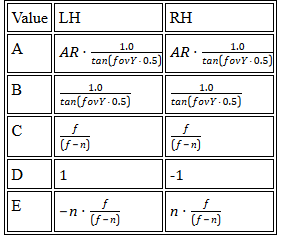
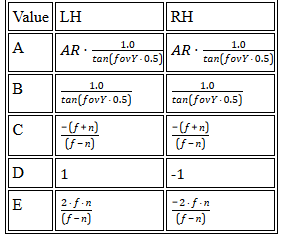
Computer animation has
come a long way since computers were invented. The memory capacity and processing units of contemporary machines provides the capability to perform millions of calculations per second. That's right down a game programmer's alley, particularly those involved in supporting animated characters for their project. Understanding the concept and implementation of animations is important to both character modelers and programmers alike as both modeling and programming have limitations determining what can be done.
The primary purpose for modeling a skinned mesh and its animations is to display a character on-screen which can perform actions such as running, walking, or shooting. When the animation data for that character has been imported into an application, a method is needed to process that data in real-time.
This article discusses a concept for processing that data and some example pseudo-code for implementing that concept - an animation controller.
This article is aimed primarily at intermediate level programmers. However, modelers will benefit from an understanding of the concept as they interact with the programmer. It requires a give-and-take attitude for both to produce satisfactory results. The reader should be familiar with the concept of a
skinned mesh comprised of a mesh and a frame (bone, node) hierarchy. An undertanding of animation data which may be comprised of scale, rotation and translation components such as vectors, matrices and quaternions isn't necessarily needed to understand the concept, but that level of programming skill will be needed to
implement an animation controller.
Though this article is primarily for 3D animation, the principles can be applied to 2D.
Concept of Skinned Mesh Animation
The frame hierarchy (bone structure, node tree) for a skinned mesh represents the skinned mesh in a
pose position. Each frame has a "to-parent" transformation (for the purposes of this article - a 4x4 matrix), sometimes called the frame's Transformation Matrix, which orients that frame relative to its parent frame. The orientation of each frame in the hierarchy's
root frame space is a "to-root" transform (described in above referenced article) calculated by working up from the root frame through each child frame
childFrame.ToRoot = childFrame.TransformationMatrix * parentFrame.ToRoot;
Animation data, the information needed to render a skinned mesh in some
animated position, is independent of the frame hierarchy, and is related to the hierarchy
only through the names of the frames. The animation data is processed by the animation controller for a specific time within the animation period to produce an animation transformation for each bone specified in the animation data, in every sense the same as the frame's to-parent (transformation) matrix. That is, just as the to-root calculations shown above can be used to render the mesh in its
pose position, the animation transforms can be used to render the mesh in an
animated position.
childFrame.AnimToRoot = childFrame.AnimTransform * parentFrame.AnimToRoot;
Moreover, an animation controller need "know"
nothing about the frame hierarchy. Once it performs the required calculations using animation data alone, it need "know" only where to store the results appropriate for each "name."
Animation Data
To ensure an animation controller can be implemented successfully, one should consider first what animation data will be
available. That may well be determined by the modeler, what modeling program is used, and what export options are available from that program. Though I am not intimately familiar with a great number of data formats, a bit of research indicates that many formats support the export of "key frames" comprised of, at a minimum, the rotation of the bone's frame at a particular time in the animation sequence. Several formats can export key frames containing scale, rotation and translation data.
A discussion of various file formats is well beyond the scope of this article. Entire books and SDKs (software development kits) are devoted to that subject. Therefore, this article will assume that a set of animations comprised of timed key frames, which may contain scale, rotation and translation data, can, in one fashion or another, be imported into the application for which the animation controller will be used.
Key frames are a primary ingredient in the process of animating a skinned mesh and should be understood by programmer and modeler alike.
Animation Key Frames
Key frames and key frame data are the primary data that an animation controller works with. Though the discussion is a bit long, a good understanding of key frames will greatly benefit the programmer, and will provide modelers with an insight into what data is produced by a modeling program, and how that data will be used.
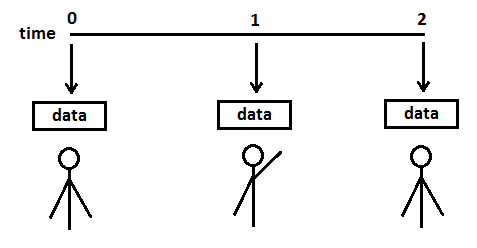
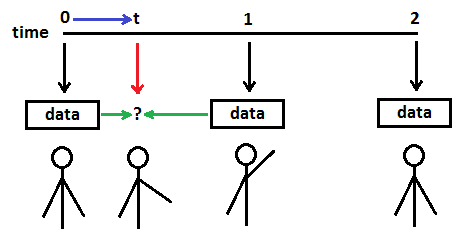
Consider a character (a skinned mesh) which raises an arm up from its side, and lowers it again to the arm's original position, over a period of two seconds of time. A slow flapping motion, if you will, similar to a bird's wing in flight. A modeler can design that action in three steps, specifying: at time 0, the arm bone is in position A; at time 1.0, the arm bone is in a rotated position B; and, at time 2.0, the arm bone is in position A. When the modeler plays back that animation (in most modeling programs), he will see a smooth motion for the arm, from the lowered position to the raised position and back. That information can be exported as just 3 key frames of data. The application can import that data and display an arm-flapping animation. Greatly simplified, the key frame data may appear as follows:
Key Frames
Arm:
time 0: rotation 0
time 1: rotation about some axis (x,y,z) by 90 degrees
time 2: rotation 0
![Attached Image: animctlr 1.png]()
In essence, the modeler has specified what the arm bone's position is to be at the times specified ("key" times) and expects the motion seen in the modeling program to be reflected in the application. One of the tasks that an animation controller must perform is to provide rotation data for rendering the character at times during the animation
other than at time 0, time 1 and time 2. That is, for times other than key frames specified by the modeler, the
animation controller provides the motion. Modelers and programmers alike should understand that. That process for smoothing the transition from one key frame to the next is
interpolation, and specific methods to do that will be discussed later.
As mentioned, the example above is greatly simplified for the purpose of illustration. In fact, it is likely that an animation sequence will be comprised of hundreds, if not thousands of key frames, more like the following.
Spine:
time 0.0: rot 1.6 (about axis) x,y,z
time 0.1: rot 1.65 x,y,z
time 0.2: rot 1.69 x,y,z
...
time 1.9: rot 1.65 x,y,z
time 2.0: rot 1.6 x,y,z
Arm:
time 0.0: rot 0.7 x,y,z
time 0.1: rot 0.71 x,y,z
time 0.2: rot 0.72 x,y,z
...
time 1.9: rot 0.71 x,y,z
time 2.0: rot 0.7 x,y,z
Head:
time 0.0: rot -0.6 x,y,z
time 0.1: rot -0.6 x,y,z
...
Note: The key frame data represented here (perhaps not in the same arrangement) is supported by several modeling program export file formats. Of particular note, the key frame data does not indicate parent-child relationships and does not include information about the frame hierarchy. It only indicates data related to a "name."
That represents another task the animation controller must perform: provide storage for the data in a way that permits access in an efficient manner.
For the animation controller described in this article, the
number of key frames for each bone has little to no effect on the time for updating the animation. An interpolation will be performed between two key frames for each render during animation in any case. The algorithm for finding which two frames to interpolate is the primary determinant for variations in the update time.
Regarding storage (memory footprint), consider the data for a 2 second animation for a frame hierarchy comprised of 35 bones, each bone having key frames every 0.1 second. That's 21 keyframes per bone for the duration of the animation, for a total of 735 keyframes for a 2 second animation. At, say, 15 bytes per key frame, that's a little over 10K bytes, which isn't much. Just something to keep in mind. As a U. S. politician (whose name I have thankfully forgotten) once said about small additions to the budget: "A billion here, a billion there.. pretty soon you're talking about big money."
Examining The Key Frame Data
Taking a closer look at the data, note the information in each line associated with a name: the time within the animation, the data type (scale, rot, trans), and 3 or 4 values.
Bone NameFor some file formats, key frame data is often related to a bone by the bone's name, in text characters. That provides separation between how the data is processed, and how it will be used. Simply put, the name associated with key frame data is used solely to determine where the animation transform will be stored.
Key frame timeThis is the time within the duration of the animation at which the named bone is to have the specified orientation with respect to its parent bone.
Most commonly, the maximum key frame time for all bones is the same, and represents the
period of the animation. That is, in the example data above, each animation has key frames from 0.0 to 2.0 seconds, a period of 2 seconds.
As mentioned above, the animation controller has the responsibility to interpolate between key frames as time progresses through the period of the animation. For instance, if the current time
in the animation sequence is 1.07, the animation controller will interpolate the values from the "time 1.0" key frame and the "time 1.1" key frame. Even at a relatively low rate of 30 frames-per-second, those same two key frames (1 second apart) will be used for interpolation 30 times each period.
Data TypeKey frame data, as assumed for this article, may contain any or all of the three types: scale, rotation, translation. The data type is, of course, critical to properly interpret the actual numeric values of the key frame.
Data ValuesNormally comprised of 3 floating-point values, one for each axis, for scale and translation.
Normally comprised of 4 floating-point values for a rotation (defining a quaternion.)
Using matrices for data values should be avoided. For the purposes of interpolating values between key frames, a matrix would have to be decomposed (factorization), its components interpolated, and a new matrix calculated for that SRT. Besides taking more time and memory, decomposing a matrix should be avoided as some algorithms may provide unreliable results.
Before continuing, take a look at terms that are used in this article.
Useful Terms
Terms describing a skinned mesh and its animation data vary widely. In the context of this article, the following terms are used:
SRT - A single sequence of
Scaling,
Rotation and
Translation, in fixed order. Some applications will require that sequence be performed in T-R-S order. The sequence order is commonly a result of the use of "row-major" or "column-major" matrices. A detailed knowledge of the math involved isn't important to the understanding of the concept of an animation controller, but
will determine how an animation controller is coded in detail. In this article, the term
SRT is used when separate vectors or quaternions, as opposed to a transform or matrix, should be used.
Transform (verb and noun), Transformation - The mathematical process, commonly a matrix ("4x4" or 16 floating point numbers,) for applying scaling, rotation and translation to a vector or to another transform.
Frame, Frame Hierarchy - a hierarchical structure of mathematical frames of reference, more commonly called "frames," "bones" or "nodes." All those terms refer to the same object.
Timed Key - A single structure comprised of an indication of a specific time in the animation sequence to which it's applicable, and one or more scale, rotation or translation components, which may be stored as just an array of floating-point numbers, or equivalent structures such as vectors or quaternions.
Animation - An array of Timed Keys associated with a
single bone. In general terms, "animation" is often used to describe the locomotion of
all the bones for an "action" such as running, walking, etc. This article uses the term primarily as described.
Animation Set - An array of Animations, one per frame, commonly sequenced for a single cyclic character action such as walking, running, etc. This is the term used to describe an "action" applying to
all the bones.
Vector - a sequenced array of numbers (most often floating point),
or a sequenced array of structures. As many readers may be familiar with the
Standard Template Library (STL), pseudo-code in this article often uses
std::vector for the arrays of structures, to distinguish it from a
vector, which represents an array of numbers.
String - a sequenced array of text characters. Most readers will be familiar with null-terminated character strings, and possibly the STL implementation
std::string. The actual implementation of "string," whether it be comprised of UNICODE, ASCII, or other text character representations, is left to the programmer.
What An Animation Controller Does
At this point in the discussion, it's expected that the reader will have an idea of the
form of the data an animation controller will be processing, and the expected results of that process. The term
interpolation has been introduced as the means by which the animation controller will provide data at a particular time in the animation sequence using key frame data. That interpolation provides the "motion" for the skinned mesh during animation.
When the animation sequence begins, at time 0, calculations could be done using the key frame for time 0 to provide animation transforms for rendering, something like the following:
// for the Arm bone
MATRIX4X4 animMat = MatrixFromQuaternion( key[0].quaternion ) );
Frame* frame = FindFrameWithName( keyFrame.BoneName );
frame->TransformationMatrix = animMat;
Now consider the following situation during an animation. The key frame data has been loaded, that data has been arranged in a suitable fashion, a time variable
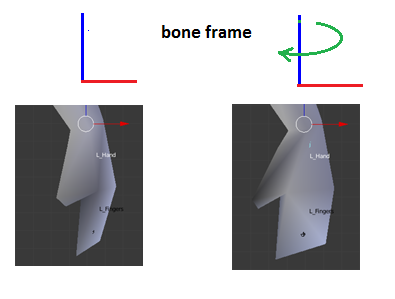
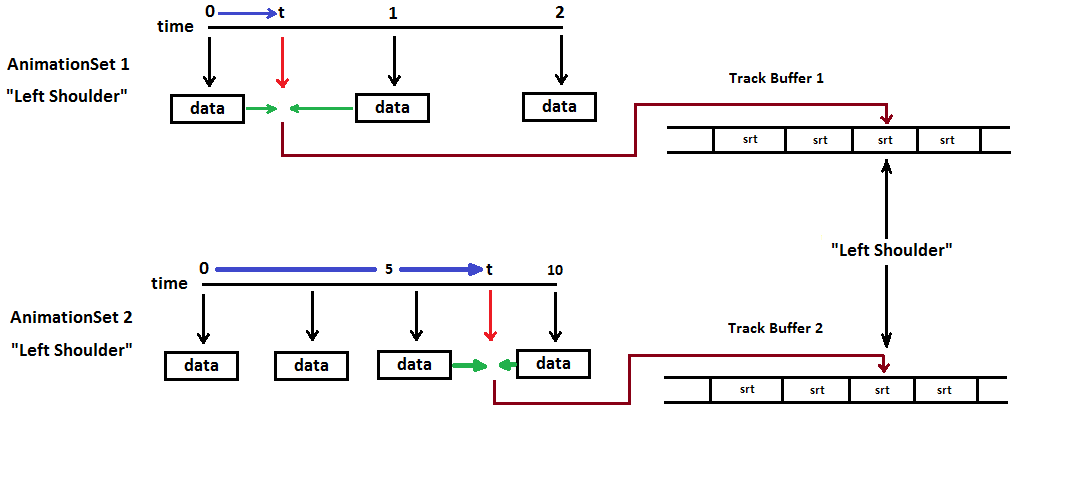
t has been incremented (in real-time) to a value between 0 (when the animation started) and 1 (the next key frame time). The animation controller is going to do a calculation to provide data to be used for rendering the character. The expected result should be something "more" than time 0, but "less" than time 1. In a sense, the animation controller will calculate its own "key frame" data.
![Attached Image: animctlr 2.png]()
The animation controller, given time
t, searches for a pair of
sequential key frames: one with a key frame time less than
t (the time "0" data), and one with a key frame time greater than
t (the time "1" data.) Using the example illustrated above, the animation controller uses data from key frame 0 and key frame 1 to interpolate data (the green arrows) for calculating the animation matrix.
// The key frames have been search and returned:
// keyFrameBefore = 0
// keyFrameAfter = 1
Quaternion quatBefore = key[keyFrameBefore].quaternion;
Quaternion quatAfter = key[keyFrameAfter].quaternion;
Now the question becomes: how much of "keyFrameBefore" and how much of "keyFrameAfter" should be used to determine the data for time
t?
The ratio of those amounts is the fraction of the
interval between timed key frames at which time
t appears.
// Determine the fraction of the time between the two frames represented by t.
float ratio = ( t - key[keyFrameBefore].time )/( key[keyFrameAfter].time - key[keyFrameBefore].time );
Now the two key frame quaternions can be interpolated:
// The SLERP function (a math utility) returns a quaternion based on
// ratio * quatBefore and (1.0 - ratio) * quatAfter.
// HOWEVER: know your math libraries! Some SLERP functions
// may calculate the result using (1.0 - ratio)*quatBefore and ratio*quatAfter
//
Quaternion quatAtTimeT = SLERP( quatBefore, quatAfter, ratio );
MATRIX4X4 animMat = MatrixFromQuaternion( quatAtTimeT ) );
Frame* frame = FindFrameWithName( keyFrame.BoneName );
frame->TransformationMatrix = animMat;
Quaternions can also be
interpolated using NLERP (
Non
Linear int
ERPolation). NLERP is generally faster than SLERP, but is a linear approximation of a second order calculation. Though LERP can be used, it may not provide visual results as close to SLERP calculations as may be desired if the rotations between timed key frames are "large." The decision to LERP or SLERP will likely be a compromise resulting from considerations of the smoothness of the animation and performance requirements.
Blending AnimationSets
The preceding portion of this article describes the process for calculating transforms for a single character animationset. More often, the character will walk for a while, then run, then perhaps raise or aim a weapon and fire. Those actions may be separate animation sets created by the modeler. The animation controller should be capable of switching from one animation set to another: walk, then run, then shoot.
That can easily be done by the animation controller by simply changing from one animation set (array of timed key frames) to another. However, that will result in the character instantaneously switching from a walk to a run, followed by an instantaneous change from a run to a static shooting pose. A better approach is for the animation controller to provide a smooth transition from a walk to a run, as if the walking character begins to speed up until it's running.
That involves
blending the results from two (or more) animation sets before the results are returned for rendering.
A simple approach to accomplish that blending is to interpolate the key frames from
two animation sets and calculate the animation transform from that interpolation. That is, perform the key frame interpolation calculations for two animation sets separately using time
t appropriate to
each animation, but, instead of calculating animation matrices, store the interpolated quaternions and vectors in key frame structures
as if they were key frames. Then combine those
two sets of key frames and calculate the animation transforms from that (see the illustration under Animation Track below.) The determination of "how much of anim set 0" and "how much of anim set 1" is specified by a
blend factor. A blend factor is changed from 0 to 1, and the result will be to use all
walk animations for blend factor = 0, use
some of walk and
some of run for blend factor between 0 and 1, and (finally) use
all of the run animations when blend factor = 1 to render the character. Further, when that
blend factor reaches 1, stop processing the walk animation set. For the sake of simplicity, that's the process this article will discuss further.
Limitations of A Simple Blend
There are several ways in which two animation sets can be combined. The animation controller must be implemented with just one method, or provide for choosing among the possibilities.
A. The animation sets can be
interpolated using the
blend factor in just the same way that the
ratio was used to interpolate timed key frames. A little bit walking, a little bit running. However, if, at the time the blend begins, the walking character is raising its left leg, and the run animation begins with the character raising its
right leg, the result may be that the character lifts
both legs a little bit at the same time. Further more, the period of the walk animation set will likely be different than the period of the run animation. Transitioning from one leg to another will take a different amount of real-time for each animation set, creating motions that will likely not be satisfactory. In spite of those limitations, the interpolation form of blending is the one that will be discussed in this article, noting that it generally provides results that can be lived with, provided that the transition time (how much real-time it takes for the blend factor to change from 0 to 1) is sufficiently short. From Shakespeare's Macbeth, Scene VII: "If it were done when 'tis done, then 'twere well It were done quickly."
B. Animation sets can be
added together. That is, perform a simple addition of the SRTs in the two interpolated key frames, and calculate the animation matrix. If animation sets are specifically designed for just such blending, the result could be, for instance, a shooting animation for the upper part of the character and a running animation for the lower part. Experimentation (perhaps extensive) by the modeler and programmer may be required to establish modeling and export rules which will produce the imported data the animation controller has been coded to process.
C. Animation sets can be
subtracted from one another, possibly reversing the action of a previous addition.
Choices B and C place special requirements on the form of the key frame data which may be appropriate for custom applications. However, as they are not generic, they do not fit the purpose of this article.
Animation Tracks
For a single animation set, key frame data is interpolated and an animation matrix calculated which is immediately stored back in the frame hierarchy.
If two animation sets are being blended, the interpolated key frame data must be stored in an intermediate location until blending of the two sets can be done. To provide an intermediate location, the concept of an
animation track is introduced.
An animation track has an animation set associated with it, and provides, along with some other information, a buffer or array sized to hold key frame data for every frame (AKA bone, node) in the hierarchy. When key frames for it's associated animation set are interpolated, the interpolated quaternions and vectors (SRT) are copied to that buffer in a specific (indexed) position determined by the frame- or bone-name associated with the key frame data.
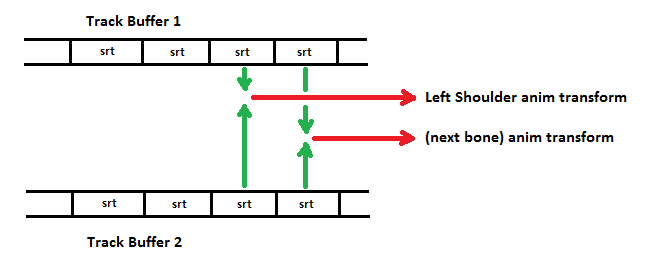
In illustration
A below, two animation sets are to be blended. Each animation set has an associated track buffer to hold key frame interpolation results. For animation set 1, at time
t for that animation set, an interpolation is made (green arrows) from key frame data for a particular bone ("Left Shoulder"), and the interpolated scale, rotation and translation values (srt) are stored (dark red arrow) in track buffer 1, in the buffer position (index) specific to "Left Shoulder." Each bone animation in the animation set goes through the same process, and the interpolated data is stored in a specific buffer index determined by the bone-name. Similarly, animations are interpolated for animation set 2 and stored in track buffer 2. The interpolated SRT values for "Left Shoulder" are at the same indexed position in each track buffer. After key frames have been processed for
both animation sets, (see illustration
B below) the SRTs for each bone are blended (green arrows), the animation transform is calculated and stored in the frame hierarchy (red arrows).
Illustration
A below also emphasizes that animation sets may be progressing at different rates and be at different times within their sequence. Also, the key frame data for different animation sets may vary in time values and number of key frames.
A. Interpolate key frame data and store in the track buffer.![Attached Image: track buffers.png]() B. Blend key frame data from two animation sets and calculate animation transforms.
B. Blend key frame data from two animation sets and calculate animation transforms.![Attached Image: track buffers 2.png]()
Animation Controller Code
The pseudo-code sprinkled about this article appears as C++ style code and STL implementations. The code is
not intended to be compilable; its purpose is to provide programmers with ideas for specific implementation of an animation controller. The example pseudo-code specifically uses data structures, calculation methods, data access and storage locations discussed above to allow the reader to see an example of those concepts implemented in code. The pseudo-code is adapted from working code implemented in DirectX 9.0c, Windows 7, using a custom file loader for Microsoft DirectX x-file format, models created in and exported from Blender 2.69.
In the context of this article, animation data is arranged in an array of arrays, and can be implemented using something similar to the following.
struct AnimationKey {
float time;
Quaterion quat;
Vector scale, trans;
};
struct Animation {
String frameName; // bone-name, node-name
// trackKeyIndex is the index in AnimTrack.trackKeys for interpolated timedKeys
// for this particular frame/bone/node
int trackKeyIndex;
float maxTime; // used for checking conistency among Animations in an animationset
std::vector<AnimationKey> animKeys;
};
struct AnimationSet {
bool checkedAgainstRootFrame; // used to verfiy the compatibility with the frame hierarchy
String animationSetName; // maybe "Walk," "Run," "Idle," or other convenient description.
std::vector<Animation> animations;
double currentTime, period; // the current time ("t" in the above discussions) and the period
};
struct RootFrame {
bool checkedAgainstAnimationSets;
Frame* _hierarchyRootFrame;
};
// parameters that may be useful for a particular animation set
struct AnimTrackDesc
{
float speed; // allows for displaying animations faster or slower than as-modeled. Not discussed.
bool enable; // determines whether the animationset key frames are to be processed.
};
// when 2 animationsets are to be blended, a BlendEvent is initiated
// describing which track buffers are to be used for the blend
struct BlendEvent
{
DWORD fromTrack, toTrack; // which buffers
float transitionTime; // how long the transition takes
float curTime; // how far along in the transition time
};
struct AnimTrack
{
DWORD animSet; // animationSet currently assigned to this track
std::vector<AnimationKey> trackKeys; // the track buffer
AnimTrackDesc desc;
};
Some of the data in the structures above, such as the
bools indicating whether checks have been made, are not directly related to calculation of animation transforms. An animation set can be imported independently of the frame hierarchy to be animated, either before or after the frame hierarchy is built. Those bools are reminders that the animation data
must match the frame hierarchy bone-name-for-bone-name. When those checks are made (or even ignored) is up to the programmer.
Several animation sets may be loaded into the animation controller as desired. An animation set doesn't
have to be associated with a track. The animation controller interface should provide Get/Set methods for a particular track description, for determining which animation set is currently associated with a track, etc.
An animation controller class may contain methods and data as follows. Many of the methods shown below are not discussed in this article, but are intended as suggestions for methods that may be useful in the implementation of the animation controller, or to provide information for interfacing the animation controller. Note that functions should provide an indication of success or failure.
class AnimController
{
public:
AnimController();
~AnimController();
// public methods
bool Init();
bool AdvanceTime(double deltaTime);
bool SetHierarchy(Frame* newRootFrame);
bool SetTicksPerSecond(DWORD newTicks, DWORD whichAnimationSet);
DWORD GetNumAnimationSets() { return _animSets.size(); }
bool GetAnimationSetName(DWORD animSetNum, std::string& animName);
DWORD GetNumTracks() { return _animTracks.size(); }
bool TrackSetAnimationSet(DWORD animSetNum, int trackNum);
bool TrackSetAnimationSet(std::string animSetName, int trackNum);
DWORD CreateTrack(AnimTrackDesc* trackDesc); // returns the index for the new track
bool DeleteTrack( DWORD trackNum );
bool GetTrackDescription( DWORD trackNum, AnimTrackDesc* trackDesc);
bool SetTrackDescription( DWORD trackNum, AnimTrackDesc* trackDesc);
bool GetTrackEnable(int trackNum);
bool SetTrackEnable(int trackNum, bool enable);
bool TransitionTracks(DWORD fromTrack, DWORD toTrack, float transitionTime); // start a blend event
DWORD GetNumBlendEvents() { return _trackEvents.size(); }
bool GetBlendEvent(DWORD eventNum, BlendEvent* event);
protected:
bool initialized;
// methods
// CheckCompatibility - ensures the root frame hierarchy frameNames
// match the frameNames in the animation sets. Specific implementation
// of this method is not discussed in this article.
bool CheckCompatibility(); // are the animation sets applicable to the frame hierarchy?
bool BuildFrameNameIndex(); // sets Animation::trackKeyIndex
bool SetCurTicks(DWORD animSetNum);
bool InterpolateAnimations(Animation& anim, double fTime, std::vector<AnimTrackKey>& trackKeys);
bool InterpolateKeyFrame(AnimationKey& animKey, double fTime);
// attributes
RootFrame _rootFrame; // frame hierarchy access (for storing matrices, finding names, etc.
std::vector<AnimationSet> _animSets; // all the animation sets available
std::vector<AnimTrack> _animTracks; // all the tracks
std::vector<BlendEvent> _trackEvents; // information for blending animation sets
std::vector<std::string> frameNames; // this of hierarchy frame names used to index into track buffers
};
The
AdvanceTime function provides an overview of the entire process. In its simplest form, an animation controller would animate just
one animation set, or
one blend event. However, the structures and
AnimController class as shown provide for later flexibility. The implementation below does not perform error-checking to enforce the assumption that just one track is enabled for processing, or that just one blend event is being processed. That bookkeeping (which tracks are enabled, what animation set is associated with which track, what blending events are currently in progress, etc.) is left to the rendering routine using
animController->AdvanceTime(...) to generate data for rendering.
//
// advance the time.
// calculate animation matrices and store matrices in hierarchy TransformationMatrix
// deltaTime is NOT the elapsed game time, but the change in time since the last render cycle time
// For many applications, this is the same delta-time used to update other scene objects.
//
bool AnimController::AdvanceTime(double deltaTime)
{
if (!initialized) return false;
// If an animation controller is intended to process just one track, or just one blend event
// this section of code can be revised to enforce that assumption.
// The code presented here allows for generalizing "track events" to do more
// than just blending two animation sets
for (int track = 0; track < (int)_animTracks.size(); track++) // check the status of all tracks
{
// animation sets are rendered only when the associated track is enabled
// Also check that the animation set associated with the track is "valid"
if (_animTracks[track].desc.enable && _animTracks[track].animSet < _animSets.size())
{
UINT animSetNum = _animTracks[track].animSet; // variable convenient for looping
// advance the local time for the animation set.
_animSets[animSetNum].currentTime += deltaTime;
// adjust the time if necessary. See SetCurTicks code below
if (!SetCurTicks(animSetNum)) return false;
// loop through animations
for (size_t i = 0; i < _animSets[animSetNum].animations.size(); i++)
{
if( !InterpolateAnimations(_animSets[animSetNum].animations[i],
_animSets[animSetNum].currentTime, _animTracks[track].trackKeys) )
return false; // something went wrong
}
}
}
MATRIX rot, scale, translate; // parameters used for interpolating
// The concept for this animation controller is to:
// Process A Blend Event
// OR
// Process a single track
//
// Though _trackEvents allows for other types of blending
// and events, for the purpose of this article it is assumed
// that there will be either 0 or just 1 blend occurring at a time
if (_trackEvents.size())
{
_trackEvents[0].curTime += deltaTime; // bump the progression of the blend
if (_trackEvents[0].curTime > _trackEvents[0].transitionTime) // done with this event
{
SetTrackEnable(_trackEvents[0].fromTrack, false); // disable the "from" animation set
// delete the event
_trackEvents.clear();
}
else
{
// to reduce the clutter of the calcuations, an iterator is used ONLY
// for clarity. iter is, in fact, just _trackEvents[0].
std::vector<BlendEvent>::iterator iter = _trackEvents.begin();
float blendFactor = float(iter->curTime / iter->transitionTime);
// get the buffers for both the "from" track and the "to" track
std::vector<AnimationKey>& vFrom = _animTracks[iter->fromTrack].trackKeys;
std::vector<AnimationKey>& vTo = _animTracks[iter->toTrack].trackKeys;
// declare variables to use in the blending
Quaternion quatFinal, quatFrom, quatTo;
Vector scaleFinal, scaleFrom, scaleTo, translateFinal, translateFrom, translateTo;
// loop through every animation, blend the results of the two animation sets
// and send the animation matrix off to the frame hierarchy
for (DWORD tk = 0; tk < vFrom.size(); tk++) // trackKeys.size() are all the same size
{
// grab values from the track buffers
quatFrom = vFrom[tk].quat; quatTo = vTo[tk].quat;
scaleFrom = vFrom[tk].scale; scaleTo = vTo[tk].scale;
translateFrom = vFrom[tk].trans; translateTo = vTo[tk].trans;
// blend the quats, scales, and translations. Calculate the animation matrices.
// The following line demonstrates possible concatenations IF the function
// forms allow it.
MatrixFromQuaternion(&rot, QuaternionSlerp(&quatFinal, &quatFrom, &quatTo, blendFactor));
// a bit more formally, calculate the blended scale
scaleFinal = (1.0f - blendFactor)*scaleFrom + blendFactor * scaleTo;
// calulate the blended translation
translateTo = (1.0f - blendFactor)*translateFrom + blendFactor * translateTo;
// create the scale and translation matrices
MatrixScaling(&scale, scaleFinal.x, scaleFinal.y, scaleFinal.z);
MatrixTranslation(&translate, translateFinal.x, translateFinal.y, translateFinal.z);
// find the frame in the hierarchy with the name equivalent to the animation
// The array "frameNames" is assumed to be an array of frame names in indexed order
Frame* frame = FrameWithName(frameNames[tk], _rootFrame._hierarchyRootFrame);
if (frame == NULL)
return false; // GLOBALMSG
// calculate and store the animation matrix.
frame->TransformationMatrix = rot * scale * translate;
}
}
}
// if a blend is not progress, just update animations from the (hopefully) only enabled track
else
{
// set Transformation matrix with track results
for (DWORD track = 0; track < _animTracks.size(); track++)
{
if (_animTracks[track].desc.enable)
{
std::vector<AnimTrackKey>& v = _animTracks[track].trackKeys;
for (DWORD tk = 0; tk < v.size(); tk++)
{
MatrixFromQuaternion(&rot, &v[tk].quat);
MatrixScaling(&scale, v[tk].scale.x, v[tk].scale.y, v[tk].scale.z);
MatrixTranslation(&translate, v[tk].trans.x, v[tk].trans.y, v[tk].trans.z);
Frame* frame = FrameWithName(frameNames[tk], _rootFrame._hierarchyRootFrame);
if (frame == NULL) return false; // GLOBALMSG?
frame)->TransformationMatrix = rot * scale * translate;
}
}
}
}
return true;
}
The
SetCurTicks function shown here advances the time for an animation set and specifically loops the animation from beginning to end by ensuring the current time for the animation set is between 0 and the period of the animation set.
//
// the function name is a carry over from earlier implementations
// when unsigned integers for key frame times were used.
//
bool AnimController::SetCurTicks(DWORD animSetNum)
{
if (animSetNum >= _animSets.size()) return false; // error condition
// convenient variables for clarity.
// Also easier than coding "_animSets[animSetNum].xxx" multiple times
float curTime = _animSets[animSetNum].currentTime; // was just bumped in AdvanceTime
float period = _animSets[animSetNum].period;
// NOTE: the following will cause the animation to LOOP from the end of the animation
// back to the beginning.
// Other actions which could be taken:
// - ping-pong: at the end of an action, reverse back through the keyframes to the beginning, etc.
// - terminate the animation: perhaps provide a callback to report same
while ( curTime >= period ) curTime -= period; // loop within the animation
// the result of this routine should be that
// currentTime is >= 0 and less than the period.
_animSets[animSetNum].currentTime = curTime;
return true;
}
An implementation of
InterpolateAnimations(...) is shown below.
// this routine finds a pair of key frames which bracket the animation time.
// Interpolated values are calculated and stored in the the track buffer (trackKeys)
bool AnimController::InterpolateAnimations(Animation& anim, float fTime,
std::vector<AnimKey>& trackKeys);
{
Quaternion quat;
if (anim.animKeys.size() > 1) // more than just a time==0 key
{
// find timedkey with time >= fTime
DWORD i = 0;
// find a pair of key frames to interpolate
while ( i < animKeys.size() && animKeys[i].time < fTime ) i++;
if ( i >= animKeys.size() ) // should not happen, but handle it
{
i = animKeys.size()-1; // use the last keyframe
fTime = animKeys[i].time;
}
// animKeys[i].time >= fTime. That's the keyframe after the desired time
// so animKeys[i-1] is the keyframe before the desired time
if ( i > 0 )
{
float ratio = (fTime - animKey[i-1].time) / (animKey[i].time - animKey[i-1].time);
Slerp or NLerp(&quat, &animKey[i-1].quat, &animKey[i].quat, ratio);
trackKeys[anim.trackKeyIndex.quat = quat;
trackKeys[anim.trackKeyIndex].scale =
(1.0f-ratio)*animKey[i-1].scale + ratio * animKey[i].scale;
trackKeys[anim.trackKeyIndex].trans =
(1.0f-ratio)*animKey[i-1].trans + ratio * animKey[i].trans;
}
else // use the time=0 keyframe
{
trackKeys[anim.trackKeyIndex].quat = animKey[0].quat;
trackKeys[anim.trackKeyIndex].scale = animKey[0].scale;
trackKeys[anim.trackKeyIndex].trans = animKey[0].trans;
}
}
return true;
}
There are a lot of parts to the animation controller which don't relate directly to interpolation of key frames or blending of animations. Here are a few details that may be useful.
// set up the blending of two tracks
bool AnimController::TransitionTracks(DWORD fromTrack, DWORD toTrack, float transitionTime)
{
if (fromTrack >= _animTracks.size() || toTrack >= _animTracks.size()
|| fromTrack == toTrack || transitionTime < 0.0f) return false; // error condition
BlendEvent blendEvent;
blendEvent.fromTrack = fromTrack;
blendEvent.toTrack = toTrack;
blendEvent.transitionTime = transitionTime;
blendEvent.curTime = 0.0f;
_trackEvents.push_back(blendEvent);
SetTrackEnable(fromTrack, true);
SetTrackEnable(toTrack, true);
return true;
}
// This routine should be used when _rootFrame._hierarchyRootFrame has been set and animation sets
// have been loaded. Must be done before any use of AdvanceTime.
// You may want to tie this routine to the requirements to be considered "initialized."
bool AnimationController::BuildFrameNameIndex()
{
frameNames.clear(); // start clean
// work through the frame hierarchy, storing the name of each frame name
AddFrameName( _rootFrame._hierarchyRootFrame );
// now that all names in the hierarchy have been found,
// loop through the animations, checking names and setting the track buffer index
for( DWORD animSet = 0; animSet < _animSets.size(); animSet++)
{
for( DWORD anim = 0; anim < _animSets[animSet].animations.size(); anim++ )
{
if( (_animSets[animSet].animations[anim].trackKeyIndex =
IndexForFrameName( _animSets[animSet].animations[anim].frameName )) < 0 ) return false;
}
}
return true;
}
// doesn't appear in class methods above, but requires access to frameNames.
void AnimationController::AddFrameName( Frame* frame )
{
frameNames.pushback( std::string(frame->frameName) );
for each Child in frame:
AddFrameName( Child );
}
// doesn't appear in class methods above, but requires access to frameNames.
int AnimationController::IndexForFrameName( std::string& frameName )
{
for( int i=0; i < (int)frameNames.size(); i++ )
{
if( frameNames[i] == frameName ) return i;
}
return -1; // name not found
}
Disclaimer and Improvements
As mentioned above, the pseudo-code provided is to illustrate implementation of a concept, and is not at all intended to represent an efficient or optimized process. There are several repetitions of similar code such as the interpolation calculations which could be improved. Improvement can certainly be made in the process for accessing frame-names and setting trackbuffer indices in
Animations. The example code uses the track buffer to calculate for the final animation transform whether a blend event is in progress or not. The
InterpolateAnimations routine can be revised to directly calculate the animation transform and store in the frame hierarchy (rather than storing key frame components in the track buffer for later processing). That modification can be done if the intent is process just one animation set if a blend is not in progress.
And, once again, the code is not intended to be compilable.
More Possibilities
Applications often include sound or graphics effects related to character actions - footstep sounds, muzzle flashes, etc. Those effects directly tie to the character animation. Besides just blending two animation sets, the
BlendEvent structure and implementation can be expanded (perhaps to a "track" or "animation" event) to provide feedback to the application at a particular time in an animation set, e.g., "left/right foot down" or "weapon fired."
Other events that may be useful may include scheduling an animation set or track change at a future time, perhaps at the end of a track for another animation. I.e., "start running again after firing a weapon."
Summary
An animation controller for a skinned mesh can be implemented with an understanding of
what data will be used, and the limitations accompanying the choices of
how that data will be used.
An animation controller can be implemented using the principle of "separation of tasks." Only a minimum amount of "knowledge" regarding a frame hierarchy is needed.
Two animation sets can be blended mathematically to provide for a transition from one action to another. Discussions between the modeler and the programmer may be required for successful implementation.
Coding a practical implementation for an animation controller will require additional function definitions to initialize data and provide the needed interface to be used in an application.
Article Update Log
Keep a running log of any updates that you make to the article. e.g.
6 Mar 2014: Basic information outlined.
7 Mar 2014: Sections expanded. Code samples included. Illustrations added.
8 Mar 2014: Add'l code examples added. Rearranged article parts.
9 Mar 2014: Final grooming. Published. Awaiting approval.
10 Mar 2014: Moderator appproval. In Peer Review