them linearly, we would have to open all of them. If we leverage the fact that the numbers are sorted however, we could continually divide the problem in half, and drastically lowering that number.
An Algorithm is a step-by-step procedure for solving a problem, and here we have two basic algorithms.
As you have already seen, our second algorithm is faster than our first in the worst case scenario. We could classify them by running time, the time it needs to take to complete the problem, which we equated here by the numbers of doors opened (since you take time to open doors).
The first algorithm, which is a linear search algorithm, would have to open ALL doors, so we say it's running time is O(n), (pronounced Big-Oh-of-n) where n is the number of doors (input).
The second algorithm, which is a binary search algorithm, would have to open a logarithmic amount of doors, so we say it's running time is O(log n).
In the so called O-Notation, O represents the time needed for your algorithm to complete the task in the worst case scenario.
We haven't looked at the other side of the coin however. What about the best case scenario?
In both of our algorithms, the best case scenario would be to find the what we're looking for in the very first door of course! So, in both our cases, the best case running time would be 1. In O-Notation, theta (O) represents the best case scenario. So in notation, we say O(1)
Here is a table so far of our algorithms:
| Ω | O | |
| Linear Search | 1 | n |
| Binary Search | 1 | log n |
Now unless all you're going to write in your life are door problems the style of Monty Hall, then we need to study more interesting algorithms.
Sorting - Case Study
Let's say I'm making an RTS, and I needed to sort out units by their health.

As you can see here, the positions of our units are a mess!
A human being can sort this out very easily - one can instantly 'see' that it should be arranged like so:

The brain makes some pretty interesting calculations, and in a snap, it sees how the problem can be solved, as if in one step.
In reality though, it actually does a series of steps, an algorithm, to sort out these pigs. Let's try to solve this problem programmatically.
One very straight forward way to solve this problem is to walk through our input, and if they are not sorted, we swap them:

Are the first two pigs sorted? Yes, so we leave them be.

Are the next two pigs sorted?
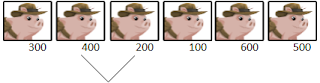
No, so we swap them.

We will continually do this recursively, until we walk through our input and see that we have in fact sorted it out.
To save you some bandwidth, here is our sorting algorithm in an animation, courtesy of Wikipedia:

(The animation is pretty long, so you might want to refresh the page to start over)
The algorithm we have described here is a Bubble Sort. Let's define its running time shall we?
How many steps do we take to fully sort it out?
First we walk through our input. If our input is n, that is a total of n steps.
But how many times do we start over and walk again? Well, in the worst case scenario, that is, when the numbers are arranged largest to lowest, then we would have to walk through it n times too.
So n steps per walk, and n walks, then that is a total of n2.
In the best case scenario, we would only need to walk through it once (and see it's already sorted). In that case, n steps per walk, and 1 walk, then that is a total of n.
Now you might have noticed this, but n2 is a pretty bad number to have. If we had to sort 100 elements, then that means we have to take 1002 steps, that is 10,000 steps for a 100 elements!
Selection Sort
Let's use another approach. This time, we walk through the input left to right, keeping track of the smallest number we find.
After each walkthrough, we swap the smallest number with the left-most one that is not in the correct place yet.
To again save you some bandwidth, here is an animation, again courtesy of Wikipedia:

The red item is the current lowest number that we save, presumably in a variable. After the walk, we put this lowest number to the top of the list, and we know that this is sorted already (yellow).
But what is the running time?
In the worst case scenario, we would have to do n walks. The steps per walk decreases. Since we know that the first few numbers are already sorted, we can skip it. So our walks then become n, n-1, n-2... and so on.
The total running time of this is (n(n-1))/2. However, computers are so fast that a division is negligible, so we can say that this is n2 still.
But what about the best case scenario? If you think about it, we would still need to walk through the input, even if it is already arranged! So our best case scenario is also n2.
Insertion sort
Okay, so all of our examples so far have been n2 which we know is bad. Let's take a look at another algorithm shall we?
Imagine you're sorting a deck of cards. Now I don't know about you, but what most would do is walk through the deck, and insert the card in front of them to its right position in another deck.
This might help you visualize it:

This is awesome! We only need to walk through the list once! So the running time is n right?
Not quite. What if we needed to insert 1 to our sorted list? We would have to move every single one of them to make room. If you consider this, the worst case running time is actually n2.
Let's table them shall we:
| Ω | O | |
| Bubble Sort | n | n2 |
| Selection Sort | n2 | n2 |
| Insertion Sort | n | n2 |
Are we screwed? Do we have no choice but n2 running time for sorts? Of course not! If you've been vigilant, you'll realize that none of the algorithms introduced so far uses the same 'divide-and-conquer' approach of binary search.
You might want to take a look at this visualization to see just how fast merge sort is to bubble, selection, and insertion sorts.
Note: That little tidbit about computers doing repeated addition is a bit of a lie.
Credits
- Running Time Graph Image taken from: CS50, taught by David J. Malan from Harvard University
- Visualization Animations from Wikipedia.