Abstract
About a year ago we published in our blog a series of articles on development of Visual Studio plugins in C#. We have recently revised those materials and added new sections and now invite you to have a look at the updated version of the manual.
Creating extension packages (plug-ins) for Microsoft Visual Studio IDE appears as quite an easy task at the first sight. There exist an excellent MSDN documentation, as well as various articles, examples and a lot of other additional sources on this topic. But, at the same time, it could also appear as a difficult task when an unexpected behavior is encountered along the way. Although it can be said that such issues are quite common to any programming task, the subject of IDE plug-in development is still not thoroughly covered at this moment.
We develop
PVS-Studio static code analyzer. Although the tool itself is intended for C++ developers, quite a large fragment of it is written in C#. When we just had been starting the development of our plug-in, Visual Studio 2005 had been considered as modern state-of-the-art IDE. Although, at this moment of Visual Studio 2012 release, some could say that Visual Studio 2005 is not relevant anymore, we still provide support for this version in our tool. During our time supporting various Visual Studio versions and exploring capabilities of the environment, we've accumulated a large practical experience on how to correctly (and even more so incorrectly!) develop IDE plug-ins. As holding all of this knowledge inside us was becoming unbearable, we've decided to publish it here. Some of our solutions that seem quite obvious right now were discovered in the course of several years. And the same issues could still haunt other plug-in developers.
The following topics will be covered:
- basic information on creating and debugging MSVS plug-ins and maintaining these extensibility projects for several versions of Visual Studio inside a common source code base;
- overview of Automation Object Model and various Managed Package Framework (MPF) classes
- extending interface of the IDE though the automation object model's API (EnvDTE) and MPF (Managed Package Framework) classes with custom menus, toolbars, windows and options pages;
- overview of Visual Studio project model; Atmel Studio IDE, which is based on Visual Studio Isolated Shell, as an example of interaction with custom third-party project models.
- utilizing Visual C++ project model for gathering data needed to operate an external preprocessor/compiler, such as compilation arguments and settings for different platforms and configurations;
A list of more detailed in-depth references for the article covered here are available at the end of each topic through the links to MSDN library and several other external resources.
The articles will cover the extension development only for Visual Studio 2005 and later versions. This limitation reflects that PVS-Studio also supports integration to Visual Studio starting only from version 8 (Visual Studio 2005). The main reason behind this is that a new extensibility API model was introduced for Visual Studio 2005, and this new version is not backward-compatible with previous IDE extensibility APIs.
Creating, debugging and deploying extension packages for Microsoft Visual Studio 2005/2008/2010/2012
This item contains the overview of several different methods for extending Visual Studio IDE functionality. The creation, debugging, registration and end-user deployment of Visual Studio extension packages will be explained in detail.
Creating and debugging Visual Studio and Visual Studio Isolated Shell VSPackage extension modules
There exists a number of ways to extend Microsoft Visual Studio features. On the most basic level it's possible to automate simple routine user actions using macros. An add-In plug-in module can be used for obtaining an access to environment's UI objects, such as menu commands, windows etc. Extension of IDE's internal editors is possible through MEF (Managed Extensibility Framework) components (starting with MSVS 2010). Finally, a plug-in of the
Extension Package type (known as VSPackage) is best suited for integrating large independent components into Visual Studio. VSPackage allows combining the environment automation through
Automation Object Model with usage of
Managed Package Framework classes (such as Package). In fact, while Visual Studio itself provides only the basic interface components and services, such standard modules as Visual C++ or Visual C# are themselves implemented as IDE extesnions.
In its earlier versions, PVS-Studio plug-in (versions 1.xx and 2.xx to be precise, when it was still known as Viva64) existed as an Add-In package. Starting with PVS-Studio 3.0 it was redesigned as VSPackage because the functionality Add-in was able to provide became insufficient for the tasks at hand and also the debugging process was quite inconvenient. After all, we wanted to have our own logo on Visual Studio splash screen!
VSPackage also provides the means of extending the automation model itself by registering user-defined custom automation objects within it. Such user automation objects will become available through the same automation model to other user-created extensibility packages, providing these packages with access to your custom components. This, in turn, allows third-party developers to add the support of new programming languages and compilers through such extensions into the IDE and also to provide interfaces for the automation of these new components as well.
Besides extending the Visual Studio environment itself, VSPackage extensions could be utilized for addition of new features into Visual Studio Isolated\Integrated shells. Isolated\integrated shell provides any third-party developer with the ability to re-use basic interface components and services of Visual Studio (such as a code editor, autocompletion system etc.), but also to implement the support of other custom project models and\or compilers. Such a distribution will not include any of Microsoft proprietary language modules (such as Visual C++, Visual Basic and so on), and it could be installed by an end-user even if his or her system does not contain a previous Visual Studio installation.
An isolated shell application will remain a separate entity after the installation even if the system contains a previous Visual Studio installation, but an integrated shell application will be merged into the preinstalled version. In case the developer of isolated\integrated shell extends the Visual Studio automation model by adding interfaces to his or her custom components, all other developers of VSPackage extensions will be able to add such components as well. Atmel Studio, an IDE designed for the development of embedded systems, is an example of Visual Studio Isolated Shell application. Atmel Studio utilizes its own custom project model which, in turn, itself is the implementation of a standard Visual Studio project model for the MSBuild, and the specific version of the gcc compiler.
Projects for VSPackage plug-in modules. Creating the extension package. Let's examine the creation of Visual Studio Package plug-in (VSPackage extension). Contrary to Add-In plug-ins, developing VS extension packages requires the installation of Microsoft Visual Studio SDK for a targeted version of IDE, i.e. a separate SDK should be installed with every version of Visual Studio for which an extension is being developed. In case of the extension that targets Visual Studio Isolated\Integrated Shell, an SDK for the version of Visual Studio on which such a shell is based will be required.
We will be examining extension development for the 2005, 2008, 2009 and 2012 versions of Visual Studio and Visual Studio 2010 based Isolated Shells. Installation of Visual Studio SDK adds a standard project template for Visual Studio Package (on the 'Other Project Types -> Extensibility' page) to VS template manager. If selected, this template will generate a basic MSBuild project for an extension package, allowing several parameters to be specified beforehand, such as a programming language to be used and the automatic generation of several stub components for generic UI elements, such as menu item, an editor, user tool window etc.
We will be using a C# VSPackage project (csproj), which is a project for managed dynamic-link library (DLL). The corresponding csproj MSBuild project for this managed assembly will also contain several XML nodes specific to a Visual Studio package, such as VSCT compiler and IncludeinVSIX (in later IDE versions).
The main class of an extension package should be inherited from the
Microsoft.VisualStudio.Shell.Package. This base class provides managed wrappers for IDE interaction APIs, implementation of which is required from a fully-functional Visual Studio extension package
public sealed class MyPackage: Package
{
public MyPackage ()
{}
...
}The
Package class allows overriding of its base
Initialize method. This method receives execution control at the moment of package initialization in the current session of IDE.
protected override void Initialize()
{
base.Initialize();
...
}
The initialization of the module will occur when it is invoked for the first time, but it also could be triggered automatically, for example after IDE is started or when user enters a predefined environment UI context state.
Being aware of the package's initialization and shutdown timings is crucial. It's quite possible that the developer would be requesting some of Visual Studio functionality at the moment when it is still unavailable to the package. During PVS-Studio development we've encountered several such situations when the environment "punished us" for not understanding this, for instance, we are not allowed to "straightforwardly" display message boxes after Visual Studio enters a shutdown process.
Debugging extension packages. Experimental Instance. The task of debugging a plug-in module or extension intended for an integrated development environment is not quite a trivial one. Quite often such environment itself is utilized for plug-in's development and debugging. Hooking up an unstable module to this IDE can lead to instability of the environment itself. The necessity to uninstall a module under development from the IDE before every debugging session, which in turn often requires restarting it, is also a major inconvenience (IDE could block the DLL that needs to be replaced by a newer version for debugging).
It should be noted that a VSPackage debugging process in this aspect is substantially easier than that of an Add-In package. This was one of the reasons for changing the project type of PVS-Studio plug-in.
VSPackage solves the aforementioned development and debugging issues by utilizing Visual Studio Experimental Instance mechanism. Such an experimental instance could be easily started by passing a special command line argument:
"C:\Program Files (x86)\Microsoft Visual Studio 10.0\
Common7\IDE\devenv.exe" /RootSuffix Exp
An experimental instance of the environment utilizes a separate independent Windows registry hive (called experimental hive) for storing all of its settings and component registration data. As such, any modifications in the IDE's settings or changes in its component registration data, which were made inside the experimental hive, will not affect the instance which is employed for the development of the module (that is your main regular instance which is used by default).
Visual Studio SDK provides a special tool for creating or resetting such experimental instances —
CreateExpInstance. To create a new experimental hive, it should be executed with these arguments:
CreateExpInstance.exe /Reset /VSInstance=10.0 /RootSuffix=PVSExp
Executing this command will create a new experimental registry hive with a PVSExp suffix in its name for the 10th version of IDE (Visual Studio 2010), also resetting all of its settings to their default values in advance. The registry path for this new instance will look as follows:
HKEY_CURRENT_USER\Software\Microsoft\VisualStudio\10.0PVSExp
While the Exp suffix is utilized by default for package debugging inside VSPackage template project, other experimental hives with unique names could also be created by the developer at will. To start an instance of the environment for the hive we've created earlier (containing PVSExp in its name), these arguments should be used:
"C:\Program Files (x86)\Microsoft Visual Studio 10.0\
Common7\IDE\devenv.exe" /RootSuffix PVSExp
A capacity for creating several different experimental hives on a single local workstation could be quite useful, as, for example, to provide a simultaneous and isolated development of several extension packages.
After installing the SDK package, a link is created in the Visual Studio program's menu group for resetting the default Experimental Instance for this version of the IDE (for instance, "Reset the Microsoft Visual Studio 2010 Experimental Instance").
In case of extension targeting an Isolated Shell, the issues with the "corruption" of the development environment are irrelevant, and so there is no need for Experimental Instance utilization. But, in any case, the faster you'll figure out how the debugging environment works, the fewer issues you'll encounter in understanding how plug-in initialization works during development.
Registering and deploying Visual Studio extension packages
Registering a VS extension package requires registering a package itself, as well as registering all of the components it integrates into the IDE (for example, menu items, option pages, user windows etc.). The registration is accomplished by creating records corresponding to these components inside the main system registry hive of Visual Studio.
All the information required for registration is placed, after building your VSPackage, inside a special pkgdef file, according to several special attributes of the main class of your package (which itself should be a subclass of the MPF
Package class). The pkgdef can also be created manually using the
CreatePkgDef. This tool collects all of the required module registration information from these special attributes by the means of .NET reflection. Let's study these registration attributes in detail.
The
PackageRegistration attribute tells the registration tool that this class is indeed a Visual Studio extension package. Only if this attribute is discovered will the tool perform its search for additional ones.
[PackageRegistration(UseManagedResourcesOnly = true)]
The
Guid attribute specifies a unique package module identifier, which will be used for creating a registry sub-key for this module in Visual Studio hive.
[Guid("a0fcf0f3-577e-4c47-9847-5f152c16c02c")]The
InstalledProductRegistration attribute adds information to 'Visual Studio Help -> About' dialog and the loading splash screen.
[InstalledProductRegistration("#110", "#112", "1.0",
IconResourceID = 400)]The
ProvideAutoLoad attribute links automatic module initialization with the activation of a specified environment UI context. When a user enters this context, the package will be automatically loaded and initialized. This is an example of setting module initialization to the opening of a solution file:
[ProvideAutoLoad("D2567162-F94F-4091-8798-A096E61B8B50")]The GUID values for different IDE UI contexts can be found in the
Microsoft.VisualStudio.VSConstants.UICONTEXT class.
The
ProvideMenuResource attribute specifies an ID of resource that contains user created menus and commands for their registration inside IDE.
[ProvideMenuResource("Menus.ctmenu", 1)]The
DefaultRegistryRoot attribute specifies a path to be used for writing registration data to the system registry. Starting with Visual Studio 2010 this attribute can be dropped as the corresponding data will be present in manifest file of a VSIX container. An example of registering a package for Visual Studio 2008:
[DefaultRegistryRoot("Software\\Microsoft\\VisualStudio\\9.0")]Registration of user-created components, such as toolwidows, editors, option pages etc. also requires the inclusion of their corresponding attributes for the user's
Package subclass. We will examine these attributes separately when we will be examining corresponding components individually.
It's also possible to write any user-defined registry keys (and values to already existing keys) during package registration through custom user registration attributes. Such attributes can be created by inheriting the
RegistrationAttribute abstract class.
[AttributeUsage(AttributeTargets.Class, Inherited = true,
AllowMultiple = false)]
public class CustomRegistrationAttribute : RegistrationAttribute
{
}The
RegistrationAttribute-derived attribute must override its
Register and
Unregister methods, which are used to modify registration information in the system registry.
The
RegPkg tool can be used for writing registration data to Windows registry. It will add all of the keys from pkgdef file passed to it into the registry hive specified by the /root argument. For instance, the RegPkg is utilized by default in Visual Studio VSPackage project template for registering the module in the Visual Studio experimental hive, providing convenient seamless debugging of the package being developed. After all of the registration information have been added to the registry, Visual Studio (devenv.exe) should be started with '/setup' switch to complete registration for new components inside the IDE.
Deploying plug-ins for developers and end-users. Package Load Key. Before proceeding to describe the deployment process itself, one particular rule should be stressed:
Each time after a new version of the distribution containing your plug-in is created, this new distribution should be tested on a system without Visual Studio SDK installed, as to make sure that it will be registered correctly on the end-user system.Today, as the releases of early versions of PVS-Studio are past us, we do not experience these kinds of issues, but several of these early first versions were prone to them.
Deploying a package for Visual Studio 2005/2008 will require launching of regpkg tool for a pkgdef file and passing the path to Visual Studio main registry hive into it. Alternately, all keys from a pkgdef can be written to Windows registry manually. Here is the example of automatically writing all the registration data from a pkgdef file by regpkg tool (in a single line):
RegPkg.exe /root:Software\Microsoft\VisualStudio\9.0Exp
"/pkgdeffile:obj\Debug\PVS-Studio-vs2008.pkgdef"
"C:\MyPackage\MyPackage.dll"
After adding the registration information to the system registry, it is necessary to start Visual Studio with a /setup switch to complete the component registration. It is usually the last step in the installation procedure of a new plug-in.
Devenv.exe /setup
Starting the environment with this switch instructs Visual Studio to absorb resource metadata for user-created components from all available extension packages, so that these components will be correctly displayed by IDE's interface. Starting devenv with this key will not open its main GUI window.
We do not employ RepPkg utility as part of PVS-Studio deployment, instead manually writing required data to the registry by using our stand-alone installer. We chose this method because we have no desire of being dependent on some external third-party tools and we want full control over the installation process. Still, we do use RegPkg during plug-in development for convenient debugging.
VSIX packages Beginning from Visual Studio 2010, VSPackage deployment process can be significantly simplified through the usage of
VSIX packages. VSIX package itself is a common (Open Packaging Conventions) archive containing plug-in's binary files and all of the other auxiliary files which are necessary for plug-in's deployment. By passing such archive to the standard VSIXInstaller.exe utility, its contents will be automatically registered in the IDE:
VSIXInstaller.exe MyPackage.vsix
VSIX installer could also be used with /uninstall switch to remove the previously installed package from a system. A unique GUID of the extension package should be used to identify such package:
VSIXInstaller.exe /uninstall: 009084B1-6271-4621-A893-6D72F2B67A4D
Contents of a VSIX container are defined through the special vsixmanifest file, which should be added to plug-in's project. Vsixmanifest file permits the following properties to be defined for an extension:
- targeted Visual Studio versions and editions, which will be supported by the plug-in;
- a unique GUID identifier;
- a list of components to be registered (VSPackage, MEF components, toolbox control etc.);
- general information about the plug-in to be installed (description, license, version, etc.);
To include additional files into a VSIX container, the IncludeInVSIX node should be added to their declarations inside your MSBuild project (alternately, they could also be marked as included into VSIX from their respective property windows, by opening it from Visual Studio Solution Explorer).
<Content Include="MyPackage.pdb">
<IncludeInVSIX>true</IncludeInVSIX>
</Content>
In fact, the VSIX file could be viewed as an almost full-fledged installer for extension packages on the latest versions of Visual Studio (2010 and 2012), allowing the extensions to be deployed by a "one-click" method. Publishing your VSIX container in the official
Visual Studio Gallery for extensions allows end-users to install such packages through the Tools -> Extension Manager IDE dialog.
VSIX allows the extension to be deployed either for one of the regular Visual Studio editions, or for the isolated\integrated shell based distributions. In case of developing an extension for isolated shell application, instead of the Visual Studio version the VSIX manifest file should contain a special identification string for the targeted environment. For example, the identification string for Atmel Studio 6.1 should be "AtmelStudio, 6.1". But, if the extension you are developing utilizes only common automation model interfaces (such as the ones for the text editor, abstract project tree and so on), and does not require any of the specific ones (for example, interfaces for Visual C++ projects), then it is possible for you to specify several different editions of Visual Studio, as well as an isolated shell based ones, in the manifest file. This, in turn, will permit you to use a single installer for a wide range of Visual Studio based applications.
This new VSIX installation procedure in Visual Studio 2010 does substantially alleviate package deployment for end-users (as well as for developers themselves). Some developers even had decided to support only VS2010 IDE and versions above it, if only not to get involved with the development of a package and installer for earlier IDE versions.
Unfortunately, several issues can be encountered when using VSIX installer together with Visual Studio 2010 extension manager interface. For instance, sometimes the extension's binary files are not removed correctly after uninstall, which in turn blocks the VSIX installer from installing/reinstalling the same extension. As such, we advise you not to depend upon the VSIX installer entirely and to provide some backup, for example by directly removing your files from a previous plug-in installation before proceeding with a new one.
Package Load Key Each VSPackage module loaded into Visual Studio must possess a unique Package Load Key (PLK). PLK key is specified through the
ProvideLoadKey attribute for the
Package subclass in 2005/2008 versions of the IDE.
[ProvideLoadKey("Standard", "9.99", "MyPackage", "My Company", 100)]Starting with Visual Studio 2010, the presence of a PLK, as well as of the
ProvideLoadKey attribute respectively, in a package is not required, but it can still be specified in case the module under development is targeting several versions of MSVS. The PLK can be obtained by registering at the
Visual Studio Industry Partner portal, meaning it guarantees that the development environment can load only packages certified by Microsoft.
However, systems containing Visual Studio SDK installed are exceptions to this, as Developer License Key is installed together with the SDK. It allows the corresponding IDE to load any extension package, regardless of validity of its PLK.
Considering the aforementioned, one more time it is necessary to stress the importance of testing the distribution on a system without Visual Studio SDK present, because the extension package will operate properly on developer's workstation regardless of its PLK correctness.
Extension registration specifics in the context of supporting several different versions of Visual Studio IDE By default, VSPackage project template will generate an extensibility project for the version of Visual Studio that is used for the development. This is not a mandatory requirement though, so it is possible to develop an extension for a particular version of IDE using a different one. It also should be noted that after automatically upgrading a project file to a newer version through devenv /Upgrade switch, the targeted version of the IDE and its corresponding managed API libraries will remain unchanged, i.e. from a previous version of Visual Studio.
To change the target of the extension to another version of Visual Studio (or to register an extension into this version to be more precise), you should alter values passed to the
DefaultRegistryRoot attribute (only for 2005/2008 IDE versions, as starting from Visual Studio 2010 this attribute is no longer required) or change the target version in the VSIX manifest file (for versions above 2008).
VSIX support appears only starting from Visual Studio 2010, so building and debugging the plug-in targeted for the earlier IDE version from within Visual Studio 2010 (and later) requires setting up all the aforementioned registration steps manually, without VSIX manifest. While changing target IDE version one should also not forget to switch referenced managed assemblies, which contain COM interface wrappers utilized by the plug-in, to the corresponding versions as well.
Altering the IDE target version of the plug-in affects the following Package subclass attributes:
- the InstalledProductRegistration attribute does not support overloading of its constructor with a (Boolean, String, String, String) signature, starting from Visual Studio 2010;
- the presence of DefaultRegistryRoot and ProvideLoadKey attributes is not mandatory starting from Visual Studio 2010, as similar values are now specified inside VSIX manifest;
References
- MSDN. Experimental Build.
- MSDN. How to: Register a VSPackage.
- MSDN. VSIX Deployment.
- MSDN. How to: Obtain a PLK for a VSPackage.
- MZ-Tools. Resources about Visual Studio .NET extensibility.
- MSDN. Creating Add-ins and Wizards.
- MSDN. Using a Custom Registration Attribute to Register an Extension.
- MSDN. Shell (Integrated or Isolated).
Visual Studio Automation Object Model. EnvDTE and Visual Studio Shell Interop interfaces.
This item contains an overview of Visual Studio Automation Object Model. Model's overall structure and the means of obtaining access to its interfaces through DTE/DTE2 top level objects are examined. Several examples of utilizing elements of the model are provided. Also discussed are the issues of using model's interfaces within multithreaded applications; an example of implementing such mechanism for multithreaded interaction with COM interfaces in managed code is provided as well.
Introduction
Visual Studio development environment is built upon the principles of automation and extensibility, providing the developers using it with the ability of integrating almost any custom element into the IDE and allowing for an easy interaction with its default and user-created components. As the means of implementing these tasks, Visual Studio users are provided with several cross-complementing toolsets, the most basic and versatile among these is the Visual Studio Automation Object Model.
Automation Object Model is represented by a series of libraries containing a vast and well-structured API set which covers all aspects of IDE automation and the majority of its extensibility capabilities. Although, in comparison to other IDE extensibility tools, this model does not provide access to some portions of Visual Studio (this applies mostly to the extension of some IDE's features), it is nonetheless the most flexible and versatile among them.
The majority of the model's interfaces are accessible from within every type of IDE extension module, which allows interacting with the environment even from an external independent process. Moreover, the model itself could be extended along with the extension of Visual Studio IDE, providing other third-party developers with an access to user-created custom components.
Automation Object Model structure
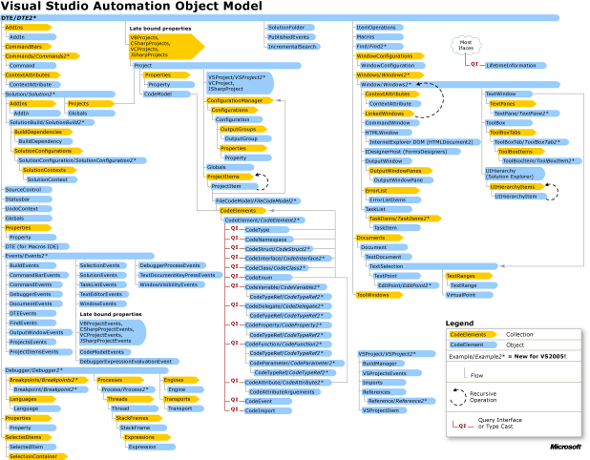
Visual Studio automation model is composed of several interconnected functional object groups covering all aspects of the development environment; it also provides capabilities for controlling and extending these groups. Accessing any of them is possible through the top-level global DTE interface (Development Tools Environment). Figure 1 shows the overall structure of the automation model and how it is divided among functionality groups.
![image1.png]()
Figure 1 — Visual Studio Automation Object Model (click the picture to zoom in)
The model itself could be extended by user in one of the following groups:
- project models (implementing new project types, support for new languages);
- document models (implementing new document types and document editors)
- code editor level models (support for specific language constructs)
- project build-level models
Automation model could be extended from plug-ins of VSPackage type only.
All of the automation model's interfaces could be conventionally subdivided into two large groups. 1st group are the interfaces of the EnvDTE and Visual Studio Interop namespaces, these interfaces allow interactions with basic common components of the IDE itself, such as tool windows, editors, event handling services and so on. 2nd group are the interfaces of the specific project model. The figure above specifies this interface group as late-bound properties, i.e. these interfaces are implemented in a separate dynamically loaded library. Each standard (i.e. the one that is included in a regular Visual Studio distribution) project model, such as Visual C++ or Visual Basic, provides a separate implementation for these interfaces. Third-party developers are able to extend the automation model by adding their own custom project models and by providing an implementation of these automation interfaces.
Also worth noting is that the interfaces of the 1st group, which was specified above, are universal, meaning that they could be utilized for interaction with any of the project models or Visual Studio editions, including the integrated\isolated Visual Studio shells. In this article we will examine this group in more detail.
But still, despite the model's versatility, not every group belonging to the model could be equally utilized from all the types of IDE extensions. For instance, some of the model's capabilities are inaccessible to external processes; these capabilities are tied to specific extension types, such as Add-In or VSPackage. Therefore, when selecting the type for the extension to be developed, it is important to consider the functionality that this extension will require.
The
Microsoft.VisualStudio.Shell.Interop namespace also provides a group of COM interfaces, which can be used to extend and automate Visual Studio application from managed code. Managed Package Framework (MPF) classes, which we utilized earlier for creating a VSPackage plugin, are actually themselves based on these interfaces. Although theses interfaces are not a part of EnvDTE automation model described above, nevertheless they greatly enhance this model by providing additional functionality for VSPackage extensions, which is otherwise unavailable for extensions of other types.
Obtaining references to DTE/DTE2 objects.
In order to create a Visual Studio automation application it is necessary to obtain access to the automation objects themselves in the first place. To accomplish this, first of all it is necessary to hook up the correct versions of libraries containing the required managed API wrappers in the EnvDTE namespace. Secondly, the reference to the automation model top-level object, that is the DTE2 interface, should be obtained.
In the course of Visual Studio evolution, several of its automation objects had been modified or received some additional functionality. So, to maintain a backward compatibility with existing extension packages, new EnvDTE80, EnvDTE90, EnvDTE100 etc. namespaces were created instead of updating the interfaces from the original EnvDTE namespace. The majority of such updated interfaces from these new namespaces do maintain the same names as in the original ones, but with addition of an ordinal number at the end of the name, for example Solution and Solution2. It is advised that these updated interfaces should be utilized when creating a new project, as they do contain the most recent functionality. It's worth noting that properties and methods of DTE2 interface usually return object references with types corresponding to the original DTE, i.e. accessing
dte2.Solution will return Solution and not the Solution2 as it would seem.
Although these new EnvDTE80, EnvDTE90, EnvDTE100 namespaces do contain some of the updated functionality as mentioned above, still it is the EnvDTE interface that contains the majority of automation objects. Therefore, in order to possess access to all of the existing interfaces, it is necessary to link all versions of the managed COM wrapper libraries to the project, as well as to obtain the references to DTE and also to DTE2.
The way of obtaining top-level EnvDTE object reference is dependent upon the type of IDE extension being developed. Let's examine 3 of such extension types: Add-In, VSPackage and an MSVS-independent external process.
Add-In extension In the case of an Add-In extension, access to the DTE interface can be obtained inside the
OnConnection method which should be implemented for the
IDTExtensibility interface that provides access to the extension-environment interaction events. The
OnConnection method is called at the moment when the module is loaded by the IDE; it can happen either when the environment is being loaded itself or after the extension was called for the first time in the IDE session. The example of obtaining the reference follows:
public void OnConnection(object application,
ext_ConnectMode connectMode, object addInInst, ref Array custom)
{
_dte2 = (DTE2)application;
...
}An Add-In module can be initialized either at the moment of IDE start-up, or when it is called for the first time in current IDE session. So, the
connectMode can be used to correctly determine the moment of initialization inside the
OnConnection method.
switch(connectMode)
{
case ext_ConnectMode.ext_cm_UISetup:
...
break;
case ext_ConnectMode.ext_cm_Startup:
...
break;
case ext_ConnectMode.ext_cm_AfterStartup:
...
break;
case ext_ConnectMode.ext_cm_CommandLine:
...
break;
}As in the example above, Add-In could be loaded either simultaneously with the IDE itself (if the startup option in the Add-In manager is checked), when it is called the first time or when it is called through the command line. The
ext_ConnectMode.ext_cm_UISetup option is invoked only for a single time in the plug-in's overall lifetime, which is during its first initialization. This case should be used for initializing user UI elements which are to be integrated into the environment (more on this later on).
If an Add-In is being loaded during Visual Studio start-up (
ext_ConnectMode.ext_cm_Startup), then at the moment
OnConnect method receives control for the first time, it is possible that the IDE still is not fully initialized itself. In such a case, it is advised to postpone the acquisition of the DTE reference until the environment is fully loaded. The
OnStartupComplete handler provided by the
IDTExtensibility can be used for this.
public void OnStartupComplete(ref Array custom)
{
...
} VSPackage extension For VSPackage type of extension, the DTE could be obtained through the global Visual Studio service with the help of
GetService method of a
Package subclass:
DTE dte = MyPackage.GetService(typeof(DTE)) as DTE;
Please note that the
GetService method could potentially return null in case Visual Studio is not fully loaded or initialized at the moment of such access, i.e. it is in the so called "zombie" state. To correctly handle this situation, it is advised that the acquisition of DTE reference should be postponed until this interface is inquired. But in case the DTE reference is required inside the
Initialize method itself, the
IVsShellPropertyEvents interface can be utilized (also by deriving our
Package subclass from it) and then the reference could be safely obtained inside the
OnShellPropertyChange handler.
DTE dte;
uint cookie;
protected override void Initialize()
{
base.Initialize();
IVsShell shellService = GetService(typeof(SVsShell)) as IVsShell;
if (shellService != null)
ErrorHandler.ThrowOnFailure(
shellService.AdviseShellPropertyChanges(this,out cookie));
...
}
public int OnShellPropertyChange(int propid, object var)
{
// when zombie state changes to false, finish package initialization
if ((int)__VSSPROPID.VSSPROPID_Zombie == propid)
{
if ((bool)var == false)
{
this.dte = GetService(typeof(SDTE)) as DTE;
IVsShell shellService = GetService(typeof(SVsShell)) as IVsShell;
if (shellService != null)
ErrorHandler.ThrowOnFailure(
shellService.UnadviseShellPropertyChanges(this.cookie) );
this.cookie = 0;
}
}
return VSConstants.S_OK;
}It should be noted that the process of VSPackage module initialization at IDE startup could vary for different Visual Studio versions. For instance, in case of VS2005 and VS2008, an attempt at accessing DTE during IDE startup will almost always result in null being returned, owning to the relative fast loading times of these versions. But, one does not simply obtain access into DTE. In Visual Studio 2010 case, it mistakenly appears that one could simply obtain an access to the DTE from inside the
Initialize() method. In fact, this impression is a false one, as such method of DTE acquisition could potentially cause the occasional appearance of "floating" errors which are hard to identify and debug, and even the DTE itself may be still uninitialized when the reference is acquired. Because of these disparities, the aforementioned acquisition method for handling IDE loading states should not be ignored on any version of Visual Studio.
Independent external process The DTE interface is a top-level abstraction for Visual Studio environment in the automation model. In order to acquire a reference to this interface from an external application, its ProgID COM identifier could be utilized; for instance, it will be "VisualStudio.DTE.10.0" for Visual Studio 2010. Consider this example of initializing a new IDE instance and when obtaining a reference to the DTE interface.
// Get the ProgID for DTE 8.0.
System.Type t = System.Type.GetTypeFromProgID(
"VisualStudio.DTE.10.0", true);
// Create a new instance of the IDE.
object obj = System.Activator.CreateInstance(t, true);
// Cast the instance to DTE2 and assign to variable dte.
EnvDTE80.DTE2 dte = (EnvDTE80.DTE2)obj;
// Show IDE Main Window
dte.MainWindow.Activate();In the example above we've actually created a new DTE object, starting deven.exe process by the
CreateInstance method. But at the same time, the GUI window of the environment will be displayed only after the
Activate method is called.
Next, let's review a simple example of obtaining the DTE reference from an already running Visual Studio Instance:
EnvDTE80.DTE2 dte2;
dte2 = (EnvDTE80.DTE2)
System.Runtime.InteropServices.Marshal.GetActiveObject(
"VisualStudio.DTE.10.0");However, in case several instances of the Visual Studio are executing at the moment of our inquiry, the
GetActiveObject method will return a reference to the IDE instance that was started the earliest. Let's examine a possible way of obtaining the reference to DTE from a running Visual Studio instance by the PID of its process.
using EnvDTE80;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Runtime.InteropServices.ComTypes;
[DllImport("ole32.dll")]
private static extern void CreateBindCtx(int reserved,
out IBindCtx ppbc);
[DllImport("ole32.dll")]
private static extern void GetRunningObjectTable(int reserved,
out IRunningObjectTable prot);
public static DTE2 GetByID(int ID)
{
//rot entry for visual studio running under current process.
string rotEntry = String.Format("!VisualStudio.DTE.10.0:{0}", ID);
IRunningObjectTable rot;
GetRunningObjectTable(0, out rot);
IEnumMoniker enumMoniker;
rot.EnumRunning(out enumMoniker);
enumMoniker.Reset();
IntPtr fetched = IntPtr.Zero;
IMoniker[] moniker = new IMoniker[1];
while (enumMoniker.Next(1, moniker, fetched) == 0)
{
IBindCtx bindCtx;
CreateBindCtx(0, out bindCtx);
string displayName;
moniker[0].GetDisplayName(bindCtx, null, out displayName);
if (displayName == rotEntry)
{
object comObject;
rot.GetObject(moniker[0], out comObject);
return (EnvDTE80.DTE2)comObject;
}
}
return null;
}Here we've acquired the DTE interface by identifying the required instance of the IDE in the table of running COM objects (ROT, Running Object Table) by its process identifier. Now we can access the DTE for all of the executing instances of Visual Studio, for example:
Process Devenv;
...
//Get DTE by Process ID
EnvDTE80.DTE2 dte2 = GetByID(Devenv.Id);
Additionally, to acquire any project-specific interface (including custom model extensions), for example the CSharpProjects model, through a valid DTE interface, the
GetObject method should be utilized:
Projects projects = (Projects)dte.GetObject("CSharpProjects");The
GetObject method will return a
Projects collection of regular
Project objects, and each one of them will contain a reference to our project-specific properties, among other regular ones.
Visual Studio text editor documents
Automation model represents Visual Studio text documents through the
TextDocument interface. For example, C/C++ source code files are opened by the environment as text documents. TextDocument is based upon the common automation model document interface (the
Document interface), which represents file of any type opened in Visual Studio editor or designer. A reference to the text document object can be obtained through the
Object field of the Document object. Let's acquire a text document for the currently active (i.e. the one possessing focus) document from IDE's text editor.
EnvDTE.TextDocument objTextDoc =
(TextDocument)PVSStudio.DTE.ActiveDocument.Object("TextDocument"); Modifying documents The
TextSelection document allows controlling text selection or to modify it. The methods of this interface represent the functionality of Visual Studio text editor, i.e. they allow the interaction with the text as it presented directly by the UI.
EnvDTE.TextDocument Doc =
(TextDocument)PVSStudio.DTE.ActiveDocument.Object(string.Empty);
Doc.Selection.SelectLine();
TextSelection Sel = Doc.Selection;
int CurLine = Sel.TopPoint.Line;
String Text = Sel.Text;
Sel.Insert("test\r\n");
In this example we selected a text line under the cursor, read the selected text and replaced it with a 'test' string.
TextDocument interface also allows text modification through the
EditPoint interface. This interface is somewhat similar to the TextSelection, but instead of operating with the text through the editor UI, it directly manipulates text buffer data. The difference between them is that the text buffer is not influenced by such editor-specific notions as WordWrap and Virtual Spaces. It should be noted that both of these editing methods are not able to modify read-only text blocks.
Let's examine the example of modifying text with EditPoint by placing additional lines at the end of current line with a cursor.
objEditPt = objTextDoc.StartPoint.CreateEditPoint();
int lineNumber = objTextDoc.Selection.CurrentLine;
objEditPt.LineDown(lineNumber - 1);
EditPoint objEditPt2 = objTextDoc.StartPoint.CreateEditPoint();
objEditPt2.LineDown(lineNumber - 1);
objEditPt2.CharRight(objEditPt2.LineLength);
String line = objEditPt.GetText(objEditPt.LineLength);
String newLine = line + "test";
objEditPt.ReplaceText(objEditPt2, newLine,
(int)vsEPReplaceTextOptions.vsEPReplaceTextKeepMarkers);
Navigating the documents VSPackage modules are able to obtain access to a series of global services which could be used for opening and handling environment documents. These services could be acquired by the
Package.GetGlobalService() method from Managed Package Framework. It should be noted that the services described here are not part of the EnvDTE model and are accessible only from a Package-type extension, and therefore they could not be utilized in other types of Visual Studio extensions. Nonetheless, they can be quite useful for handling IDE documents when they are utilized in addition to the Documents interface described earlier. Next, we'll examine these services in more detail.
The
IVsUIShellOpenDocument interface controls the state of documents opened in the environment. Following is the example that uses this interface to open a document through path to a file which this document will represent.
String path = "C:\Test\test.cpp";
IVsUIShellOpenDocument openDoc =
Package.GetGlobalService(typeof(IVsUIShellOpenDocument))
as IVsUIShellOpenDocument;
IVsWindowFrame frame;
Microsoft.VisualStudio.OLE.Interop.IServiceProvider sp;
IVsUIHierarchy hier;
uint itemid;
Guid logicalView = VSConstants.LOGVIEWID_Code;
if (ErrorHandler.Failed(
openDoc.OpenDocumentViaProject(path, ref logicalView, out sp,
out hier, out itemid, out frame))
|| frame == null)
{
return;
}
object docData;
frame.GetProperty((int)__VSFPROPID.VSFPROPID_DocData, out docData);
The file will be opened in a new editor or will receive focus in case it already has been opened earlier. Next, let's read a
VsTextBuffer text buffer from this document we opened:
// Get the VsTextBuffer
VsTextBuffer buffer = docData as VsTextBuffer;
if (buffer == null)
{
IVsTextBufferProvider bufferProvider = docData as
IVsTextBufferProvider;
if (bufferProvider != null)
{
IVsTextLines lines;
ErrorHandler.ThrowOnFailure(bufferProvider.GetTextBuffer(
out lines));
buffer = lines as VsTextBuffer;
Debug.Assert(buffer != null,
"IVsTextLines does not implement IVsTextBuffer");
if (buffer == null)
{
return;
}
}
}
The
IVsTextManager interface controls all of the active text buffers in the environment. For example we can navigate a text document using the
NavigateToLineAndColumn method of this manager on a buffer we've acquired earlier:
IVsTextManager mgr = Package.GetGlobalService(typeof(VsTextManagerClass))
as IVsTextManager;
mgr.NavigateToLineAndColumn(buffer, ref logicalView, line,
column, line, column);
Subscribing and handling events
Automation objects events are represented by the
DTE.Events property. This element references all of the common IDE events (such as CommandEvents, SolutionEvents), as well as the events of separate environment components (project types, editors, tools etc.), also including the ones designed by third-party developers. To acquire a reference for this automation object, the
GetObject method could be utilized.
When subscribing to the DTE events one should remember that this interface could be still unavailable at the moment of extension being initialized. So it is always important to consider the sequence of your extension initialization process if the access to DTE.Events is required in the
Initialize() method of your extension package. The correct handling of initialization sequence will vary for different extension types, as it was described earlier.
Let's acquire a reference for an events object of Visual C++ project model defined by the
VCProjectEngineEvents interface and assign a handler for the removal of an element from the Solution Explorer tree:
VCProjectEngineEvents m_ProjectItemsEvents =
PVSStudio.DTE.Events.GetObject("VCProjectEngineEventsObject")
as VCProjectEngineEvents;
m_ProjectItemsEvents.ItemRemoved +=
new _dispVCProjectEngineEvents_ItemRemovedEventHandler(
m_ProjectItemsEvents_ItemRemoved); MDI windows events The
Events.WindowEvents property could be utilized to handle regular events of an environment MDI window. This interface permits the assignment of a separate handler for a single window (defined through the
EnvDTE.Window interface) or the assignment of a common handler for all of the environment's windows. Following example contains the assignment of a handler for the event of switching between IDE windows:
WindowEvents WE = PVSStudio.DTE.Events.WindowEvents;
WE.WindowActivated +=
new _dispWindowEvents_WindowActivatedEventHandler(
Package.WE_WindowActivated);Next example is the assignment of a handler for window switching to the currently active MDI window through
WindowEvents indexer:
WindowEvents WE = m_dte.Events.WindowEvents[MyPackage.DTE.ActiveWindow];
WE.WindowActivated += new
_dispWindowEvents_WindowActivatedEventHandler(
MyPackage.WE_WindowActivated);IDE commands eventsThe actual handling of environment's commands and their extension through the automation model is covered in a separate article of this series. In this section we will examine the handling of the events related to these commands (and not of the execution of the commands themselves). Assigning the handlers to these events is possible through the
Events.CommandEvents interface. The
CommandEvents property, as in the case of MDI windows events, also permits the assignment of a handler either for all of the commands or for a single one through the indexer.
Let's examine the assignment of a handler for the event of a command execution being complete (i.e. when the command finishes its execution):
CommandEvents CEvents = DTE.Events.CommandEvents;
CEvents.AfterExecute += new
_dispCommandEvents_AfterExecuteEventHandler(C_AfterExecute);
But in order to assign such a handler for an individual command, it is necessary to identify this command in the first place. Each command of the environment is identified by a pair of GUID:ID, and in case of a user-created commands these values are specified directly by the developer during their integration, for example through the VSCT table. Visual Studio possesses a special debug mode which allows identifying any of the environment's commands. To activate this mode, it is required that the following key is to be added to the system registry (an example for Visual Studio 2010):
[HKEY_CURRENT_USER\Software\Microsoft\VisualStudio\10.0\General]
"EnableVSIPLogging"=dword:00000001
Now, after restarting the IDE, hovering your mouse over menu or toolbar elements with CTRL+SHIFT being simultaneously pressed (though sometime it will not work until you left-click it) will display a dialog window containing all of the command's internal identifiers. We are interested in the values of
Guid and
CmdID. Let's examine the handling of events for the
File.NewFile command:
CommandEvents CEvents = DTE.Events.CommandEvents[
"{5EFC7975-14BC-11CF-9B2B-00AA00573819}", 221];
CEvents.AfterExecute += new
_dispCommandEvents_AfterExecuteEventHandler(C_AfterExecute);The handler obtained in this way will receive control only after the command execution is finished.
void C_AfterExecute(string Guid, int ID, object CustomIn,
object CustomOut)
{
...
}This handler should not be confused with an immediate handler for the execution of the command itself which could be assigned during this command's initialization (from an extension package and in case the command is user-created). Handling the IDE commands is described in a separate article that is entirely devoted to IDE commands.
In conclusion to this section it should be mentioned that in the process of developing our own VSPackage extension, we've encountered the necessity to store the references to interface objects containing our handler delegates (such as CommandEvents, WindowEvents etc.) on the top-level fields of our main
Package subclass. The reason for this is that in case of the handler being assigned through a function-level local variable, it is lost immediately after leaving the method. Such behavior could probably be attributed to the .NET garbage collector, although we've obtained these references from the DTE interface which definitely exists during the entire lifetime of our extension package.
Handling project and solution events (for VSPackage extensions)
Let's examine some of the interfaces from the
Microsoft.VisualStudio.Shell.Interop namespace, the ones that permit us to handle the events related to Visual Studio projects and solution to be more precise. Although these interfaces are not a part of EnvDTE automation model, they could be implemented by the main class of VSPackage extension (that is the class that was inherited from
Package base class of Managed Package Framework). That is why, if you are developing the extension of this type, these interfaces a conveniently supplement the basic set of interfaces provided by the DTE object. By the way, this is another argument for creating a full-fledged VSPackage plugin using MPF.
The
IVsSolutionEvents could be implemented by the class inherited from
Package and it is available starting from Visual Studio version 2005, and the isolated\integrated shells based applications. This interface permits you to track the loading, unloading, opening and closing of projects or even the whole solutions in the development environment by implementing such of its methods as
OnAfterCloseSolution,
OnBeforeCloseProject,
OnQueryCloseSolution. For example:
public int OnAfterLoadProject(IVsHierarchy pStubHierarchy, IVsHierarchy pRealHierarchy)
{
//your custom handler code
return VSConstants.S_OK;
}As you can see, this method takes the
IVsHierarchy object as an input parameter which represents the loading project. Managing of such objects will be examined in another article devoted to the interaction with Visual Studio project model.
The
IVsSolutionLoadEvents interface, in a similar fashion to the interface described above, should be implemented by the
Package subclass and is available to versions of Visual Studio starting from 2010 and above. This interface allows you to handle such interesting aspects as batch loading of project groups and background solution loadings (the
OnBeforeLoadProjectBatch and
OnBeforeBackgroundSolutionLoadBegins methods), and also to intercept the end of this background loading operation as well (the
OnAfterBackgroundSolutionLoadComplete method).
Such event handlers should come in handy in case your plug-in needs to execute some code immediately after its initialization, and, at the same time, the plug-in depends on projects\solutions that are loaded inside the IDE. In this a case, executing such a code without waiting for the solution loading to be finished could lead to either incorrect (incomplete) results because of the incompletely formed projects tree, or even to runtime exceptions.
While developing PVS-Studio IDE plug-in, we've encountered another interesting aspect of VSPackage plug-in initialization. Then one Package plug-in enters a waiting state (for instance, by displaying a dialog window to the user), further initialization of VSPackage extensions is suspended until the blocking plug-in returns. So, when handling loading and initialization inside the environment, one should always remember this possible scenario as well.
And finally, I want to return one final time to the fact, that for the interface methods described above to operate correctly, you should inherit your main class from theses interfaces:
class MyPackage: Package, IVsSolutionLoadEvents, IVsSolutionEvents
{
//Implementation of Package, IVsSolutionLoadEvents, IVsSolutionEvents
...
}Supporting Visual Studio color schemes
If the extension you are developing will be integrated into the interface of the development environment, for instance, by creating custom tool windows or document MDI windows (and the most convenient way for such an integration is a VSPackage extesnion), it is advisable that the coloring of your custom UI components should match the common color scheme used by Visual Studio itself.
The importance of this task was elevated with the release of Visual Studio 2012, containing two hugely opposite color themes (Dark and Light) which the user could switch "on the fly" from the IDE options window.
The
GetVSSysColorEx method from Visual Studio Interop interface
IVsUIShell2 could be utilized to obtain environment's color settings. This interface is available to VSPackage plugins only.
IVsUIShell2 vsshell = this.GetService(typeof(SVsUIShell)) as IVsUIShell2;
By passing the the
__VSSYSCOLOREX and
__VSSYSCOLOREX3 enums to the
GetVSSysColorEx method, you can get the currently selected color for any of Visual Studio UI elements. For example, let's obtain one of the colors from the context menu's background gradient:
uint Win32Color;
vsshell.GetVSSysColorEx((int)__VSSYSCOLOREX3.VSCOLOR_COMMANDBAR_MENU_BACKGROUND_GRADIENTBEGIN, out Win32Color);
Color BackgroundGradient1 = ColorTranslator.FromWin32((int)Win32Color);
Now we can use this
Color object to "paint" our custom context menus. To determine the point in time at which the color theme of your components should be reapplied, you can, for example, utilize events of the environment command responsible for opening of IDE's settings window (Tools -> Options). How to subscribe your handlers to such an event was described earlier in this article.
But if you are, for some reason, unable to utilize the IVsUIShell2 object (for instance, in case you are developing a non-VSPackage extension), but at the same time you still need to support Visual Studio color themes, then it is possible to obtain color values for environment's various UI components directly from the system registry. We will not cover this approach in the article, but
here you can download a free and open-source tool designed for Visual Studio color theme editing. The tool is written in C# and it contains all the code required for reading and modifying Visual Studio 2012 color themes from the managed code.
Interacting with COM interfaces from within a multithreaded application
Initially PVS-Studio extension package had not contained any specific thread-safety mechanisms for its interaction with Visual Studio APIs. At the same time, we had been attempting to confine the interactions with this APIs within a single background thread which was created and owned by our plug-in. And such approach functioned flawlessly for quite a long period. However, several bug reports from our users, each one containing a similar
ComExeption error, prompted us to examine this issue in more detail and to implement a threading safety mechanism for our COM Interop.
Although Visual Studio automation model is not a thread-safe one, it still provides a way for interacting with multi-threaded applications. Visual Studio application is a COM (Component Object Mode) server. For the task of handling calls from COM clients (in our case, this will be our extension package) to thread-unsafe servers, COM provides a mechanism known as STA (Single-Threaded Apartment) model. In the terms of COM, an Apartment represents a logical container inside a process in which objects and threads share the same thread access rules. STA can hold only a single thread, but an unlimited number of objects, inside such container. Calls from other threads to such thread-unsafe objects inside STA are converted into messages and posted to a message queue. Messages are retrieved from the message queue and converted back into method calls one at a time by the thread running in the STA, so it becomes possible for only a single thread to access these unsafe objects on the server.
Utilizing Apartment mechanism inside managed code The .NET Framework does not utilize COM Apartment mechanics directly. Therefore, when a managed application calls a COM object in the COM interoperation scenarios, CLR (Common Language Runtime) creates and initializes Apartment container. A managed thread is able to create and enter either an MTA (Multi-Threaded Apartment, a container that, contrary to STA, can host several threads at the same time), or an STA, though a thread will be started as an MTA by default. The type of the Apartment could be specified before thread is launched:
Thread t = new Thread(ThreadProc);
t.SetApartmentState(ApartmentState.STA);
...
t.Start();
As an Apartment type could not be changed once thread had been started, the
STAThread attribute should be used to specify the main thread of a managed application as an STA:
[STAThread]
static void Main(string[] args)
{...} Implementing message filter for COM interoperation errors in a managed environment As STA serializes all of calls to the COM server, one of the calling clients could potentially be blocked or even rejected when the server is busy, processing different calls or another thread is already inside the apartment container. In case COM server rejects its client, .NET COM interop will generate a
System.Runtime.InteropServices.COMException ("The message filter indicated that the application is busy").
When working on a Visual Studio module (add-in, vspackage) or a macro, the execution control usually passes into the module from the environment's main STA UI thread (such as in case of handling events or environment state changes, etc.). Calling automation COM interfaces from this main IDE thread is safe. But if other background threads are planned to be utilized and EnvDTE COM interfaces are to be called from these background threads (as in case of long calculations that could potentially hang the IDE's interface, if these are performed on the main UI thread), then it is advised to implement a mechanism for handling calls rejected by a server.
While working on PVS-Studio plug-in we've often encountered these kinds of COM exceptions in situations when other third-party extensions were active inside the IDE simultaneously with PVS-Studio plug-in. Heavy user interaction with the UI also was the usual cause for such issues. It is quite logical that these situations often resulted in simultaneous parallel calls to COM objects inside STA and consequently to the rejection of some of them.
To selectively handle incoming and outgoing calls, COM provides the IMessageFilter interface. If it is implemented by the server, all of the calls are passed to the
HandleIncomingCall method, and the client is informed on the rejected calls through the
RetryRejectedCall method. This in turn allows the rejected calls to be repeated, or at least to correctly present this rejection to a user (for example, by displaying a dialog with a 'server is busy' message). Following is the example of implementing the rejected call handling for a managed application.
[ComImport()]
[Guid("00000016-0000-0000-C000-000000000046")]
[InterfaceType(ComInterfaceType.InterfaceIsIUnknown)]
public interface IMessageFilter
{
[PreserveSig]
int HandleInComingCall(
int dwCallType,
IntPtr hTaskCaller,
int dwTickCount,
IntPtr lpInterfaceInfo);
[PreserveSig]
int RetryRejectedCall(
IntPtr hTaskCallee,
int dwTickCount,
int dwRejectType);
[PreserveSig]
int MessagePending(
IntPtr hTaskCallee,
int dwTickCount,
int dwPendingType);
}
class MessageFilter : MarshalByRefObject, IDisposable, IMessageFilter
{
[DllImport("ole32.dll")]
[PreserveSig]
private static extern int CoRegisterMessageFilter(
IMessageFilter lpMessageFilter,
out IMessageFilter lplpMessageFilter);
private IMessageFilter oldFilter;
private const int SERVERCALL_ISHANDLED = 0;
private const int PENDINGMSG_WAITNOPROCESS = 2;
private const int SERVERCALL_RETRYLATER = 2;
public MessageFilter()
{
//Starting IMessageFilter for COM objects
int hr =
MessageFilter.CoRegisterMessageFilter(
(IMessageFilter)this,
out this.oldFilter);
System.Diagnostics.Debug.Assert(hr >= 0,
"Registering COM IMessageFilter failed!");
}
public void Dispose()
{
//disabling IMessageFilter
IMessageFilter dummy;
int hr = MessageFilter.CoRegisterMessageFilter(this.oldFilter,
out dummy);
System.Diagnostics.Debug.Assert(hr >= 0,
"De-Registering COM IMessageFilter failed!")
System.GC.SuppressFinalize(this);
}
int IMessageFilter.HandleInComingCall(int dwCallType,
IntPtr threadIdCaller, int dwTickCount, IntPtr lpInterfaceInfo)
{
// Return the ole default (don't let the call through).
return MessageFilter.SERVERCALL_ISHANDLED;
}
int IMessageFilter.RetryRejectedCall(IntPtr threadIDCallee,
int dwTickCount, int dwRejectType)
{
if (dwRejectType == MessageFilter.SERVERCALL_RETRYLATER)
{
// Retry the thread call immediately if return >=0 &
// <100.
return 150; //waiting 150 mseconds until retry
}
// Too busy; cancel call. SERVERCALL_REJECTED
return -1;
//Call was rejected by callee.
//(Exception from HRESULT: 0x80010001 (RPC_E_CALL_REJECTED))
}
int IMessageFilter.MessagePending(
IntPtr threadIDCallee, int dwTickCount, int dwPendingType)
{
// Perform default processing.
return MessageFilter.PENDINGMSG_WAITNOPROCESS;
}
}
Now we can utilize our
MessageFilter while calling COM interfaces from a background thread:
using (new MessageFilter())
{
//COM-interface dependent code
...
}References
- MSDN. Referencing Automation Assemblies and the DTE2 Object.
- MSDN. Functional Automation Groups.
- MZ-Tools. HOWTO: Use correctly the OnConnection method of a Visual Studio add-in.
- The Code Project. Understanding The COM Single-Threaded Apartment.
- MZ-Tools. HOWTO: Add an event handler from a Visual Studio add-in.
- Dr. eX's Blog. Using EnableVSIPLogging to identify menus and commands with VS 2005 + SP1.
Visual Studio commands
This item deals with creation, utilization and handling of Visual Studio commands in its extension modules through automation object model APIs and IDE services. The relations between IDE commands and environment UI elements, such as user menus and toolbars, will also be examined.
Introduction
Visual Studio commands provide a way for direct interaction with development environment through the keyboard input. Almost all capabilities of different dialog and tool windows, toolbars and user menus are represented by the environment's commands. In fact, main menu items and toolbar buttons are practically commands themselves. Although it is possible for a command not to possess a direct representation in the development environment's UI, as commands are not the UI elements per se, they can be represented by such UI elements as menu items and toolbar buttons.
PVS-Studio IDE extension package integrates several subgroups of its commands into Visual Studio main menu, and these commands serve as one of the plug-in's main UI components (with another one being its MDI tool window), allowing a user to control all of the aspects of static code analysis either from the environment's UI or by invoking the commands directly through command line.
Using IDE commands
Any IDE command, regardless of its UI representation in the IDE (or of the lack of it), could be executed directly through the Command or Immediate windows, as well as by starting devenv.exe with the '/command' argument.
The full name of a command is formed according to its affiliation with a functional group, as for example the commands of the 'File' main menu item. Command's full name could be examined in the 'Keyboard, Environment' Options page. Also, the 'Tools -> Customize -> Commands' dialog allows inspecting all of the commands which are currently registered within the environment. This dialog sorts the commands by their respective functional groups and UI presentation types (menus, toolbars), also allowing to modify, add or delete them.
Commands can receive additional arguments which should be separated from the command's name by a space. Let's examine a call to a standard system command of the main menu, 'File -> New -> File' for example, with a passing of additional parameters to it through the Command Window:
>File.NewFile Mytext /t:"General\Text File"
/e:"Source Code (text) Editor"
A command's syntax generally complies with the following rules:
- command's name and arguments are separated by a space
- arguments containing spaces are wrapped by double quotes
- The caret (^) is used as an escape character
- One-character abridgments for command names can be combined, as for example, /case(/c) and /word(/w) could be presented as /cw
When using the 'command' command-line switch, name of a command with all of its arguments should be wrapped by double quotes:
devenv.exe /command "MyGroup.MyCommandName arg1 arg2"
For the sake of convenience, a command could be associated with an alias:
>alias MyAlias File.NewFile MyFile
Commands integrated into IDE by PVS-Studio extension can be utilized through the /command switch as well. For example, this mode could be used for the integration of our static analysis into the automated build process. Our analyzer itself (PVS-Studio.exe) is a native command-line application, which operates quite similar to the compiler, i.e. it takes a path to the file containing source code and its compilation arguments and then it outputs analysis results to
stdout/
stderr streams. It's quite obvious that the analyzer could easily be integrated directly into the build system (for instance, into a system which is based on MSBuild, NMake or even GNU Make) at the same level where C/C++ compiler is being called. Of course, such integration already provides us, by its own definition, with complete enumeration of all of the source files being built, with all of their compilation parameters. In turn, this allows for a substitution (or supplementation) of a compiler call by call to the analyzer. Although the described scenario is fully supported by PVS-Studio.exe analyzer, it still requires a complete understanding of build system's internals as well as an opportunity to modify a system in the first place, which could be problematic or even impossible at times.
Therefore, the integration of the analyzer into the build process can be performed in a more convenient way, on a higher level (i.e. at the level of Continuous Integration Server), by utilizing Visual Studio extension commands through the /command switch, for example, by using the
PVS-Studio.CheckSolution command to perform analysis on MSVS solution. Of course, such use case is only possible when building Visual C++ native project types (vcproj/vcxproj).
In case Visual Studio is started from a command line, the /command switch will be executed immediately after the environment is fully loaded. In this case, the IDE will be started as a regular GUI application, without redirecting its standard I/O streams to the console that was used to launch the environment. It should be noted that, in general, Visual Studio is a UI based development environment and so it is not intended for command line operations. It is recommended to employ Microsoft MSBuild utility for building inside build automation systems, as this tool supports all of native Visual Studio project types.
Caution should be applied when using Visual Studio /command switch together with non-interactive desktop mode (for example when calling IDE from a Windows service). We've encountered several interesting issues ourselves when we were evaluating the possibility of integrating PVS-Studio static analysis into Microsoft Team Foundation build process, as Team Foundation operates as a Windows service by default. At that moment, our plug-in had not been tested for non-interactive desktop sessions and was incorrectly handling its child windows and dialogs, which in turn led to exceptions and crashes. But Visual Studio itself experienced none of such issues, almost none to be more precise. The case is, Visual Studio displays a particular dialog for every user when it is started for a first time after an installation, and this dialog offers the user to select a default UI configuration. And it was this dialog that Visual Studio displayed for a LocalSystem account, the account which actually owns the Team Foundation service. It turns out that the same dialog is 'displayed' even in the non-interactive desktop mode, and it subsequently blocks the execution of the /command switch. As this user doesn't have an interactive desktop, he is also unable to close this dialog normally by manually starting the IDE himself. But, in the end, we were able to close the dialog manually by launching Visual Studio for LocalSystem account in the interactive mode through psexec tool from
PSTools utilities.
Creating and handling commands in VSPackage. Vsct files.
VSPackage extension utilizes Visual Studio command table (*.vsct) file for creating and managing commands that it integrates into the IDE. Command tables are text files in XML format which can be compiled by VSCT compiler into binary CTO files (Command Table Output). CTO files are then included as a resources into final builds of IDE extension packages. With the help of VSCT, commands can be associated with menus or toolbar buttons. Support for VSCT is available starting from Visual Studio 2005. Earlier IDE versions utilized CTC (Command Table Compiler) files handling their commands, but they will not be covered in this article.
In a VSCT file each command is assigned a unique ID — CommandID, a name, a group and a quick access hotkey combination, while its representation in the interface (if any) is specified by special flags.
Let's examine a basic structure of VSCT file. The root element of file is 'CommandTable' node that contains the 'Commands' sub-node, which defines all of the user's commands, groups, menu items, toolbars etc. Value of the "Package" attribute of the "Commands" node must correspond with the ID of your extension. The "Symbols" sub-node should contain definitions for all identifiers used throughout this VSCT file. The 'KeyBindings' sub-node contains default quick access hotkey combinations for the commands.
<CommandTable"http://schemas.microsoft.com/VisualStudio/2005-10-
18/CommandTable">
<Extern href="stdidcmd.h"/>
<Extern href="vsshlids.h"/>
<Commands>
<Groups>
...
</Groups>
<Bitmaps>
...
</Bitmaps>
</Commands>
<Commands package="guidMyPackage">
<Menus>
...
</Menus>
<Buttons>
...
</Buttons>
</Commands>
<KeyBindings>
<KeyBinding guid="guidMyPackage" id="cmdidMyCommand1"
editor="guidVSStd97" key1="221" mod1="Alt" />
</KeyBindings>
<Symbols>
<GuidSymbol name="guidMyPackage" value="{B837A59E-5BF0-4190-B8FC-
FDC35BE5C342}" />
<GuidSymbol name="guidMyPackageCmdSet" value="{CC8B1E36-FE6B-48C1-
B9A9-2CC0EAB4E71F}">
<IDSymbol name="cmdidMyCommand1" value="0x0101" />
</GuidSymbol>
</Symbols>
</CommandTable>The 'Buttons' node defines the commands themselves by specifying their UI representation style and binding them to various command groups.
<Button guid="guidMyPackageCmdSet" id="cmdidMyCommand1"
priority="0x0102" type="Button">
<Parent guid="guidMyPackageCmdSet" id="MyTopLevelMenuGroup" />
<Icon guid="guidMyPackageCmdSet" id="bmpMyCommand1" />
<CommandFlag>Pict</CommandFlag>
<CommandFlag>TextOnly</CommandFlag>
<CommandFlag>IconAndText</CommandFlag>
<CommandFlag>DefaultDisabled</CommandFlag>
<Strings>
<ButtonText>My Command 1</ButtonText>
</Strings>
</Button>The 'Menus' node defines the structure of UI elements (such as menus and toolbars), also binding them to command groups in the 'Groups' node. A group of commands bound with a 'Menu' element will be displayed by the UI as a menu or a toolbar.
<Menu guid=" guidMyPackageCmdSet" id="SubMenu1" priority="0x0000"
type="Menu">
<Parent guid="guidMyPackageCmdSet" id="MyTopLevelMenuGroup"/>
<Strings>
<ButtonText>Sub Menu 1</ButtonText>
</Strings>
</Menu>
<Menu guid=" guidMyPackageCmdSet" id="MyToolBar1" priority="0x0010"
type="Toolbar">
</Menu>And finally, the 'Groups' element organizes user's IDE command groups.
<Group guid="guidMyPackageCmdSet" id="MySubGroup1" priority="0x0020">
<Parent guid="guidMyPackageCmdSet" id="MyGroup1" />
</Group>
To include vsct file into MSBuild-based VSPackage project, it is necessary to insert the following node used for calling VSCT compiler into your csproj project file (note, that in the auto-generated project created from an SDK template, a vsct file will be already included in a project):
<ItemGroup>
<VSCTCompile Include="TopLevelMenu.vsct">
<ResourceName>Menus.ctmenu</ResourceName>
</VSCTCompile>
</ItemGroup>
In order to integrate a user-defined command or command group to one of the standard Visual Studio command groups, it is necessary to specify for your group the identifier of such standard group in the parent node. For example, top integrate your commands to a context menu of a project in the solution explorer window:
<Group guid="guidMyCmdSet" id="ProjectNodeContextMenuGroup" priority="0x07A0">
<Parent guid="guidSHLMainMenu" id="IDM_VS_CTXT_PROJNODE" />
</Group>As you can see, the standard
IDM_VS_CTXT_PROJNODE is being used here. Following
this link, you can discover a list of standard IDs for Visual Studio command groups.
Next, the
ProvideMenuResource attribute of your
Package-derived class should point to this node that you've inserted into your project earlier:
[ProvideMenuResource("Menus.ctmenu", 1)]
...
public sealed class MyPackage : PackageAssigning handlers to the commands defined in a VSCT file is possible through a service that is available through the
IMenuCommandService. A reference for it can be obtained by the
GetService method of your
Package subclass:
OleMenuCommandService MCS = GetService(typeof(IMenuCommandService)) as
OleMenuCommandService;
Let's examine an example in which we assign a handler to a menu command (this command should be declared in a vsct file beforehand):
EventHandler eh = new EventHandler(CMDHandler);
CommandID menuCommandID = new CommandID(guidCommand1CmdSet, id);
//ID and GUID should be the same as in the VCST file
OleMenuCommand menuItem = new OleMenuCommand(eh, menuCommandID);
menuItem.ParametersDescription = "$";
MCS.AddCommand(menuItem);
To obtain command's arguments while handling its invocation, the
EventArgs object should be casted into
OleMenuCmdEventArgs:
void CMDHandler(object sender, EventArgs e)
{
OleMenuCmdEventArgs eventArgs = (OleMenuCmdEventArgs)e;
if (eventArgs.InValue != null)
param = eventArgs.InValue.ToString();
...
} Handling commands through EnvDTE.DTE interfaces.
The
EnvDTE.DTE automation object allows for a direct manipulation (creation, modification and execution) of commands through the
dte.Commands interface and
dte.ExecuteCommand method. Utilizing the Automation Object Model for invoking, modifying and creating IDE commands, as opposed to using VSCT mechanism available only for VSPackage, allows the interaction with IDE commands from within Add-In extension packages as well.
The DTE automation object allows a direct creation, modification and invocation of commands through the
DTE.Commands interface. A command can be directly added to the IDE by
Commands.AddNamedCommand method (but only for an Add-In extension):
dte.Commands.AddNamedCommand(add_in, "MyCommand", "My Command",
"My Tooltip", true);
The command added in this way will be preserved by the IDE — it will reappear in the menu after IDE restart, even if the extension which created the command is not loaded itself. That's why this method should only be utilized during the first initialization of an Add-In module, after its installation (this is described in the section dedicated to Visual Studio Automation Object Model). The
OnConnection method of an Add-In contains a special initialization mode which is invoked only for a single time in the module's entire lifetime. This method can be used to integrate UI elements into the IDE:
public void OnConnection(object application,
ext_ConnectMode connectMode,
object addInInst, ref Array custom)
{
switch(connectMode)
{
case ext_ConnectMode.ext_cm_UISetup:
...
break;
...
}
}The
EnvDTE.Command interface represents a single IDE command. This interface can be used to modify a command which it references. It permits managing IDE commands from either a VSPackage, or an Add-In module. Let's obtain a reference to the
EnvDTE.Command object for our custom command
MyCommand1 and utilize this interface to assign a 'hot-key' to it for a quick access:
EnvDTE.Command MyCommand1 =
MyPackage.DTE.Commands.Item("MyGroup.MyCommand1", -1);
MyCommand1.Bindings = new object[1] { "Global::Alt+1" };The quick-access combination assigned to
MyGroup.MyCommand1 will now be available through 'Keyboard, Environment' environment settings dialog.
As was mentioned before, Visual Studio command is not a UI element by itself. The
Commands.AddCommandBar method allows the creation of such UI elements, as main menu items, toolbars, context menus and the association of these elements with user-created commands.
CommandBar MyToolbar = dte.Commands.AddCommandBar("MyToolbar1",
vsCommandBarType.vsCommandBarTypeToolbar) as CommandBar;
CommandBar MyMenu = dte.Commands.AddCommandBar("MyMenu1",
vsCommandBarType.vsCommandBarTypeMenu) as CommandBar;
CommandBarButton MyButton1 = MyCommand1.AddControl(MyToolbar) as
CommandBarButton;
MyButton1.Caption = "My Command 1";The
Delete method of Command/ CommandBar objects could be utilized to remove a command or toolbar from IDE.
MyCommand1.Delete();
In general, it is not recommended creating commands each time an Add-In plug-in is loaded and removing them each time it is un-loaded, as such behavior could slow down the initialization of IDE itself. Even more, in case the
OnDisconnect method is somehow interrupted in the process, it is possible that the user commands will not be completely deleted from the IDE. That is why it is advised that the integration, and subsequent removal, of IDE commands should be handled at the times of module's installation/uninstallation, as for example, by obtaining DTE interface reference from a stand-alone installer application. The initialization of Add-In modules and acquisition of DTE references is thoroughly described in the article devoted to EnvDTE Automation Object Model.
Any IDE command (either custom or default one) could be called by the
ExecuteCommand method. Here is the example of invoking our custom
MyCommand1 command:
MyPackage.DTE.ExecuteCommand("MyGroup.MyCommand1", args);To handle command execution, an Add-In extension should be derived from the IDTCommandTarget interface and it should also implement the
Exec method:
public void Exec(string commandName,
vsCommandExecOption executeOption, ref object varIn,
ref object varOut, ref bool handled)
{
handled = false;
if(executeOption ==
vsCommandExecOption.vsCommandExecOptionDoDefault)
{
if(commandName == "MyAddin1.Connect.MyCommand1")
{
...
handled = true;
return;
}
}
} References
- MSDN. Visual Studio Commands and Switches.
- MSDN. Visual Studio Command Table (.Vsct) Files.
- MSDN. Designing XML Command Table (.Vsct) Files.
- MSDN. Walkthrough: Adding a Toolbar to the IDE.
- MSDN. How VSPackages Add User Interface Elements to the IDE.
- MZ-Tools. HOWTO: Adding buttons, commandbars and toolbars to Visual Studio .NET from an add-in.
- MSDN. How to: Create Toolbars for Tool Windows.
Visual Studio tool windows
This item covers the extension of Visual Studio IDE through integration of a custom user tool window into the environment. Discussed are the issues of window registration and initialization in VSPackage and Add-In plug-in modules, hosting of user components and handling of window's events and states.
Introduction
Tool windows are child windows of Visual Studio MDI (Multiple Document Interface) and they are responsible for presenting various pieces of information to the user. Solution Explorer and Error List are the examples of tool windows. Usually tool windows' contents are not associated with any files and do not contain any editors, as separate
document windows are reserved for such tasks.
For instance, PVS-Studio extension package integrates several tool windows into the IDE, with Output Window being the primary one. All other of its tool windows can be opened from this main window, as, for example, a search window for the grid. PVS-Studio Output Window itself can be opened from Visual Studio main menu (PVS-Studio -> Show PVS-Studio Output Window), but it also will be invoked automatically each time the analysis starts.
In most cases IDE creates and utilizes just a single instance for each one of its tool windows, and this instance will be preserved until IDE itself needs to shut down. Therefore, pressing the 'close' button on a tool window does actually hide it, and when this window is invoked for the second time, it becomes visible again, thus preserving any data that it contained before being 'closed'. But still, is it possible to crate Multi-Instance tool windows in the IDE, which are the windows that can exist in several instances at once. A tool window can also be associated with a certain UI context (as the so called dynamic window), and such window will be automatically displayed when the user enters this context.
Integration of a tool window into the IDE is supported by VSPackage and Add-In extensions (although the methods for it are different); it requires the specification of the window's initial settings and its registration in the system registry.
Registering and initializing user tool windows
A VSPackage project template that is installed together with Visual Studio SDK allows you to create a sample tool window in the extension project which this template generates. Such a project should already contain all of the basic components which will be described below, so it could be conveniently used as a sample for experimenting with Visual Studio tool window integration process for VSPackage plug-ins.
Registering, initializing and invoking a tool window in VSPackage Registering a custom user window in the environment requires writing of the data that defines this window into a special section of Visual Studio registry hive. This process can be automated by generating a pkgdef file that can contain all of the required window registration information. The contents of this pkgdef file can be specified through special registration attributes of your
Package subclass.
The immediate registration of a user-created tool window into VSPackage extension is handled by
ProvideToolWindowattribute of
Package subclass:
[ProvideToolWindow(typeof(MyWindowPane), Orientation =
ToolWindowOrientation.Right, Style = VsDockStyle.Tabbed, Window =
Microsoft.VisualStudio.Shell.Interop.ToolWindowGuids.Outputwindow,
MultiInstances = false, Transient = true, Width = 500, Height = 250,
PositionX = 300, PositionY = 300)]
Let's examine several parameters of this attribute. The
Typeof parameter points to user implementation of the window's client area (a subclass of
ToolWindowPane). The
MultiInstances parameter enables the Multi-Instance mode for a window, in which multiple instances of the window can be opened simultaneously. The
Orientation,
Size and
Style parameters specify the initial position of a window when it is opened for the first time by the user. It should be noted that the position specified by these parameters will only be used once, when a tool window is displayed for the first time; at all of the subsequent iterations of opening this window, the IDE will be restoring its screen position from the previous one, that is the position before a window was closed. The
Transient parameter indicates whether the window will be automatically opened after Visual Studio environment is loaded in case it already have been opened during the previous session of the IDE.
It should also be remembered that the initialization of a user window by VSPackage (the initialization itself will be covered later) does not necessarily occur at the same moment as the initialization of a
Package subclass for which we provided this registration attribute. For example, after implementing a tool window for PVS-Studio plug-in, we've encountered an issue in which our custom window was automatically opened (but not focused/displayed) and placed among other window tabs at the bottom of the main window, and it was done immediately after Visual Studio started up, even though we've passed the
Transient=true parameter to the
ProvideToolWindow attribute. Although the plug-in itself is always initialized at IDE start-up, the window had not been fully initialized until after a first call to it, which was evident by the corrupted icon on aforementioned tab.
A dynamic visibility context can be specified for a window by the
ProvideToolWindowVisibilityattribute:
[ProvideToolWindowVisibility(typeof(MyWindowPane),
/*UICONTEXT_SolutionExists*/"f1536ef8-92ec-443c-9ed7-fdadf150da82")]
In this example, the window is set to be automatically displayed when the user enters the "Solution Exists" UI context. Take a note that each one of user's tool window requires a separate attribute and a window's type should be passed as a first argument to it.
The
FindToolWindow method of a
Package subclass can be utilized to create and display a tool window from a VSPackage extension. This method returns a reference to the specified tool window object, creating it if necessary (for instance, in case a single-instance window is called for a first time). Following is the example of invoking a single-instance tool window:
private void ShowMyWindow(object sender, EventArgs e)
{
ToolWindowPane MyWindow = this.FindToolWindow(typeof(MyToolWindow),
0, true);
if ((null == MyWindow) || (null == MyWindow.Frame))
{
throw new NotSupportedException(Resources.CanNotCreateWindow);
}
IVsWindowFrame windowFrame = (IVsWindowFrame) MyWindow.Frame;
ErrorHandler.ThrowOnFailure(windowFrame.Show());
}In this example, the window will be created in case it is called for the first time, or the window will be made visible in case it had been created before and then hidden. The
FindToolWindow's third argument of the bool type specifies whether a new instance of a window should be created if the method was unable to find an already existing one.
To create a Multi-Instance tool window, the
CreateToolWindow method can be used. It allows the creation of a window with a pre-defined identifier. An example of invoking such window:
private void CreateMyWindow(object sender, EventArgs e)
{
for (int i = 0; ; i++)
{
// Find existing windows.
var currentWindow =
this.FindToolWindow(typeof(MyToolWindow), i, false);
if (currentWindow == null)
{
// Create the window with the first free ID.
var window =
(ToolWindowPane)this.CreateToolWindow(typeof(MyToolWindow), i);
if ((null == window) || (null == window.Frame))
{
throw new
NotSupportedException(Resources.CanNotCreateWindow);
}
IVsWindowFrame windowFrame = (IVsWindowFrame)window.Frame;
ErrorHandler.ThrowOnFailure(windowFrame.Show());
break;
}
}
}Note that in this example the
FindToolWindow method receives 'false' value as its third argument, i.e. we are searching for an unoccupied index before initializing a new window instance.
As was mentioned above, the environment will preserve position of a window after it is closed. But if, for whatever reason, it is necessary to specify the size and position of a window, it could be achieved through the
SetFramePos method of the
IVsWindowFrame interface:
Guid gd = Guid.Empty;
windowFrame.SetFramePos(VSSETFRAMEPOS.SFP_fDockBottom, ref gd, 20, 20,
200, 200);
A call to the
SetFramePos() should always be made only after the
Show() method is executed.
Creating and invoking a window from Add-In extension A user tool window can be initialized from an Add-In extension with the help of the
EnvDTE Windows2 interface:
public void OnConnection(object application,
ext_ConnectMode connectMode, object addInInst, ref Array custom)
{
_applicationObject = (DTE2)application;
_addInInstance = (AddIn)addInInst;
EnvDTE80.Windows2 window;
AddIn add_in;
object ctlobj = null;
Window myWindow;
// Get the window object
add_in = _applicationObject.AddIns.Item(1);
window = (Windows2)_applicationObject.Windows;
// This section specifies the path and class name of the windows
// control that you want to host in the new tool window, as well as
// its caption and a unique GUID.
string assemblypath = "C:\\MyToolwindow\\MyToolWindowControl.dll";
string classname = " MyToolWindowControl.MyUserControl";
string guidpos = "{E87F0FC8-5330-442C-AF56-4F42B5F1AD11}";
string caption = "My Window";
// Creates the new tool window and inserts the user control into it.
myWindow = window.CreateToolWindow2(add_in, assemblypath,
classname, caption, guidpos, ref ctlobj);
myWindow.Visible = true;
}
In the example above, a user tool window was created using the
MyToolWindowControl.MyUserControl as a client area control. The
MyToolWindowControl.MyUserControl class could either be located in the same assembly as the add-in that initializes it, or it could be provided by a stand-alone assembly with a full COM visibility (though the 'Register for COM Interop' option in project settings). The regular composite
UserControl subclass could be utilized as
MyUserControl.
Implementing a user toolwindow in a VSPackage module
Tool window consists of a frame border and a client area. A frame is provided by the environment and is responsible for performing docking with other interface objects of the environment, as well as for size and position of the window itself. A client area is a pane, controlled by a user, which houses the contents of a window. Tool windows can host user-created WinForms and WPF components and are capable of handling regular events, such as
OnShow,
OnMove, etc.
A user tool window, or its client area to be more precise, can be implemented by inheriting the class representing a standard empty IDE window —
ToolWindowPane[Guid("870ab1d8-b434-4e86-a479-e49b3c6797f0")]
public class MyToolWindow : ToolWindowPane
{
public MyToolWindow():base(null)
{
this.Caption = Resources.ToolWindowTitle;
this.BitmapResourceID = 301;
this.BitmapIndex = 1;
...
}
}The
Guid attribute is used to uniquely identify each custom user window. In case a plug-in module creates several windows of different types, each one of them should be identified by its own unique
Guid. A
ToolWIndowPane subclass can be subsequently modified and host user-controlled components.
Hosting user components A base
ToolWindowPane class implements an empty tool window of the environment. Inheriting from this class allows hosting user-created WinForms or WPF components.
Up until Visual Studio 2008 version, tool windows only provided a native support for WinForms user components, although it still was possible to host WPF components through the WPF Interoperability ElementHost object. Starting from Visual Studio 2010, tool windows themselves are based on WPF technology, although they still provide a backward compatibility for hosting of WinForms components.
To host a user-created WinForms component inside a user tool window, the
Window property of the
ToolWindowPane base class should be overridden:
public MyUserControl control;
public MyToolWindow():base(null)
{
this.Caption = Resources.ToolWindowTitle;
this.BitmapResourceID = 301;
this.BitmapIndex = 1;
this.control = new MyUserControl();
}
public override IWin32Window Window
{
get { return (IWin32Window)control; }
}In the example above, the
MyUserControl object is a regular composite component of the
System.Windows.Forms.UserControl type and it can host any other user component inside itself.
UserControl can also host WPF components by using WPF
ElementHost object.
Starting from Visual Studio 2010, WPF components can be hosted by tool windows natively. To do this, a reference to the WPF component should be passed to the
Content property of a base class:
public MyToolWindow():base(null)
{
this.Caption = Resources.ToolWindowTitle;
this.BitmapResourceID = 301;
this.BitmapIndex = 1;
base.Content = new MyWPFUserControl();
}Please note that using the two methods described above simultaneously is not possible. When a reference to WPF component is assigned to the
base.Content property, an overridden
Window property is ignored.
The main PVS-Studio 'Output' window of our extension plug-in hosts a virtual grid based on
SourceGrid open-source project. This window provides an interface for handling the results of static analysis. The grid itself is bound to a regular ADO.NET table of the
System.Data.Datatable type, which is utilized for storing analysis results. Until 4.00 version of PVS-Studio extension, it utilized a regular IDE 'Error List' window, but as the analyzer evolved, the capabilities of this default window became insufficient. Apart from being un-extendable with such specific static analysis UI elements as, for example, false positive suppression and filtering mechanisms, the Error List is itself basically a 'real' grid, as it stores all of the displayed elements inside itself. Therefore, this grid only permits an adequate handling of 1-2k messages at a time, performance wise, as a greater number of messages already can cause quite a noticeable lag to the environment's UI. On the other hand, our own practice of using static analysis on relatively large projects, such as Chromium or LLVM, demonstrated that a total number of diagnostic messages (taking into account all of the marked false alarms and low-lever user diagnostics as well) could easily reach tens of thousands or even more.
Therefore, by implementing a custom output window, based on virtual grid that is connected to a DB table, PVS-Studio is able to display and provide convenient handling for hundreds of thousands of diagnostic messages at once. Also, the ability for a convenient and flexible filtering of the analysis results is quite an important aspect of handling a static analyzer, as the manual examination even of only such a "tiny" amount of messages as 1-2k is nearly impossible for a single user. The storage of analysis results in a Datatable object by itself provides quite a convenient filtering mechanism based on a simple SQL queries, even more so because the results of such queries become visible immediately inside the bound virtual grid.
Handling tool windows events A client area of a tool window (represented by our
ToolWindowPane subclass) can process the regular events of user-interface interactions. The
IVsWindowFrameNotify3 interface can be used for subscribing to window events. Let's provide an example of implementing this interface:
public sealed class WindowStatus: IVsWindowFrameNotify3
{
// Private fields to keep track of the last known state
private int x = 0;
private int y = 0;
private int width = 0;
private int height = 0;
private bool dockable = false;
#region Public properties
// Return the current horizontal position of the window
public int X
{
get { return x; }
}
// Return the current vertical position of the window
public int Y
{
get { return y; }
}
// Return the current width of the window
public int Width
{
get { return width; }
}
// Return the current height of the window
public int Height
{
get { return height; }
}
// Is the window dockable
public bool IsDockable
{
get { return dockable; }
}
#endregion
public WindowStatus()
{}
#region IVsWindowFrameNotify3 Members
// This is called when the window is being closed
public int OnClose(ref uint pgrfSaveOptions)
{
return Microsoft.VisualStudio.VSConstants.S_OK;
}
// This is called when a window "dock state" changes.
public int OnDockableChange(int fDockable, int x, int y, int w,
int h)
{
this.x = x;
this.y = y;
this.width = w;
this.height = h;
this.dockable = (fDockable != 0);
return Microsoft.VisualStudio.VSConstants.S_OK;
}
// This is called when the window is moved
public int OnMove(int x, int y, int w, int h)
{
this.x = x;
this.y = y;
this.width = w;
this.height = h;
return Microsoft.VisualStudio.VSConstants.S_OK;
}
// This is called when the window is shown or hidden
public int OnShow(int fShow)
{
return Microsoft.VisualStudio.VSConstants.S_OK;
}
/// This is called when the window is resized
public int OnSize(int x, int y, int w, int h)
{
this.x = x;
this.y = y;
this.width = w;
this.height = h;
return Microsoft.VisualStudio.VSConstants.S_OK;
}
#endregion
}As evident by this sample code above, the
WindowsStatus class implementing the interface is able to process such window state changes, as the alterations in window's size, position, visibility properties and so on. Now, let's subscribe our window for handling these events. It requires the
OnToolWindowCreated method to be overridden in our
ToolWindowPane subclass:
public class MyToolWindow: ToolWindowPane
{
public override void OnToolWindowCreated()
{
base.OnToolWindowCreated();
// Register to the window events
WindowStatus windowFrameEventsHandler = new WindowStatus();
ErrorHandler.ThrowOnFailure(
((IVsWindowFrame)this.Frame).SetProperty(
(int)__VSFPROPID.VSFPROPID_ViewHelper,
(IVsWindowFrameNotify3)windowFrameEventsHandler));
}
...
}Controlling window state A window state can be controlled through event handlers of our
IVsWindowFrameNotify3 implementation.
The
OnShow method notifies the extension package about changes in tool window's visibility state, allowing to track the appearance of the window to a user, when, for example, user switches windows by clicking on window tabs. Current visibility state could be obtained by the
fShow parameter, which corresponds to the
__FRAMESHOW list.
The
OnClose method notifies about the closure of a window frame, allowing to define IDE behavior in case of this event with the
pgrfSaveOptions parameter, which controls the default document saving dialog (
__FRAMECLOSE).
The
OnDockableChange method informs the package on window's docking status changes. The
fDockable parameter indicates whether a window is docked to another one; other parameters control window's size and position before and after the docking event.
The parameters of
OnMove and
OnSize methods provide window's coordinates and size while it is being dragged or resized.
References
- MSDN. Kinds of Windows.
- MSDN. Tool Windows.
- MSDN. Tool Window Essentials.
- MSDN. Tool Window Walkthroughs.
- MSDN. Arranging and Using Windows in Visual Studio.
- MZ-Tools. HOWTO: Understanding toolwindow states in Visual Studio.
Integrating into Visual Studio settings
This item covers the extension of Visual Studio by integrating into its 'Settings' dialog pages. Option page registration and integration into the IDE for different kinds of extension packages will be examined, as well as the means to display various standard and user-created components inside a custom settings page. Also covered are the ways of accessing environment settings through Visual Studio Automation model and preservation mechanism for option pages.
Introduction
Visual Studio employs a single unified dialog window to provide an access to the settings of its various components. This window is available through the IDE Tools -> Options main menu item. A basic element of Visual Studio settings is an Options Page. The Options dialog window arranges its pages in a tree-like structure according to the membership of the pages in their respective functional groups. Each one of these pages could be uniquely identified by the name of its group and its own name. For example, Visual Basic source code editor settings page is "Text Editor, Basic".
Extension packages are able to access and modify the values of various settings from option pages registered in the IDE. They can also create and register their own custom options pages in the environment through the automation object model and MPF classes (Managed Package Framework, available only to VSPackage extensions). Visual Studio contains an embedded mechanism for preserving the state of its settings objects; it is enabled by default, but can be overridden or disabled.
Creating and registering user options pages
It can be useful for a Visual Studio extension plug-in to be associated with one or several custom options pages from the Tools->Options dialog window. Such a tool for configuring an extension will conform to the environment's UI paradigm and is actually quite convenient for handling your extension's settings from within the IDE itself. The methods of implementing and integrating custom user options page into the IDE can vary, as they depend upon the type of the extension being developed and the technology being used (either an automation model or MPF).
Integrating settings through an MPF class Managed Package Framework allows creating custom options pages by inheriting from the
DialogPage. As the environment loads each of its options pages independently when accessing the corresponding section of the Tools->Options dialog, each page must be implemented with an independent object as a result.
The object which implements a custom page should be associated with your VSPackage through the
ProvideOptionPage attribute of the corresponding
Package subclass.
[ProvideOptionPageAttribute(typeof(OptionsPageRegistration),
"MyPackage", "MyOptionsPage", 113, 114, true)]
This attribute designates the names for the options page itself and for group that it belongs to, as it should be displayed in the IDE options dialog. A separate attribute should be used for every custom page that is to be integrated by the extension. In fact, this attribute is used to provide a registration for the page through pkgdef file and it does not directly affect the execution in any other way. For the user options page to be correctly rendered by the environment, the page should be registered in the following node of the system registry:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\VisualStudio\<VsVersion>\
ToolsOptionsPages
Here <vsversion> is the version number of Visual Studio IDE, 10.0 for example. This record will be automatically created when
ProvideOptionPage attribute is utilized. It should be noted that a correct uninstallation of an extension package also requires purging all of the records that this extension had written to the system registry before, including the ones belonging to its options pages. As the versions of Visual Studio IDE starting from 2010 can utilize VSIX packages to deploy/uninstall VSPackage plug-ins, the VSIX installer will automatically perform such registry operations according to its pkgdef file. But earlier versions of IDE may require manual registry cleaning, for instance by a stand-alone installer application.
The 6th bool-type argument of the attribute's constructor allows the user's custom options page to be registered as an automation object. This exposes the page to the Automation Object Model, providing an access to its settings through the EnvDTE interfaces for other third-party plug-ins. Registering an automation object requires the creation of several records in the system registry (it is performed automatically when using the aforementioned attributes) in the following nodes:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\VisualStudio\<Version\Packages\
<PackageGUID>\Automation
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\VisualStudio\<Version>\
AutomationProperties
The
ProvideProfile attribute allows registering an options page or any other independent object with the build-in mechanism for setting's state preservation, provided that such user object implements the
IProfileManager interface.
Implementing an MPF DialogPage subclass As a minimal requirement for
DialogPage subclass to implement an IDE options page, this derived class should contain at least one public property. Here is an example of such a basic implementation:
namespace MyPackage
{
class MyOptionsPage : DialogPage
{
bool myOption = true;
public bool MyOption
{
get { return this. myOption; }
set { this. myOption = value; }
}
}
}To display such a generic implementation of
DialogPage subclass, IDE will utilize a standard
PropertyGrid control as a client area of the page window, which in turn will contain all public properties of this subclass. This could be convenient in case your extension's configuration properties are rather simple, so handling them through embedded
PropertyGrid editors does not present any trouble. Using a control native to IDE will also exempt you from common issues with incorrect UI scaling for components on different DPI resolutions in the Visual Studio Options dialog.
However, if you want to host a user-created control inside an options page, it could be achieved by overriding the
Window property of your
DialogPage subclass:
[BrowsableAttribute(false)]
protected override IWin32Window Window
{
get
{
return MyUserControl;
}
}A reference to the
IWin32Window object implementing the window's client area should be returned by this property. Visual Studio required its options pages to be constant, i.e. they should not be recreated for any of their subsequent calls. As Windows Forms objects can delete and recreate their window handles at will, it is recommend passing a reference to the object derived from a
UserControl type.
The
AutomationObject property of a custom options page derived from the
DialogPage class determines the public properties which are shown by the default display mechanism and persisted by the IDE.
AutomationObject returns a reference to the
DialogPage subclass itself by default, but if it returns a reference to some other object, then the properties of that returned object will be preserved and displayed instead. By default, system registry serves as a local storage for state preservation mechanism. Overriding the
DialogPage.SaveSettingsToStorage method makes it possible to change the way of object's state preservation method (similar could be done to the state restoration through
LoadSettingsFromStorage override).
public override void SaveSettingsToStorage() { ... }Custom pages registered as automation objects can store their settings, along with settings from other options pages, in an external XML file through the standard IDE command Tools -> Import/Export Settings, by the default implementation of the
SaveSettingsToXml method which also can be overridden if necessary.
Of course, integrating a page into Visual Studio settings dialog is not the exclusive or mandatory way of creating configuration interface for an IDE plug-in. If the capabilities of a regular
PropertyGrid are insufficient and there are no future plans to utilize the embedded mechanism for settings preservation, then it could be quite reasonable to implement an IDE-independent settings dialog. The advantages of this approach are high portability (for instance, a plug-in that could be used with multiple IDEs) and complete control over the dialog window itself, which in turn substantially alleviates the support of various end-user configurations. On the downside, such solution makes your settings inaccessible to third-party developers through the automation object model.
For configuring its settings, PVS-Studio extension package utilizes a custom state preservation mechanism that operates through an external XML file, so that the options pages which the plug-in integrates into the IDE are provided only as means for displaying and modifying these internal settings. Initially, the embedded settings preservation functionality of Visual Studio created conflicts with PVS-Studio's own settings mechanism in the earlier versions of the plug-in, leading to setting de-synchronization issues. This demonstrated to us that even in the presence of an independent settings management inside the extension, it still may be necessary to override some of Visual Studio regular mechanisms (maybe even by an empty method).
Integrating settings through an Add-In XML definition A user options page can be integrated into the IDE through an independent XML definition of an Add-In extension. The contents of such a user page should be implemented as a user component, for example as an
System.Windows.Forms.UserControl. This component is not associated with an Add-In itself, thus it can be implemented either inside the extension's assembly or as an independent library altogether. An add-in XML file could even be created for such user component alone, without any definitions for an Add-In extension. Let's examine an XML definition for an Add-In module which also contains a definition for a user's custom options page.
<?xml version="1.0" encoding="UTF-16" standalone="no"?>
<Extensibility xmlns="http://schemas.microsoft.com/AutomationExtensibility">
<HostApplication>
<Name>Microsoft Visual Studio Macros</Name>
<Version>10.0</Version>
</HostApplication>
<HostApplication>
<Name>Microsoft Visual Studio</Name>
<Version>10.0</Version>
</HostApplication>
<Addin>
<FriendlyName>My Add in</FriendlyName>
<Description>My Addin 1</Description>
<Assembly>c:\MyAddIn1\MyAddin1.dll</Assembly>
<FullClassName>MyAddin1.Connect</FullClassName>
<LoadBehavior>0</LoadBehavior>
<CommandPreload>1</CommandPreload>
<CommandLineSafe>0</CommandLineSafe>
</Addin>
<ToolsOptionsPage>
<Category Name="MyAddIn1">
<SubCategory Name="My Tools Options Page">
<Assembly> c:\MyAddIn1\MyAddin1.dll</Assembly>
<FullClassName>MyAddin1.UserControl1</FullClassName>
</SubCategory>
</Category>
</ToolsOptionsPage>
</Extensibility>A description for custom options page is located inside the <toolsoptionspage> node. The <assembly> sub-node points to the library which contains a user component for the client area of the page. The <fullclassname> contains the full name of a user component in a
Namespace.ClassName format. The <category> and <subcategory> nodes define position of a user page inside the Tools->Options tree-like structure by specifying page's group and personal names. Any existing group names, as well as a new one, can be used as a <category> value. As evident by the example, a user
MyAddin1.UserControl1 component is located inside the same assembly as the add-in itself, though this is not a mandatory requirement.
Visual Studio loads a page after it is opened by a user for the first time through the Options dialog window. As opposed to the integration of a page through the Managed Package Framework, the description of a page is stored within an XML description addin file, so the page will be initialized only after the environment discovers such a file. Visual Studio reads addin files which are available to it immediately after start-up. The Environment -> Add-In/Macross Security options page specifies the paths which are used for addin discovery. Contrary to custom option pages implemented through inheriting the MPF classes, such high level approach to the integration does not register such a page as an automation object, and so it does not provide ways to access the page's contents through automation object model or to utilize the embedded state preservation mechanism of the environment.
Accessing option pages through the automation
Visual Studio Automation Object Model provides the means of accessing various system settings of the Tools->Options dialog, excluding some of the pages, such as 'Dynamic Help' and 'Fonts and Colors pages (they are available through separate APIs). User-created custom option pages are also available through the automation model in case they are registered as automation objects themselves (as described in the previous section).
The
get_Properties method can be utilized to obtain the necessary settings:
Properties propertiesList = PVSStudio.DTE.get_Properties("MyPackage",
"MyOptionsPage");The option page can be identified by its own name and the name of group it belongs to. Here is the example of obtaining value for a specific property:
Property MyProp1 = propertiesList.Item("MyOption1");The value of the property can be accessed and modified through the
MyProp1.Value.
The
ShowOptionPage method of the
Package MPF subclass can be used to open and display the custom options page inside the Options window.
MyPackage.ShowOptionPage(typeof(MyOptionsPage));
As evident by the example, this method takes the type of a user-created
DialogPage subclass. However, if it is required to open any other page which is not part or your extension project, a standard IDE page for example, then it could be located by its GUID identifier available at this registry branch:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\VisualStudio\9.0\
ToolsOptionsPages\<OptionsPageNme>\
Here <optionspagename> is the name of a page inside the Tools -> Options dialog. Following is the example of opening a standard TextEditor -> GeneralIDE settings page through the
IMenuCommandService global service:
string targetGUID = "734A5DE2-DEBA-11d0-A6D0-00C04FB67F6A";
var command = new CommandID(VSConstants.GUID_VSStandardCommandSet97,
VSConstants.cmdidToolsOptions);
var mcs = GetService(typeof(IMenuCommandService))
as MenuCommandService;
mcs.GlobalInvoke(command, targetGUID);
In fact, this code is equivalent to the execution of the
Tools.Options IDE command. It can be invoked through the
ExecuteCommand method of the
EnvDTE.DTE:
dte.ExecuteCommand("Tools.Options",
"734A5DE2-DEBA-11d0-A6D0-00C04FB67F6A"). References
- MSDN. Options Pages.
- MSDN. State Persistence and the Visual Studio IDE.
- MSDN. User Settings and Options.
- MSDN. Registering Custom Options Pages.
- MSDN. Providing Automation for VSPackages.
Visual Studio project model
This item covers the structure of Visual Studio project model and its implementation on the example of Visual C++ (VCProject). Also included are the cases of using the project model for enumeration of project elements and obtaining their compilation properties through the corresponding configurations. Isolated Shell based Atmel Studio environment will be examined as an example of a third-party implementation of the project model.
Introduction
Visual Studio project model is a collection of interfaces describing the properties of a compiler, linker and other build tools, as well as the structure of MSVS-compatible projects themselves, and it is connected with the
Visual Studio Automation Object Model through the VCProjects late-bound properties. Visual C++ project model extends the standard Visual Studio project model, providing access to the specific functionality of Visual C++ (vcproj/vcxproj) project types. Visual C++ project model is a stand-alone COM component available through the VCProjectEngine.dll assembly, which could also be used independently outside of Visual Studio development environment. It is possible for third-party developers to create custom implementations of the project model, adding the support of new languages and compilers into Visual Studio.
Project model structure
Visual Studio provides an extendable project-neutral object model that represents solutions, projects, code objects, documents, etc. Every MSVS project type has a corresponding project automation interface. Every tool in the environment that has a project also has an object of the 'Project' type associated with it. Standard Visual C++ project model also complies with this general automation project model scheme:
Projects
|- Project -- Object(unique for the project type)
|- ProjectItems (a collection of ProjectItem)
|- ProjectItem (single object) -- ProjectItems (another
collection)
|- Object(unique for the project type)
The 'Projects' interface provides an ensemble of abstract objects of the 'Project' type. The 'Project' interface defines an abstract project, i.e. it can reference an object from any project model that complies with the standard scheme. Any peculiar properties of a specific model should be defined through a special interface which is unique only to this model alone. A reference for such an object could be acquired through the
Project.Object property. For instance, specific properties of Visual C++ project could be obtained through the
VCProject interface, and for the Atmel Studio model it will be the
AvrGCCNode interface:
Project proj;
...
VCProject vcproj = proj.Object as VCProject;
AvrGCCNode AvrGccProject = proj.Object as AvrGCCNode;
It is possible to obtain a list of all projects loaded in IDE and belonging to any project model type through the
dte.Solution.Projects field; projects belonging to a particular model can be acquired through the
DTE.GetObject method (see the example below for Visual C++ model):
Projects vcprojs = m_dte.GetObject("VCProjects") as Projects;To obtain projects of all types, the following code could be used:
Projects AllProjs = PVSStudio.DTE.Solution.Projects;
The
ProjectItems interface represents an ensemble of abstract solution tree elements of
ProjectItem type. Similar to the
Project interface, the
ProjectItem can define any kind of element; it can even contain the same
ProjectItems collection inside itself (accessible through the
ProjectItem.ProjectItems) or it can be a Project altogether. An object unique for a specific project model can be obtained through the
ProjectItem.Object field. For instance, a Visual C++ source code file is represented by a VCFile type, and Atmel Studio source file be the
AvrGccFileNode interface:
ProjectItem projectItem;
...
VCFile file = projectItem.Object as VCFile;
AvrGccFileNode file = projectItem.Object as AvrGccFileNode;
An embedded project can be obtained in a similar manner when such an element of the hierarchy represents a project:
Project proj = projectItem.Object as Project;
Recursively walking all elements of a Solution tree's branch
The interface for controlling hierarchies
IVsHierarchy can be used to perform a passing of Solution tree's branch. This interface provides an access to abstract nodes of a tree, each one of which in turn could be a leaf, a container of elements or a link to another hierarchy. Each tree node is uniquely identified through the
DWORD identifier
VSITEMID. Such identifiers are unique within the scope of a single hierarchy and possess a limited lifetime within it.
A hierarchy object can be obtained for a tree branch of a single project through the
VsShellUtilities.GetHierarchy method:
public static IVsHierarchy ToHierarchy(EnvDTE.Project project)
{
System.IServiceProvider serviceProvider =
new ServiceProvider(project.DTE as
Microsoft.VisualStudio.OLE.Interop.IServiceProvider);
Guid guid = GetProjectGuid(serviceProvider, project);
if (guid == Guid.Empty)
return null;
return VsShellUtilities.GetHierarchy(serviceProvider, guid);
}In the example above, the hierarchy was obtained for a project through its GUID identifier. Consider the example of obtaining this GUID identifier for a project:
private static Guid GetProjectGuid(System.IServiceProvider
serviceProvider, Project project)
{
if (ProjectUnloaded(project))
return Guid.Empty;
IVsSolution solution =
(IVsSolution)serviceProvider.GetService(typeof(SVsSolution)) as
IVsSolution;
IVsHierarchy hierarchy;
solution.GetProjectOfUniqueName(project.FullName, out hierarchy);
if (hierarchy != null)
{
Guid projectGuid;
ErrorHandler.ThrowOnFailure(
hierarchy.GetGuidProperty(
VSConstants.VSITEMID_ROOT,
(int)__VSHPROPID.VSHPROPID_ProjectIDGuid,
out projectGuid));
if (projectGuid != null)
{
return projectGuid;
}
}
return Guid.Empty;
}The
IEnumHierarchies interface permits obtaining all of the hierarchies for projects of a particular type through the solution.
GetProjectEnum method. Here is an example of obtaining the hierarchies for every Visual C++ project in a solution tree:
IVsSolution solution = PVSStudio._IVsSolution;
if (null != solution)
{
IEnumHierarchies penum;
Guid nullGuid = Guid.Empty;
Guid vsppProjectGuid =
new Guid("8BC9CEB8-8B4A-11D0-8D11-00A0C91BC942");
//You can ask the solution to enumerate projects based on the
//__VSENUMPROJFLAGS flags passed in. For
//example if you want to only enumerate C# projects use
//EPF_MATCHTYPE and pass C# project guid. See
//Common\IDL\vsshell.idl for more details.
int hr = solution.GetProjectEnum(
(uint)(__VSENUMPROJFLAGS.EPF_LOADEDINSOLUTION |
__VSENUMPROJFLAGS.EPF_MATCHTYPE),
ref vsppProjectGuid, out penum);
ErrorHandler.ThrowOnFailure(hr);
if ((VSConstants.S_OK == hr) && (penum != null))
{
uint fetched;
IVsHierarchy[] rgelt = new IVsHierarchy[1];
PatternsForActiveConfigurations.Clear();
while (penum.Next(1, rgelt, out fetched) == 0 && fetched == 1)
{
...
}
}
}As evident by the example above, the
GetProjectEnum method provides hierarchies for projects based on a project kind specified by the GUID identifier. GUID identifiers for regular Visual Studio/MSBuild project types can be obtained
here. The
penum.Next() method allows us to enumerate all project hierarchies we've acquired (the
rgelt array). It should be remembered that user-created project models could possess their own unique identifiers in case they define a new project type for themselves. Such custom user identifiers can be obtained from XML project files of the corresponding models.
But our own experience in developing PVS-Studio IDE plug-in demonstrates that an opposite situation is quite possible as well, that is, when a user-created project type uses a GUID from one of the stock project types, usually the one from which it was derived. In particular, we've encountered a
VCProject type that was extended to provide development for Android platform. As a result, this project model extension had caused crashes in our plug-in because it did not provide several properties which are otherwise present in
VCProject model (OpenMP for example) through the automation API. An intricacy of this situation is that such an extended project model type cannot be differentiated from a regular one, and thus, it is quite hard to correctly process it as well. Therefore, when you are extending a project model through your custom types, to avoid such conflicts with various IDE components (including other third-party extensions as well), it is always important to remember the necessity of providing means to uniquely identify your types.
Possessing an
IVsHierarchy for the project, we are able to recursively enumerate all the elements of such solution tree branch through the
hierarchy.GetProperty method, which in turn provides us with the specified properties for each one of the hierarchy nodes:
EnumHierarchyItemsFlat(VSConstants.VSITEMID_ROOT, MyProjectHierarchy,
0, true);
...
public void EnumHierarchyItemsFlat(uint itemid, IVsHierarchy
hierarchy, int recursionLevel, bool visibleNodesOnly)
{
if (hierarchy == null)
return;
int hr; object pVar;
hr = hierarchy.GetProperty(itemid,
(int)__VSHPROPID.VSHPROPID_ExtObject, out pVar);
ProjectItem projectItem = pVar as ProjectItem;
if (projectItem != null)
{
...
}
recursionLevel++;
//Get the first child node of the current hierarchy being walked
hr = hierarchy.GetProperty(itemid,
(visibleNodesOnly ? (int)__VSHPROPID.VSHPROPID_FirstVisibleChild
:(int)__VSHPROPID.VSHPROPID_FirstChild),
out pVar);
Microsoft.VisualStudio.ErrorHandler.ThrowOnFailure(hr);
if (VSConstants.S_OK == hr)
{
//We are using Depth first search so at each level we recurse
//to check if the node has any children
// and then look for siblings.
uint childId = GetItemId(pVar);
while (childId != VSConstants.VSITEMID_NIL)
{
EnumHierarchyItemsFlat(childId, hierarchy, recursionLevel,
visibleNodesOnly);
hr = hierarchy.GetProperty(childId,
(visibleNodesOnly ?
(int)__VSHPROPID.VSHPROPID_NextVisibleSibling :
(int)__VSHPROPID.VSHPROPID_NextSibling),
out pVar);
if (VSConstants.S_OK == hr)
{
childId = GetItemId(pVar);
}
else
{
Microsoft.VisualStudio.ErrorHandler.ThrowOnFailure(hr);
break;
}
}
}
}
private uint GetItemId(object pvar)
{
if (pvar == null) return VSConstants.VSITEMID_NIL;
if (pvar is int) return (uint)(int)pvar;
if (pvar is uint) return (uint)pvar;
if (pvar is short) return (uint)(short)pvar;
if (pvar is ushort) return (uint)(ushort)pvar;
if (pvar is long) return (uint)(long)pvar;
return VSConstants.VSITEMID_NIL;
}
A
ProjectItem object that we've acquired for each one of the tree's nodes will allow us to obtain its corresponding Visual C++ object (as well as the object for any other custom project model) through the
Object filed, as was described earlier.
Enumerating all projects in solution tree DTE.Solution.Projects interface can be used to enumerate all projects in the solution:
if (m_DTE.Solution.Projects != null)
{
try
{
foreach (object prj in m_DTE.Solution.Projects)
{
EnvDTE.Project proj = prj as EnvDTE.Project;
if (proj != null)
WalkSolutionFolders(proj);
}
}
}
Besides projects, Solution tree can also contain folder nodes (Solution Folders). They should also be taken into account while processing each
Project element:
public void WalkSolutionFolders(Project prj)
{
VCProject vcprj = prj.Object as VCProject;
if (vcprj != null && prj.Kind.Equals(VCCProjectTypeGUID))
{
if (!ProjectExcludedFromBuild(prj))
{
IVsHierarchy projectHierarchy = ToHierarchy(prj);
EnumHierarchyItemsFlat(VSConstants.VSITEMID_ROOT,
projectHierarchy, 0, false);
}
}
else if (prj.ProjectItems != null)
{
foreach (ProjectItem item in prj.ProjectItems)
{
Project nextlevelprj = item.Object as Project;
if (nextlevelprj != null && !ProjectUnloaded(nextlevelprj))
WalkSolutionFolders(nextlevelprj);
}
}
}Projects that are excluded from the build should be inspected separately, as they are not accessible through the automation model after being unloaded from the IDE:
public bool ProjectExcludedFromBuild(Project project)
{
if (project.UniqueName.Equals("<MiscFiles>",
StringComparison.InvariantCultureIgnoreCase))
return true;
Solution2 solution = m_DTE.Solution as Solution2;
SolutionBuild2 solutionBuild =
(SolutionBuild2)solution.SolutionBuild;
SolutionContexts projectContexts =
solutionBuild.ActiveConfiguration.SolutionContexts;
//Skip this project if it is excluded from build.
bool shouldbuild =
projectContexts.Item(project.UniqueName).ShouldBuild;
return !shouldbuild;
} Enumerating selected elements The
DTE.SelectedItems interface can be used to enumerate solution elements which are selected in the Solution Explorer window.
foreach (SelectedItem item in items)
{
VCProject vcproj = null;
if (item.Project != null)
{
vcproj = item.Project.Object as VCProject;
if (vcproj != null && item.Project.Kind.Equals("{" +
VSProjectTypes.VCpp + "}"))
{
IVsHierarchy projectHierarchy = ToHierarchy(item.Project);
PatternsForActiveConfigurations.Clear();
EnumHierarchyItemsFlat(VSConstants.VSITEMID_ROOT,
projectHierarchy, 0, false, files, showProgressDialog);
}
else if (item.Project.ProjectItems != null)
{
//solution folder
if (!ProjectUnloaded(item.Project))
WalkSolutionFolders(item.Project);
}
}
else if (item.ProjectItem != null)
{
//walking files
...
else if (item.ProjectItem.ProjectItems != null)
if (item.ProjectItem.ProjectItems.Count > 0)
WalkProjectItemTree(item.ProjectItem);
}
}
private void WalkProjectItemTree(object CurrentItem)
{
Project CurProject = null;
CurProject = CurrentItem as Project;
if (CurProject != null)
{
IVsHierarchy projectHierarchy = ToHierarchy(CurProject);
PatternsForActiveConfigurations.Clear();
EnumHierarchyItemsFlat(VSConstants.VSITEMID_ROOT,
projectHierarchy, 0, false);
return;
}
ProjectItem item = null;
item = CurrentItem as ProjectItem;
if (item != null)
{
...
if (item.ProjectItems != null)
if (item.ProjectItems.Count > 0)
{
foreach (object NextItem in item.ProjectItems)
WalkProjectItemTree(NextItem);
}
}
} Visual C++ project model. Configurations and properties of projects and files
To this moment, we have been examining a general, exterior part of Visual Studio project model, declared mostly in
EnvDTE namespace, which is available from any version of project model implementation. Now, let's talk about one of the regular implementations of this model: Microsoft Visual C++. It is declared in the
VisualStudio.VCProjectEngine namespace.
Visual C++ project model implements a general Visual Studio project model, so interfaces described in the previous chapters can be utilized for projects of this particular model as well. Interfaces that are specific to Visual C++ model are defined inside the
Microsoft.VisualStudio.VCProjectEngine.dll assembly. This assembly should be added to the references of the extension that is being developed.
Visual C++ physically stores build configurations (compilation and linking parameters, pre-build and post-build steps, external tool command lines, etc.) for C/C++ source files inside its XML-based project files (vcproj/vcxproj). These settings are available to Visual Studio users through property page dialogs.
Each combination of project's build configuration (Debug, Release, etc.) and platform (Win32, IA64, x64, etc.) is associated with a separate collection of settings. Although majority of the settings are defined at the project level, it is possible to redefine separate properties for each individual file (file properties are inherited from its project by default). The list of properties which can be redefined at the file level is dependent upon the type of a file in question. For example, only the
ExcludedFromBuild property can be redefined for header files, but cpp source files permit the redefinition for any of its compilation properties.
Obtaining configurations Visual C++ project model presents property pages through the
VCConfiguration (for a project) and
VCFileConfiguration (for a file) interfaces. To obtain these objects we will start from a
ProjectItem object which represents an abstract Solution tree element.
ProjectItem item;
VCFile vcfile = item.Object as VCFile;
Project project = item.ContainingProject;
String pattern = "Release|x64";
if (String.IsNullOrEmpty(pattern))
return null;
VCFileConfiguration fileconfig = null;
IVCCollection fileCfgs = (IVCCollection)vcfile.FileConfigurations;
fileconfig = fileCfgs.Item(pattern) as VCFileConfiguration;
if (fileconfig == null)
if (fileCfgs.Count == 1)
fileconfig = (VCFileConfiguration)fileCfgs.Item(0);
In the example above we've acquired a file configuration for
VCFile object (which represents a C/C++ header or a source file) by passing a configuration pattern (configuration's name and platform) to the
Item() method. Build configuration pattern is defined on the project level. The following example demonstrates the acquisition of active configuration (the one that is selected in IDE) of a project.
ConfigurationManager cm = project.ConfigurationManager;
Configuration conf = cm.ActiveConfiguration;
String platformName = conf.PlatformName;
String configName = conf.ConfigurationName;
String pattern = configName + "|" + platformName;
return pattern;
The
ActiveConfiguration interface should be handled with care. Quite often we've encountered exceptions when calling it from our PVS-Studio IDE extension package. In particular, this field sometimes becomes inaccessible through the automation object model when a user is building a project, or in the presence of any other heavy user interaction with Visual Studio UI. As there is no assured way of predicting such user actions, it is advised to provide additional error handlers for such 'bottlenecks' when accessing settings with automation model. It should be noted that this particular situation is not related to COM exception handling that was described in the previous article dedicated to
EnvDTE interfaces, and it is probably related to some internal issues within the automation model itself.
Next, let's acquire the configuration for a project that contains the file in question:
VCConfiguration cfg=(VCConfiguration)fileconfig.ProjectConfiguration;
While the interfaces representing configurations themselves contain settings only from the 'General' tab of the property pages, references for individual build tools can be acquired through the
VCConfiguration.Tools and
VCFileConfiguration.Tool interfaces (note that a single file contains settings respectively for only one build tool). Let's examine the
VCCLCompilerTool interface representing the C++ compiler:
ct = ((IVCCollection)cfg.Tools).Item("VCCLCompilerTool") as
VCCLCompilerTool;
ctf = fileconfig.Tool as VCCLCompilerTool;Now let's acquire the contents of, for example, the
AdditionalOptions field belonging to the compiler tool, using the
Evaluate method to process any macros that we can encounter within its value:
String ct_add = fileconfig.Evaluate(ct.AdditionalOptions);
String ctf_add = fileconfig.Evaluate(ctf.AdditionalOptions);
Property Sheets Property sheets are XML files with a *.props extension. They allow an independent definition of project's build properties, i.e. the command line parameters for various building tools, such as a compiler or a linker. Property sheets also support inheritance and can be used for specifying build configurations for several projects at once, i.e. the configuration defined inside the project file itself (vcproj/vcxproj) could inherit some of its properties from single or multiple props files.
To handle property sheets, Visual C++ project model provides the
VCPropertySheet interface. A collection of
VCPropertySheet objects can be obtained through the
VCConfiguration.PropertySheets field:
IVCCollection PSheets_all = fileconfig.PropertySheets;
Similarly, the
PropertySheets field of the
VCPropertySheet interface provides a reference to a collection of child property sheet files for this object. Let's examine the recursive enumeration of all of the project's property sheets:
private void ProcessAllPropertySheets(VCConfiguration cfg, IVCCollection PSheets)
{
foreach (VCPropertySheet propertySheet in PSheets)
{
VCCLCompilerTool ctPS =
(VCCLCompilerTool)((IVCCollection)propertySheet.Tools).Item(
"VCCLCompilerTool");
if (ctPS != null)
{
...
IVCCollection InherPSS = propertySheet.PropertySheets;
if (InherPSS != null)
if (InherPSS.Count != 0)
ProcessAllPropertySheets(cfg, InherPSS);
}
}
}In the example above we've obtained an object of
VCCLCompilerTool type (that is compilation settings) for
PropertySheet on every level. In this way we could gather all compilation parameters defined in every property sheet, including the embedded ones.
The
VCPropertySheet interface does not contain means to evaluate macros within its fields, so as a work-around, the
Evaluate method from the project's configuration can be used instead. But, such approach could also lead to the incorrect behavior in case the value of the macro being evaluated is related to the props file itself. For instance, several MSBuild macros which were introduced in the MSBuild version 4 could also be utilized inside vcxproj projects from Visual Studio 2010. Let's take the
MSBuildThisFileDirectory macro that evaluates as a path to the directory containing file in which it is used. Now, evaluating this macro through the cfg.Evaluate will result in a path to the vcxproj file, and not to props file, which actually does contains this macro.
All of the property sheets in Visual C++ project can be divided between user and system files. By user files we understand the props files which were created and added to the project by a user himself. But even an empty template-generated MSVC project often includes several property sheets by default. These system props files are utilized by the environment to specify various compilation parameters which were set inside the project's property page interface by the user. For example, setting up the
CharacterSet property to use Unicode manually in the Property Page interface will result in the appearance of a special property sheet in the 'Property Sheets' window which will define several preprocessor symbols (Unicode, _Unicode), and this properties subsequently will be inherited by the project. Therefore when processing properties from inside a Property sheet, one should always remember that compilation symbols defined in system props files are also returned by their corresponding property in the project's configuration through the automation API. Evidently, processing these two simultaneously while gathering compilation arguments can result in a duplication of such arguments.
Atmel Studio project model. Compilation settings in project toolsets.
We have examined an implementation of Visual Studio project model for C/C++ projects from Microsoft Visual C++, the model that is included into Visual Studio distribution by default. But Visual Studio automation model can be extended by adding interfaces for interacting with other custom project models from third-party developers (such custom project model can actually be implemented as a VSPackage extension). Therefore, if a developer of custom project model does provide interfaces for it, when it will be possible to interact with it the same way that we've interacted with Visual Studio regular models, such as Visual C++ one, as was described earlier.
For example, let's examine the interfaces of the project model that is provided by Atmel Studio IDE, the environment intended for development of embedded solutions. Now, you could probably ask – how does the topic of this article concern Atmel Studio, and we were always examining the interactions with Visual Studio? But, the truth is - Atmel Studio itself is the Visual Studio isolated shell application. We will not be discussing the essence of isolated shells here, and I will only mention that it is possible to develop the same kinds of extensions and plugins for isolated shells, as it is possible for the regular Visual Studio versions. You can familiarize yourself with some of the specifics regarding the development of Visual Studio plug-ins, including the isolated shell applications, in the previous chapter.
Now, Atmel project model itself is the implementation of a standard Visual Studio project model. And, exactly as for the Visual C++ projects, the common interfaces could be utilized with Atmel Studio projects as well. The interfaces that are specific for this model are declared in the AvrGCC.dll, AvrProjectManagement.dll and Atmel.Studio.Toolchain.Interfaces.dll files. These files can be obtained by downloading the Atmel Studio Extension Developer's Kit (XDK).
Atmel Studio project model physically stores its build parameters in cproj project files which themselves at the same time serve as project files for MSBuild system (as all of the standard project types in Visual Studio). Atmel project model supports C/C++ languages and utilizes special editions of GCC compilers for the purpose of building its source files.
Types of projects and toolchains Atmel Studio provides 2 types of projects: C and C++ projects. Please note that these project types possess different GUIDs, so this should be taken into account when traversing the project tree.
Atmel project model also provides 2 compile tool chains – GNU C compiler and GNU C++ Compiler, each one possessing a separate set of options. It should be noted that while C projects can hold only C compiler options, the toolchain of C++ project consists of both C and C++ options sets. The appropriate compile options set will be selected by the build system automatically during compilation according to the extension of the source file being built. This means that in the case of a "mixed" project, 2 compile tool sets will be utilized at the same time!
The available option sets for each individual project can be obtained through the
ProjectToolchainOptions interface.
ProjectItem item;
...
AvrGccFileNode file = item.Object as AvrGccFileNode;
AvrGCCNode project = file.ProjectMgr as AvrGCCNode;
AvrProjectConfigProperties ActiveProps = project.ConfigurationManager.GetActiveConfigProperties();
ProjectToolchainOptions ToolChainOptions = ActiveProps.ToolchainOptions;
if (ToolChainOptions.CppCompiler != null)
//Toolchain compiler options for C++ compiler
if (ToolChainOptions.CCompiler != null)
//Toolchain compiler options for C Compiler Obtaining compilation settings To extract individual compilation settings themselves, the
CompilerOptions object that we've obtained earlier (a common base type for
CppCompilerOptions and
CCompilerOptions) can be utilized. Some of the settings could be taken directly from this object, such as Include paths of a project:
CompilerOptions options;
...
List<String> Includes = options. IncludePaths;
Please note that a part of the settings are shared between all project types (i.e. between the C and C++ ones). An example of such common settings is the one holding system includes:
List<String> SystemIncludes = options. DefaultIncludePaths;
But most of other settings are available only through the OtherProperties property of the Dictionary<string, ilist<string="IList<String">> type. As evident by the type of this property, each setting (a key) corresponds to a list of one or more values.
However, if you wish to obtain a whole command line passed to MSBuild from the project (and to the compiler thereafter), and not the individual settings values, such command line can be immediately obtained through the
CommandLine property (which is a lot easier than in the case of
VCProjectEngine!):
String RawCommandLine = this.compilerOptions.CommandLine;
It should be noted that General settings, such as system includes, still will not be present in a command line obtained in this way.
Also worth noting is that either individual setting values or the whole command line obtained in this way could still contain a number of unexpanded MSBuild macros. The
GetAllProjectProperties method of the
AvrGCCNode interface can be utilized to resolve such macros:
AvrGCCNode project;
...
Dictionary<string, string> MSBuildProps = new Dictionary<string, string>();
project.GetAllProjectProperties().ForEach(x =>MSBuildProps.Add(x.Key, x.Value));
Now we can replace each macro we encounter with the corresponding values from
MSBuildProps collection.
Each file in the project can possess additional build parameters, additional compiler flags to be more precise. We can obtain such flags through the
AvrFileNodeProperties interface:
AvrGccFileNode file;
...
AvrFileNodeProperties FileProps = file.NodeProperties as AvrFileNodeProperties;
String AdditionalFlags = FileProps.CustomCompilationSetting;
References
- MSDN. Visual C++ Project Model.
- MSDN. Project Modeling.
- MSDN. Automation Model Overview.