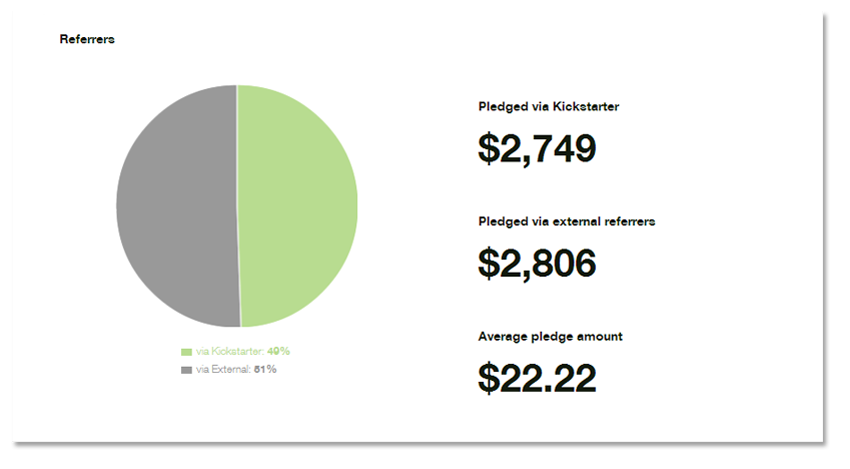
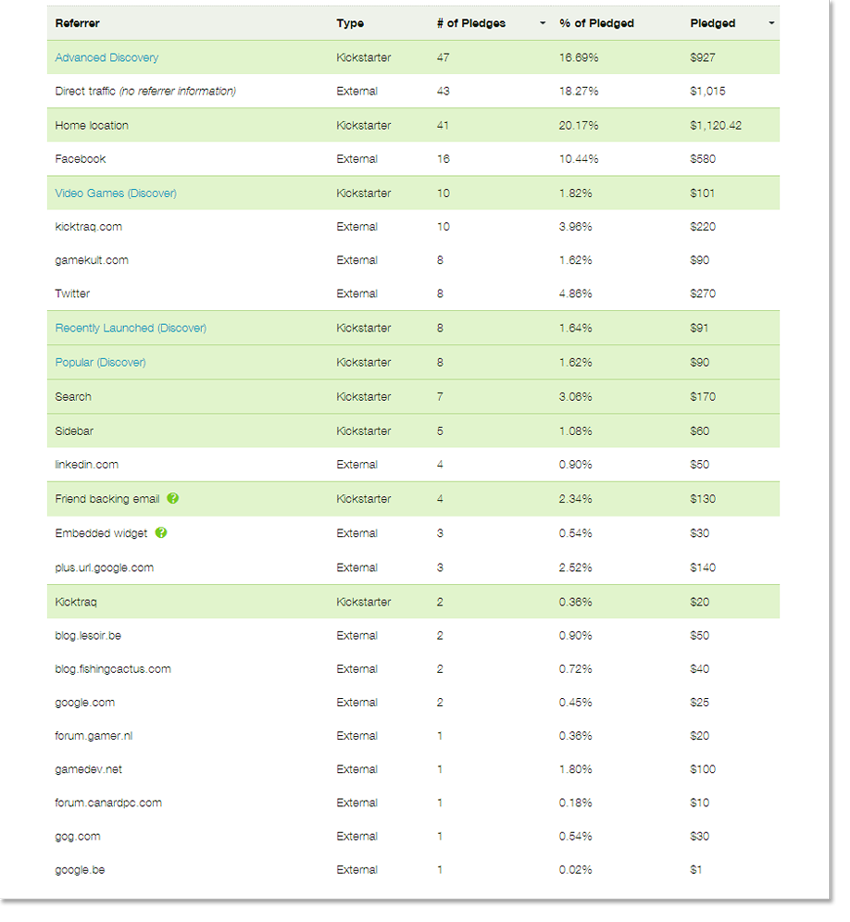
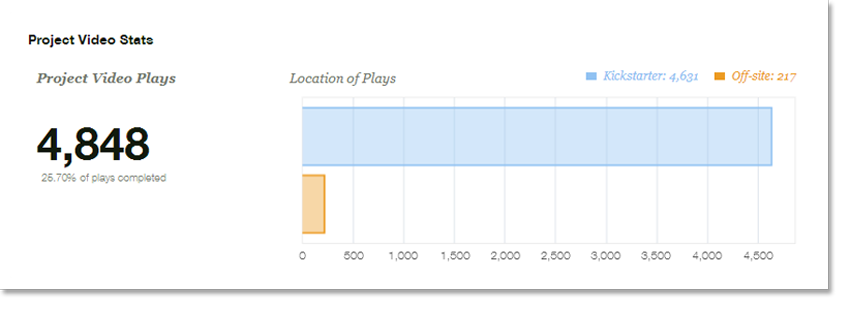
DirectX 9 is good! It allows you to import .x files into your game projects unlike newer versions of DirectX. Why not ask yourself, "What do I want in my game?" well, the answer for me is 3D game characters and a nice 3D scene. I am writing this tutorial so that you may follow the steps required to create such a scene. Well at least the characters. I’ll leave the scene up to you. The scene will serve as an area for our characters to walk around. Unfortunately 3D studio max is not free for many people. I have no answer for this because I was unsuccessful in using Blender for animations; maybe now that I have experience I'd manage however if you are able to get hold of max, then great! There's nothing stopping you. There are plugin exporters available that do the job. And the aim of this tutorial is purely for teaching you how to create 3D DirectX games using any of the exporters available and as a refresher course for myself. DirectX is not easy but it is a lot of fun. So let's get started!
Note: If you are familiar with the basics of setting up DirectX and Win32 applications, then you can skip straight to discussions of loading and animating models
Setting up Direct3D
Note: if you are using a unicode character set for your projects, be sure to place an L before strings e.g. L"my string";
Let's start from the beginning: Creating a window. Setup a new empty Win32 project in Visual Studio; you will need a version of the DirectX SDK and to link in the include and library directories of the SDK into your project. This is done via project properties. In the linker->Input Additional dependencies add d3d9.lib and d3dx9.lib.
First we will include
<windows.h> and create a
WinMain() function and a Windows procedure
WinProc().
WinMain is the entry point of the program that is executed first in a standard Windows application. Our
WinMain function is outlined as:
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, PSTR cmdLine, int showCmd);
And the outline of our
WndProc is:
LRESULT CALLBACK WndProc(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam);
Place these declarations at the top of the cpp file after includes so that they can be referenced throughout other functions.
Now we will want an object to handle various application events such as game initialization, updating the game and cleaning of resources. We will create a simple
Game object for this. Within the
Init() function we will create a window and hold a handle to it,
m_mainWindow:
class Game{
public:
Game();
~Game();
HRESULT Init(HINSTANCE hInstance);
void Update(float deltaTime);
void Cleanup();
private:
HWND m_mainWindow;
};
Don't forget the semi-colon after class declaration.
We create the window class that describes our window and register it with the operating system in the
Game::Init() function. We will use a basic window class for this:
WNDCLASS wc;
//Prepare class for use
memset(&wc, 0, sizeof(WNDCLASS));
wc.style=CS_HREDRAW | CS_VREDRAW; //Redraws the window if width or height changes.
//Associate the window procedure with the window
wc.lpfnWndProc=(WNDPROC)WndProc;
wc.hInstance=hInstance;
wc.lpszClassName="Direct3D App";
Register the window class with the OS:
if(FAILED(RegisterClass(&wc))){
return E_FAIL;
}
And finally, create the window; We use
WS_OVERLAPPEDWINDOW for a standard minimize, maximize and close options:
m_mainWindow = CreateWindow("Direct3D App", //The window class to use
"Direct3D App", //window title
WS_OVERLAPPEDWINDOW, //window style
200, //x
200, //y
CW_USEDEFAULT, //Default width
CW_USEDEFAULT, //Default height
NULL, //Parent Window
NULL, //Menu
hInstance, //Application instance
0); //Pointer to value parameter, lParam of WndProc
if(!m_mainWindow){return E_FAIL;}
And after CreateWindow, add:
ShowWindow(m_mainWindow, SW_SHOW);
UpdateWindow(m_mainWindow);
//Function completed successfully
return S_OK;
In the
WinMain function we must create an instance of
Game and call the
Init function to initialize the window:
Game mygame;
if(FAILED(mygame.Init(hInstance))){
MessageBox(NULL, "Failed to initialize game", NULL, MB_OK);
return 1;
}
Every Windows application has a message pump. The message pump is a loop that forwards Windows messages to the window procedure by "looking" or peeking at the internal message queue. We "look" at a message within our message pump, remove it from the queue with
PM_REMOVE and send it to the window procedure typically for a game.
PeekMessage is better than
GetMessage in the case where we want to execute game code because it returns immediately.
GetMessage on the other hand would force us to wait for a message.
Now for our message pump; place this in the
WinMain function:
MSG msg;
memset(&msg, 0, sizeof(MSG));
while(WM_QUIT != msg.message){
while(PeekMessage(&msg, 0, 0, 0, PM_REMOVE) != 0){
//Put the message in a recognizable form
TranslateMessage(&msg);
//Send the message to the window procedure
DispatchMessage(&msg);
}
//Update the game
//Don't worry about this just now
}
At the end of
WinMain, call the application cleanup function and return with a message code:
mygame.Cleanup();
return (int)msg.wParam;
Now for our window procedure implementation; We will use a basic implementation to handle messages:
LRESULT CALLBACK WndProc(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam){
//Handle window creation and destruction events
switch(msg){
case WM_CREATE:
break;
case WM_DESTROY:
PostQuitMessage(0);
break;
}
//Handle all other events with default procedure
return DefWindowProc(hWnd, msg, wParam, lParam);
}
Check that the program works so far. You should be able to build the project and run it and display the window. If all goes well, we can start with Direct3D.
Now that we have created a window, let's setup Direct3D and render a background colour to the screen. We will add to our
Game object so we can easily work with different parts of our application in a clear and secure manner such as creation, updating the game and application destruction. With our game object we can intialize Direct3D in an
Init() function and update our game with
Game::Update() and clean up DirectX resources with
Game::Cleanup(). Name this class to suit your preference. I will call it
Game. The
m_ prefix is Hungarian notation and was developed by someone called Charles Simonyi, a Microsoft programmer. It is short for member variable. Other prefixes might be
nCount,
n for number,
s_ for static variables. Anyway here is the
Game object with added functions and variables specific to Direct3D:
#include "d3d9.h"
#include "d3dx9.h"
class Game{
public:
Game();
~Game();
HRESULT Init(HINSTANCE hInstance);
void Update(float deltaTime);
void Render();
void Cleanup();
void OnDeviceLost();
void OnDeviceGained();
private:
HWND m_mainWindow;
D3DPRESENT_PARAMETERS m_pp;
bool m_deviceStatus;
};
Further reading recommended:
Character Animation with Direct3D - Carl Granberg We could do with a helper function to release, free up memory used by DirectX COM objects in a safe manner. We use a generic template class for this or you could create a macro for the same purpose:
dxhelper.h
template<class T>
inline void SAFE_RELEASE(T t)
{
if(t)t->Release();
t = NULL;
}
Don't forget to include it in your main cpp file.
#include "dxhelper.h" In our
Init function we fill out the present parameters and setup Direct3D;
HRESULT Game::Init(){
//... Window Creation Code Here
//...
//Direct3D Initialization
//Create the Direct3D object
IDirect3D9* d3d9 = Direct3DCreate9(D3D_SDK_VERSION);
if(d3d9 == NULL)
return E_FAIL;
memset(&m_pp, 0, sizeof(D3DPRESENT_PARAMETERS));
m_pp.BackBufferWidth = 800;
m_pp.BackBufferHeight = 600;
m_pp.BackBufferFormat = D3DFMT_A8R8G8B8;
m_pp.BackBufferCount = 1;
m_pp.MultiSampleType = D3DMULTISAMPLE_NONE;
m_pp.MultiSampleQuality = 0;
m_pp.SwapEffect = D3DSWAPEFFECT_DISCARD;
m_pp.hDeviceWindow = m_mainWindow;
m_pp.Windowed = true;
m_pp.EnableAutoDepthStencil = true;
m_pp.AutoDepthStencilFormat = D3DFMT_D24S8;
m_pp.Flags = 0;
m_pp.FullScreen_RefreshRateInHz = D3DPRESENT_RATE_DEFAULT;
m_pp.PresentationInterval = D3DPRESENT_INTERVAL_IMMEDIATE;
if(FAILED(d3d9->CreateDevice(D3DADAPTER_DEFAULT,
D3DDEVTYPE_HAL,
m_mainWindow,
D3DCREATE_HARDWARE_VERTEXPROCESSING,
&m_pp,
&g_pDevice)))
return E_FAIL;
//We no longer need the Direct3D object
SAFE_RELEASE(d3d9);
//Success the Direct3D device was created
return S_OK;
}
Let's go over the parameters quickly;
BackBufferWidth specifies the width of the offscreen buffer, the back buffer. The offscreen buffer is a memory segment that we render a scene to and it becomes the on-screen buffer, what we actually see on the screen when it is flipped with the front buffer, the on-screen buffer. Similarly with the
BackBufferHeight. We specify 8 bits for alpha, 8 bits for red, 8 bits for green and 8 bits for blue so this is 32-bit true colour allocated for our buffer. We specify that there will only be one back buffer; the reason we might have two back buffers is to speed up the rendering to the screen e.g. while the onscreen buffer is diplayed you could prepare two offscreen buffers so you could flip one and then the next is ready to be displayed so you could flip the other immediately. Multisampling is a technique that improves the quality of an image but takes up more processing time. So we specify
D3DMULTISAMPLE_NONE. We specify
SWAPEFFECT_DISCARD to remove the oncreen buffer when it is swapped with a backbuffer; so the backbuffer becomes the front and the old front is deleted.
m_pp.hDeviceWindow is the window to render to.
Windowed can be
true, displaying the scene in a window, or
false to display the scene fullscreen. We set
m_pp.EnableAutoDepthStencil to
true to enable depth bufferring; where a depth buffer is used effectively causes 3D objects in the world to overlap correctly; a z value will be specified for each pixel of the depth buffer and this will effectively enable depth testing which is basically a test comparison of the z value of each pixel; If a pixel's z value is less, nearer to the screen, than another pixels z value, it is closer to the screen so will be written to the offscreen buffer. We use a default refresh rate and immediate buffer swapping. The other type of buffer swapping could be
D3DPRESENT_INTERVAL_DEFAULT, default interval, which might be the screen refresh rate.
Next we create the device with a call to
d3d9->CreateDevice().
We need to specify a global Direct3D device object so that we can use the device anywhere in the program.
IDirect3DDevice9* g_pDevice = NULL;
Then the
CreateDevice() function will create the device object. We use the default display adapter and then
D3DDEVTYPE_HAL to use the hardware abstraction layer, hardware graphics acceleration for our rendering of the scene. This is much faster as opposed to software rendering. Hardware means the graphics card in this case. We specify to use hardware vertex processing too. And then we pass the present parameters structure that describes properties of the device to create. And lastly we pass the
g_pDevice variable to retrieve a handle to the newly created device.
Now, before we continue with animation we must do a bit of device handling. For example if the user does ALT+TAB our device might be lost and we need to reset it so that our resources are maintained. You'll notice we have
onDeviceLost and
onDeviceGained functions in our game object. These will work hand-in-hand with the
deviceStatus variable to handle a device lost situation. After a device has been lost we must reconfigure it with
onDeviceGained().
To check for a lost device we check the device cooperative level for
D3D_OK. If the cooperative level is not
D3D_OK then our device can be in a lost state or in a lost and not reset state. This should be regularly checked so we will put the code in our
Game::Update() function.
#define DEVICE_LOSTREADY 0
#define DEVICE_NOTRESET 1
HRESULT coop = g_pDevice->TestCooperativeLevel();
if(coop != D3D_OK)
{
if(coop == D3DERR_DEVICELOST)
{
if(m_deviceStatus == DEVICE_LOSTREADY)
OnDeviceLost();
}
else if(coop == D3DERR_DEVICENOTRESET)
{
if(m_deviceStatus == DEVICE_NOTRESET)
OnDeviceGained();
}
}
Our
OnDeviceLost function and
OnDeviceGained look like:
void Game::OnDeviceLost()
{
try
{
//Add OnDeviceLost() calls for DirectX COM objects
m_deviceStatus = DEVICE_NOTRESET;
}
catch(...)
{
//Error handling code
}
}
void Game::OnDeviceGained()
{
try
{
g_pDevice->Reset(&m_pp);
//Add OnResetDevice() calls for DirectX COM objects
m_deviceStatus = DEVICE_LOSTREADY;
}
catch(...)
{
//Error handling code
}
}
When the program starts we have to set the
m_deviceStatus variable so that we can use it. So in our
Game::Game() constructor set the variable:
Game::Game(){
m_deviceStatus = DEVICE_LOSTREADY;
}
Now we need to implement the
Render and
Cleanup functions. We will just clear the screen and free up memory in these functions.
void Game::Render()
{
g_pDevice->Clear(0, NULL, D3DCLEAR_TARGET | D3DCLEAR_ZBUFFER, 0xff00ff00, 1.0f, 0);
if(SUCCEEDED(g_pDevice->BeginScene()))
{
// Perform some rendering to back buffer.
g_pDevice->EndScene();
}
// Swap buffers.
g_pDevice->Present(NULL, NULL, NULL, NULL);
}
void Game::Cleanup()
{
SAFE_RELEASE(g_pDevice);
}
Finally, we want to render our scene and update it. Remember the
Update() method handles device lost events.
We want our game to run with a consistent frame rate so that
Update() updates the game at the same frame rate on all PCs. If we just updated the game inconsistently without frame rate, our game would be faster on faster computers and slower on slower computers and also might speed up or slow down if we do not specify a frame rate.
Therefore we use
GetTickCount() and pass a change in time to our
Update() function.
GetTickCount() returns the number of milliseconds that have elapsed since the system was started. We record the start time, and subtract this from the current time of each iteration of the loop. We then set the new start time; repeat this calculation and get the change in time and pass this value to
Update(deltaTime).
Our message loop now is defined as:
//Get the time in milliseconds
DWORD startTime = GetTickCount();
float deltaTime = 0;
MSG msg;
memset(&msg, 0, sizeof(MSG));
while(msg.message != WM_QUIT){
if(PeekMessage(&msg, 0, 0, 0, PM_REMOVE)){
//Put the message in a recognizable form
TranslateMessage(&msg);
//Send the message to the window procedure
DispatchMessage(&msg);
}
else{
//Update the game
DWORD t=GetTickCount();
deltaTime=float(t-startTime)*0.001f;
//Pass time in seconds
mygame.Update(deltaTime);
//Render the world
mygame.Render();
startTime = t;
}
}
Now we have a complete Direct3D framework we can begin with loading an animated model. I will supply you the code so far and then talk about how we can load an animation hierarchy:
#include <windows.h>
#include "d3d9.h"
#include "d3dx9.h"
#include "dxhelper.h"
#define DEVICE_LOSTREADY 0
#define DEVICE_NOTRESET 1
IDirect3DDevice9* g_pDevice = NULL;
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, PSTR cmdLine, int showCmd);
LRESULT CALLBACK WndProc(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam);
class Game{
public:
Game();
~Game();
HRESULT Init(HINSTANCE hInstance);
void Update(float deltaTime);
void Render();
void Cleanup();
void OnDeviceLost();
void OnDeviceGained();
private:
HWND m_mainWindow;
D3DPRESENT_PARAMETERS m_pp;
bool m_deviceStatus;
};
Game::Game(){
m_deviceStatus = DEVICE_LOSTREADY;
}
Game::~Game(){
}
HRESULT Game::Init(HINSTANCE hInstance){
WNDCLASS wc;
//Prepare class for use
memset(&wc, 0, sizeof(WNDCLASS));
wc.style=CS_HREDRAW | CS_VREDRAW; //Redraws the window if width or height changes.
//Associate the window procedure with the window
wc.lpfnWndProc=(WNDPROC)WndProc;
wc.hInstance=hInstance;
wc.lpszClassName=L"Direct3D App";
if(FAILED(RegisterClass(&wc))){
return E_FAIL;
}
m_mainWindow = CreateWindow(L"Direct3D App", //The window class to use
L"Direct3D App", //window title
WS_OVERLAPPEDWINDOW, //window style
200, //x
200, //y
CW_USEDEFAULT, //Default width
CW_USEDEFAULT, //Default height
NULL,
NULL,
hInstance, //Application instance
0); //Pointer to value parameter, lParam of WndProc
if(!m_mainWindow){return E_FAIL;}
ShowWindow(m_mainWindow, SW_SHOW);
UpdateWindow(m_mainWindow);
//Direct3D Initialization
//Create the Direct3D object
IDirect3D9* d3d9 = Direct3DCreate9(D3D_SDK_VERSION);
if(d3d9 == NULL)
return E_FAIL;
memset(&m_pp, 0, sizeof(D3DPRESENT_PARAMETERS));
m_pp.BackBufferWidth = 800;
m_pp.BackBufferHeight = 600;
m_pp.BackBufferFormat = D3DFMT_A8R8G8B8;
m_pp.BackBufferCount = 1;
m_pp.MultiSampleType = D3DMULTISAMPLE_NONE;
m_pp.MultiSampleQuality = 0;
m_pp.SwapEffect = D3DSWAPEFFECT_DISCARD;
m_pp.hDeviceWindow = m_mainWindow;
m_pp.Windowed = true;
m_pp.EnableAutoDepthStencil = true;
m_pp.AutoDepthStencilFormat = D3DFMT_D24S8;
m_pp.Flags = 0;
m_pp.FullScreen_RefreshRateInHz = D3DPRESENT_RATE_DEFAULT;
m_pp.PresentationInterval = D3DPRESENT_INTERVAL_IMMEDIATE;
if(FAILED(d3d9->CreateDevice(D3DADAPTER_DEFAULT,
D3DDEVTYPE_HAL,
m_mainWindow,
D3DCREATE_HARDWARE_VERTEXPROCESSING,
&m_pp,
&g_pDevice)))
return E_FAIL;
//We no longer need the Direct3D object
SAFE_RELEASE(d3d9);
//Success the Direct3D device was created
return S_OK;
}
void Game::Update(float deltaTime){
HRESULT coop = g_pDevice->TestCooperativeLevel();
if(coop != D3D_OK)
{
if(coop == D3DERR_DEVICELOST)
{
if(m_deviceStatus == DEVICE_LOSTREADY)
OnDeviceLost();
}
else if(coop == D3DERR_DEVICENOTRESET)
{
if(m_deviceStatus == DEVICE_NOTRESET)
OnDeviceGained();
}
}
}
void Game::Cleanup()
{
SAFE_RELEASE(g_pDevice);
}
void Game::OnDeviceLost()
{
try
{
//Add OnDeviceLost() calls for DirectX COM objects
m_deviceStatus = DEVICE_NOTRESET;
}
catch(...)
{
//Error handling code
}
}
void Game::OnDeviceGained()
{
try
{
g_pDevice->Reset(&m_pp);
//Add OnResetDevice() calls for DirectX COM objects
m_deviceStatus = DEVICE_LOSTREADY;
}
catch(...)
{
//Error handling code
}
}
void Game::Render()
{
if(m_deviceStatus==DEVICE_LOSTREADY){
g_pDevice->Clear(0, NULL, D3DCLEAR_TARGET | D3DCLEAR_ZBUFFER, 0xff00ff00, 1.0f, 0);
if(SUCCEEDED(g_pDevice->BeginScene()))
{
// Perform some rendering to back buffer.
g_pDevice->EndScene();
}
// Swap buffers.
g_pDevice->Present(NULL, NULL, NULL, NULL);
}
}
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, PSTR cmdLine, int showCmd){
Game mygame;
if(FAILED(mygame.Init(hInstance))){
MessageBox(NULL, L"Failed to initialize game", NULL, MB_OK);
return 1;
}
//Get the time in milliseconds
DWORD startTime = GetTickCount();
float deltaTime = 0;
MSG msg;
memset(&msg, 0, sizeof(MSG));
while(WM_QUIT != msg.message){
while(PeekMessage(&msg, 0, 0, 0, PM_REMOVE) != 0){
//Put the message in a recognizable form
TranslateMessage(&msg);
//Send the message to the window procedure
DispatchMessage(&msg);
}
//Update the game
DWORD t=GetTickCount();
deltaTime=float(t-startTime)*0.001f;
//Pass time in seconds
mygame.Update(deltaTime);
//Render the world
mygame.Render();
startTime = t;
}
mygame.Cleanup();
return (int)msg.wParam;
}
LRESULT CALLBACK WndProc(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam){
//Handle window creation and destruction events
switch(msg){
case WM_CREATE:
break;
case WM_DESTROY:
PostQuitMessage(0);
break;
}
//Handle all other events with default procedure
return DefWindowProc(hWnd, msg, wParam, lParam);
}
Loading an Animation Hierarchy
Hopefully you have found the tutorial useful up until now. In this part I will start by setting the perspective projection and then cover the steps needed to load and animate a mesh. We will be animating our mesh object with hardware acceleration. This involves creating an HLSL .fx file.
RequirementsYou will need a method of producing an .x file with animation info. For this I will be using 3d studio max 2014 and an exporter plugin. There are a number of plugins available. If you can't get hold of this then you may have to use Blender, however I don't know if the .x files produced with Blender are sufficient for this tutorial. And I don't have the incentive to find out. So I leave this to the reader. Hopefully you will find a way to produce an .x file with an animation hierarchy in a suitable format for loading into a DirectX application.
Setting up a perspective projection We have three matrices to create. World, View and Projection. The World matrix represents the world transformation for a set of objects such as meshes. This is the position of these meshes in the game world. The view matrix represents the camera. It has a
lookAt component, an
Up component that specifies the up direction of the world, y or z. And also an eye component that is the "look from" component; the position of the camera.
Our perspective matrix defines the "fish eye" factor or field-of-view, which is the angle range we can see from our eye. This is typically 45 degrees. We must also specify the aspect ratio, which is the number of width pixels in correspondence with the number of height pixels; the ratio of width to height. Typically set this to
WINDOW_WIDTH /
WINDOW_HEIGHT. And lastly, the z near plane and z far plane must be specified, these are the cut-off points of our view. Typically the z near plane of a projection frustum is
z=1.0f. Z here is the point of cut-off; anything closer to the eye than 1.0 is cut-off, not rendered. Similarly anything further away than zfar is cut-off, not rendered too.
We add the describing transform states with the
D3DTS_ constants in the device
SetTranform function passing each tranform matrix as parameters. This is done in our
Render() function.
D3DXMATRIX view, proj, world;
D3DXMatrixIdentity(&world); //Set to no transform
//Position the camera behind the z axis(z=-10)
//Make Y the up direction of the world
//And look at the centre of the world origin(0,0,0)
D3DXMatrixLookAtLH(&view, &D3DXVECTOR3(0,0,-10.0f), &D3DXVECTOR3(0.0f, 1.0f, 0.0f), &D3DXVECTOR3(0.0f, 0.0f, 0.0f));
//Make the field of view 45 degrees
//Use the window dimensions for aspect ratio so rendered image is not
//stretched when window is resized.
//Set znear to 1.0f and zfar to 10000.0f
RECT rc;
GetClientRect(m_mainWindow, &rc);
D3DXMatrixPerspectiveFovLH(&proj, D3DXToRadian(45.0), (float)rc.width / (float)rc.height, 1.0f, 10000.0f);
g_pDevice->SetTransform(D3DTS_WORLD, &world);
g_pDevice->SetTransform(D3DTS_VIEW, &view);
g_pDevice->SetTransform(D3DTS_PROJECTION, &proj);
Now that we have the scene set up, the basic camera and projection ready - it's time to load a model with animation.
Loading an Animation HierarchyIn real life humans and animals have bones. Likewise, our game characters have bones. A bone in DirectX is represented with the
D3DXFRAME structure. You may just think of this structure as a bone. A bone may have a parent and a sibling. For example a parent bone might be the upper arm and a child bone might be the lower arm. When you move your upper arm, your lower arm, forearm, moves with it. That is why a forearm is the child. If you move your lower arm however, the upper arm is not affected. And hence that is why the upper arm is a parent. Each bone may have a transformation, a rotation and position for example. A sibling is just a bone that shares the same parent as another
bone(D3DXFRAME). Let's look at the
D3DXFRAME structure to see how we can represent a bone in code.
struct D3DXFRAME{
LPSTR Name;
D3DXMATRIX TransformationMatrix;
LPD3DXMESHCONTAINER pMeshContainer;
D3DXFRAME* pFrameSibling;
D3DXFRAME* pFrameFirstChild;
};
A bone has a name, a transformation, and optionally a mesh associated with it; and optionally a sibling and a child. With this structure we can represent a whole hierarchy or skeleton in other words. By associating sibling bones and child bones we can link all the
D3DXFRAME bones together, which in turn will be a representation of a skeleton such as a human or an animal.
The names of the bones could be "right leg", "left leg", "right forearm" for example to give you an idea. The transformations defined in a basic
D3DXFRAME are the local bone transformations. These are local to the bones in contrast with the world transformations, which are the actual transformations in the world; the final transforms. In our game we require the world transformations of the bones to render them at the exact positions in the world; so we will extend this structure to include them. For easy reference we will call the new structure
Bone.
struct Bone: public D3DXFRAME
{
D3DXMATRIX WorldMatrix;
};
The
WorldMatrix is the combination of a bone's local matrix with its parent's WorldMatrix. This is simply a multiplication of the two so that the child bone inherits the transformation of its parent.
We must traverse the bone hierarchy to calculate each of the new matrices. This is done with the following recursive function:
void CalculateWorldMatrices(Bone* child, D3DXMATRIX* parentMatrix){
D3DXMatrixMultiply(&child->WorldMatrix, &child->TransformationMatrix, parentMatrix);
//Each sibling has same parent as child
//so pass the parent matrix of this child
if(child->pFrameSibling){
CalculateWorldMatrices((Bone*)child->pFrameSibling, parentMatrix);
}
//Pass child matrix as parent to children
if(child->pFrameFirstChild){
CalculateWorldMatrices((Bone*)child->pFrameFirstChild, &child->WorldMatrix);
}
}
Then to calculate all of the bones matrices that make up the skeleton we call
CalculateWorldMatrices on the root node, the parent bone of the hierarchy with the identity matrix as the parent. This will traverse all children and siblings of those children and build each of the world matrices.
To load a bone hierarchy from an .x file we must implement the
ID3DXAllocateHierarchy interface. This interface defines 4 functions that we must implement ourselves. Then we pass the implemented object in a call to
D3DXLoadMeshHierarchyFromX(). That will create a skeleton of a character. And after we have the skeleton we can apply skinning by using an HLSL effect file to make our character effectively have skin.
To implement the functions declared in
ID3DXAllocateHierarchy we provide a new class definition that inherits from it. We will call this class
AllocateHierarchyImp. The new class and inherited functions effectively looks like this:
Note: STDMETHOD is a macro defined as virtual HRESULT __stdcall. It declares a virtual function that is a function that must be implemented by an inheriting class and uses the standard calling convention __stdcall.
class AllocateHierarchyImp : public ID3DXAllocateHierarchy{
public:
STDMETHOD(CreateFrame)(LPCSTR Name,
LPD3DXFRAME* ppNewFrame);
STDMETHOD(CreateMeshContainer)(LPCSTR Name,
CONST D3DXMESHDATA* pMeshData,
CONST D3DXMATERIAL* pMaterials,
CONST D3DXEFFECTINSTANCE* pEffectInstances,
DWORD NumMaterials,
CONST DWORD* pAdjacency,
LPD3DXSKININFO pSkinInfo,
LPD3DXMESHCONTAINER* ppNewMeshContainer);
STDMETHOD(DestroyFrame)(LPD3DXFRAME pFrameToFree);
STDMETHOD(DestroyMeshContainer)(LPD3DXMESHCONTAINER pMeshContainerBase);
};
In these functions we handle the allocation of memory for bones and the deallocation of memory we allocated ourselves for bones and associated bone meshes.
CreateFrame is fairly simple; we just allocate memory for a bone with
new Bone; and allocate memory for the name of the bone with
new char[strlen(Name)+1];.
CreateMeshContainer on the other hand is more complicated. Bear in mind these functions are called by the
D3DXLoadMeshHierarchyFromX() function. Information about the mesh we are loading is passed to these functions.
Before I jump into the code for these functions we should consider a class that will provide the mechanism of loading a skinned mesh separately for each of our animated characters. Thus we will create a class called
SkinnedMesh that caters for each individual character. This class is outlined as:
SkinnedMesh.h
class SkinnedMesh{
public:
SkinnedMesh();
~SkinnedMesh();
void Load(WCHAR filename[]);
void Render(Bone* bone);
private:
void CalculateWorldMatrices(Bone* child, D3DXMATRIX* parentMatrix);
void AddBoneMatrixPointers(Bone* bone);
D3DXFRAME* m_pRootNode;
};
We need to define a mesh container structure so that we can hold a mesh associated with each bone and prepare for skinning the mesh. Like with the
Bone when we extended the
D3DXFRAME, we extend the
D3DXMESHCONTAINER to represent a mesh associated with a bone. The
D3DXMESHCONTAINER looks like this:
struct D3DXMESHCONTAINER{
LPSTR Name;
D3DXMESHDATA MeshData;
LPD3DXMATERIAL pMaterials;
LPD3DXEFFECTINSTANCE pEffects;
DWORD NumMaterials;
DWORD* pAdjacency;
LPD3DXSKININFO pSkinInfo;
D3DXMESHCONTAINER* pNextMeshContainer;
};
Time for a cup of coffee.
MeshData holds the actual mesh.
pMaterials holds material and texture info.
pEffects may hold effects associated with the mesh.
pAdjacency holds adjacency info, which is indices of faces, triangles, adjacent to each other. And
pSkinInfo holds skinning info such as vertex weights and bone offset matrices that are used to add a skin effect to our animations.
And our extended version to cater for skinning looks like this:
SkinnedMesh.h
struct BoneMesh: public D3DXMESHCONTAINER
{
vector<D3DMATERIAL9> Materials;
vector<IDirect3DTexture9*> Textures;
DWORD NumAttributeGroups;
D3DXATTRIBUTERANGE* attributeTable;
D3DXMATRIX** boneMatrixPtrs;
D3DXMATRIX* boneOffsetMatrices;
D3DXMATRIX* localBoneMatrices;
};
The attribute table is an array of
D3DXATTRIBUTERANGE objects. The
AttribId of this object corresponds to the material or texture to use for rendering a subset of a mesh. Because we are working with a COM object for the mesh, the memory for it will be deallocated after the function completes unless we add a reference using
AddRef(). So we call
AddRef on the
pMesh of
MeshData:
pMeshData->pMesh->AddRef().
Notice
boneMatrixPtrs; these are pointers to world bone transformation matrices in the
D3DXFRAME structures. This means if we change the world transform of a bone these will be affected or in other words these will point to the changed matrices. We need the world transformations to perform rendering. When we animate the model, we call CalculateWorldMatrices to calculate these new world matrices that represent the pose of the bones, the bone transformations. A boneMesh may be affected by a number of bones so we use pointers to these bones matrices instead of saving them twice or multiple times for bone meshes and also so we only have to update one bone matrix with our animation controller for that bone to take effect. Using the modified local transformations of the model from the animation controller, we get these matrices from the bones that influence a mesh. We then use the boneoffset matrices to calclate the local transformations as these are not stored and offset matrices are stored in
pSkinInfo. When we multiply a bone offset matrix with a bone's world matrix we get the bone's local transformation without it's affecting parent's world transformation. We want to do this when we pass the transformation to the skinning shader. The mesh in this case is the mesh associated with one of the bones, found in the
D3DXFRAME structure
pMeshContainer.
Now that you understand the
Bone and
BoneMesh structures somewhat we can begin to implement the
ID3DXAllocateHierachy. We'll start with
CreateFrame. In this function we allocate memory for the name of the bone as well as memory for the bone itself:
SkinnedMesh.cpp
HRESULT AllocateHierarchyImp::CreateFrame(LPCSTR Name, LPD3DXFRAME *ppNewFrame)
{
Bone *bone = new Bone;
memset(bone, 0, sizeof(Bone));
if(Name != NULL)
{
//Allocate memory for name
bone->Name = new char[strlen(Name)];
strcpy(bone->Name, Name);
}
//Prepare Matrices
D3DXMatrixIdentity(&bone->TransformationMatrix);
D3DXMatrixIdentity(&bone->WorldMatrix);
//Return the new bone
*ppNewFrame = (D3DXFRAME*)bone;
return S_OK;
}
And the
DestroyFrame function should deallocate memory allocated in
CreateFrame:
HRESULT AllocateHierarchyImp::DestroyFrame(LPD3DXFRAME pFrameToFree)
{
if(pFrameToFree)
{
//Free up memory
if(pFrameToFree->Name != NULL)
delete [] pFrameToFree->Name;
delete pFrameToFree;
}
pFrameToFree = NULL;
return S_OK;
}
A single mesh can have a number of bones influencing it. Each bone has a set of vertex weights associated with it corresponding to each vertex of the mesh. The weights determine how much a vertex is affected by each bone. The greater the weight of a bone, the more a vertex will be affected by the transformation of that bone. This is how the skin works. The weights of each vertex of the model that correspond to affecting bones are passed to the HLSL effect file that performs the skinning on the GPU. And the bones that influence the vertex are passed to the HLSL file as well through the
BLENDINDICES0 semantic. These weights and bones are stored in the .x file and therefore are loaded in the
MeshData of the
D3DXMESHCONTAINER BoneMesh. By rendering a subset of the
BoneMesh, we pass these weight and bone parameters to the effect file, which in turn performs the skinning based on these values. We pass the values to the HLSL file during the
SkinnedMesh rendering function.
Look back at the
BoneMesh structure. Bone offset matrices are inverse matrices that tranform a bone from world space to local space; that is to the transformation uneffected by its parent. These are stored in the .x file and can be retrieved with
pSkinInfo of
D3DXSKININFO.
To skin a mesh with hardware skinning we need to put the vertex data of each mesh to render in a format that has vertex weight and influencing bone indices. The bone indices are indices of bones that affect the vertex. Each bone in the .x file has a set of vertices that are "attached" to that bone and a weight for each vertex that determines how much the bone affects that vertex. To include this information in our mesh, we must convert the mesh to an "indexed blended" mesh. When we convert the mesh to an indexed blended mesh, the additional bone indices and vertex weights are added to our vertex information within the mesh.
Now is a good time to show you how to load a mesh container since you know about the elements that make up one. Here it is again:
struct BoneMesh: public D3DXMESHCONTAINER
{
vector<D3DMATERIAL9> Materials;
vector<IDirect3DTexture9*> Textures;
DWORD NumAttributeGroups;
D3DXATTRIBUTERANGE* attributeTable;
D3DXMATRIX** boneMatrixPtrs;
D3DXMATRIX* boneOffsetMatrices;
D3DXMATRIX* localBoneMatrices;
};
localBoneMatrices are calculated when we render the mesh by using
boneMatrixPtrs and
boneOffsetMatrices so we can pass the local bone matrix array to the shader to perform skinning. In our
CreateMeshContainer function we must allocate memory for these matrix arrays and obtain pointers to the world transformations of our bones.
HRESULT AllocateHierarchyImp::CreateMeshContainer(LPCSTR Name, CONST D3DXMESHDATA *pMeshData,
CONST D3DXMATERIAL *pMaterials,
CONST D3DXEFFECTINSTANCE *pEffectInstances,
DWORD NumMaterials,
CONST DWORD *pAdjacency,
LPD3DXSKININFO pSkinInfo,
LPD3DXMESHCONTAINER *ppNewMeshContainer)
{
//Allocate memory for the new bone mesh
//and initialize it to zero
BoneMesh *boneMesh = new BoneMesh;
memset(boneMesh, 0, sizeof(BoneMesh));
//Add a reference to the mesh so the load function doesn't get rid of //it
pMeshData->pMesh->AddRef();
//Get the device
IDirect3DDevice9 *pDevice = NULL;
pMeshData->pMesh->GetDevice(&pDevice);
//Get the mesh materials and create related textures
D3DXMATERIAL mtrl;
for(int i=0;i<NumMaterials;i++){
memcpy(&mtrl, &pMaterials[i], sizeof(D3DXMATERIAL));
boneMesh->Materials.push_back(mtrl.MatD3D);
IDirect3DTexture9* pTexture = NULL;
//If there is a texture associated with this material, load it into
//the program
if(mtrl.pTextureFilename != NULL){
wchar_t fname[MAX_PATH];
memset(fname, 0, sizeof(wchar_t)*MAX_PATH);
mbstowcs(fname, mtrl.pTextureFilename, MAX_PATH);
D3DXCreateTextureFromFile(pDevice, fname, &pTexture);
boneMesh->Textures.push_back(pTexture);
}
else{
//Make sure we have the same number of elements in //Textures as we do Materials
boneMesh->Textures.push_back(NULL);
}
}
//Now we need to prepare the mesh for hardware skinning; as //mentioned earlier we need the bone offset matrices, and these are
//stored in pSkinInfo. Here we get the bone offset matrices and //allocate memory for the local bone matrices that influence the //mesh. But of course this is only if skinning info is available.
if(pSkinInfo != NULL){
boneMesh->pSkinInfo = pSkinInfo;
pSkinInfo->AddRef();
DWORD maxVertInfluences = 0;
DWORD numBoneComboEntries = 0;
ID3DXBuffer* boneComboTable = 0;
//Convert mesh to indexed blended mesh to add additional //vertex components; weights and influencing bone indices.
//Store the new mesh in the bone mesh.
pSkinInfo->ConvertToIndexedBlendedMesh(pMeshData->pMesh,
D3DXMESH_MANAGED | D3DXMESH_WRITEONLY,
30,
0, //Not used
0, //Not used
0, //Not used
0, //Not used
&maxVertInfluences,
&numBoneComboEntries,
&boneComboTable,
&boneMesh->MeshData.pMesh);
if(boneComboTable != NULL) //Not used
boneComboTable->Release();
//As mentioned, the attribute table is used for selecting //materials and textures to render on the mesh. So we aquire //it here.
boneMesh->MeshData.pMesh->GetAttributeTable(NULL, &boneMesh->NumAttributeGroups);
boneMesh->attributeTable = new D3DXATTRIBUTERANGE[boneMesh->NumAttributeGroups];
boneMesh->MeshData.pMesh->GetAttributeTable(boneMesh->attributeTable, NULL);
//Next we load the offset matrices and allocate memory for //the local bone matrices. skin info holds the number of bones //that influence this mesh in terms of the bones used to create //the skin.
int NumBones = pSkinInfo->GetNumBones();
boneMesh->boneOffsetMatrices = new D3DXMATRIX[NumBones];
boneMesh->localBoneMatrices = new D3DXMATRIX[NumBones];
for(int i=0;i < NumBones;i++){
boneMesh->boneOffsetMatrices[i] = *(boneMesh->pSkinInfo->GetBoneOffsetMatrix(i));
}
}
//Return new mesh
*ppNewMeshContainer = boneMesh;
return S_OK;
}
Hopefully you understood that code to create a mesh ready for animating.
But before we animate it we have to provide the mesh deallocation implementation. This is simply a case of deallocating the memory we allocated ourselves and releasing the COM objects used:
HRESULT AllocateHierarchyImp::DestroyMeshContainer(LPD3DXMESHCONTAINER pMeshContainerBase)
{
BoneMesh* boneMesh = (BoneMesh*)pMeshContainerBase;
//Release textures
int nElements = boneMesh->Textures.size();
for(int i=0;i<nElements;i++){
if(boneMesh->Textures[i] != NULL)
boneMesh->Textures[i]->Release();
}
//Delete local bone matrices and offset if we have skin info
if(boneMesh->pSkinInfo != NULL){
delete[] boneMesh->localBoneMatrices;
delete[] boneMesh->boneOffsetMatrices;
delete[] boneMesh->attributeTable;
}
//Release mesh and skin info
if(boneMesh->pSkinInfo){boneMesh->pSkinInfo->Release();}
if(boneMesh->MeshData.pMesh){boneMesh->MeshData.pMesh->Release();}
return S_OK;
}
Now that the
AllocateHierarchy functions are implemented we can go ahead and call
D3DXLoadMeshHierarchyFromX passing the
AllocateHierarchy object to it. This is done in the
SkinnedMesh::Load function. When we call this function we retrieve a pointer to the root bone of the hierarchy that allows us to traverse the whole hierarchy with this one bone to calculate new matrices for animation for example. With just the root node we can add matrix pointers to each of our meshes that correspond to the world transformations of each bone and effectively will point to matrices that make up the animation when we animate the model.
In our
SkinnedMesh::Load function is where we call
D3DXLoadMeshHierarchyFromX. First we need to create an instance of the
AllocateHierarchy; Our
SkinnedMesh implementation then becomes:
SkinnedMesh::SkinnedMesh(){
}
SkinnedMesh::~SkinnedMesh(){
}
void SkinnedMesh::Load(WCHAR filename[]){
AllocateHierarchyImp boneHierarchy;
D3DXLoadMeshHierarchyFromX(filename, D3DXMESH_MANAGED,
g_pDevice, &boneHierarchy,
NULL, &m_pRootNode, NULL);
}
void SkinnedMesh::Render(Bone *bone){
}
void SkinnedMesh::CalculateWorldMatrices(Bone *child, D3DXMATRIX *parentMatrix){
D3DXMatrixMultiply(&child->WorldMatrix, &child->TransformationMatrix, parentMatrix);
//Each sibling has same parent as child
//so pass the parent matrix of this child
if(child->pFrameSibling){
CalculateWorldMatrices((Bone*)child->pFrameSibling, parentMatrix);
}
//Pass child matrix as parent to children
if(child->pFrameFirstChild){
CalculateWorldMatrices((Bone*)child->pFrameFirstChild, &child->WorldMatrix);
}
}
void SkinnedMesh::AddBoneMatrixPointers(Bone *bone){
}
Now in our game object we can test whether the hierarchy of one of our .x files can be loaded. Place
SkinnedMesh model1; in the private members of your
Game object. And call
model1.Load("Your file.x") in the
Init() function of
Game. You will need to put an .x file containing a bone hierarchy into the directory that the game runs from. You can test whether a hierarchy was loaded using a break point. Hopefully all is good. You loaded a bone hierarchy.
We still have a few things to setup before model animation can occur. With the HLSL shader that we create, we define an interpolation of vertices from a start pose to a final pose. Each start and end pose of an animation is known as an
animation set and these should typically be stored in the .x file. Whenever we pass a vertex to the HLSL effect it will be updated to a new position and then that new position will be passed the HLSL effect file and be updated and this is how we create a skinned animation but we need to setup the matrices that make this animation work. We must pass the bone tranformations to this effect file uneffected by their parents in order to calculate new vertex positions with the vertex shader. For these tranformations we calculate them in our
Render function using bone pointer matrices and bone offset matrices. So we need to add bone matrix pointers to each bone mesh of the hierarchy. Then when we render the mesh we can easily access these from the array of matrix pointers to the world matrices of the bones that affect the mesh skin.
These bone matrix pointers are added to each mesh that is affected by bones; we use pointers so that when a bone's transformation changes the pointers will be affected and resultingly the mesh skin too. To add pointers we must traverse the whole hierarchy and check for a bone mesh; if one exists and has skinning information, we add the matrix pointers to affecting bones. The affecting bones are the bones contained in
pSkinInfo:
void SkinnedMesh::AddBoneMatrixPointers(Bone *bone){
if(bone->pMeshContainer != NULL){
BoneMesh* boneMesh=(BoneMesh*)bone->pMeshContainer;
if(boneMesh->pSkinInfo != NULL){
//Get the bones affecting this mesh' skin.
int nBones=boneMesh->pSkinInfo->GetNumBones();
//Allocate memory for the pointer array
boneMesh->boneMatrixPtrs = new D3DXMATRIX*[nBones];
for(int i=0;i<nBones;i++){
Bone* bone=(Bone*)D3DXFrameFind(m_pRootNode, boneMesh->pSkinInfo->GetBoneName(i));
if(bone != NULL){
boneMesh->boneMatrixPtrs[i]=&bone->WorldMatrix;
}
else{
boneMesh->boneMatrixPtrs[i]=NULL;
}
}
}
}
//Traverse Hierarchy
if(bone->pFrameSibling){AddBoneMatrixPointers((Bone*)bone->pFrameSibling);}
if(bone->pFrameFirstChild){AddBoneMatrixPointers((Bone*)bone->pFrameFirstChild);}
}
We call this function passing the root node to it to setup all the pointers to influencing mesh bones world matrices. This is done after loading the hierarchy. Also add a call to
CalculateWorldMatrices in the
Load function to add world matrices to each of the bones. If you don't add these the model will be displayed as a jumble of meshes.
void SkinnedMesh::Load(WCHAR filename[]){
AllocateHierarchyImp boneHierarchy;
if(SUCCEEDED(D3DXLoadMeshHierarchyFromX(filename, D3DXMESH_MANAGED,
g_pDevice, &boneHierarchy,
NULL, &m_pRootNode, NULL))){
D3DXMATRIX identity;
D3DXMatrixIdentity(&identity);
CalculateWorldMatrices((Bone*)m_pRootNode, &identity);
AddBoneMatrixPointers((Bone*)m_pRootNode);
}
}
Now we need to free the memory of the matrix pointers when the skinned mesh is destroyed. This again involves traversing the hierarchy and freeing memory used by pointers. Add the following function to the
SkinnedMesh class:
void SkinnedMesh::FreeBoneMatrixPointers(Bone *bone){
if(bone->pMeshContainer != NULL){
BoneMesh* boneMesh=(BoneMesh*)bone->pMeshContainer;
if(boneMesh->boneMatrixPtrs != NULL){
delete[] boneMesh->boneMatrixPtrs;
}
}
//Traverse Hierarchy
if(bone->pFrameSibling){FreeBoneMatrixPointers((Bone*)bone->pFrameSibling);}
if(bone->pFrameFirstChild){FreeBoneMatrixPointers((Bone*)bone->pFrameFirstChild);}
}
And call it on
SkinnedMesh destruction.
SkinnedMesh::~SkinnedMesh(){
FreeBoneMatrixPointers((Bone*)m_pRootNode);
}
Animating a Hierarchy
Finally everything is set up for us to add the skinning effect and animate the model with an animation controller. First we create the effect; we will make this global so we can use it in the
Render function of our
SkinnedMesh.
ID3DXEffect* g_pEffect=NULL;
This effect will be our interface to the HLSL effect file. We can upload variables to the file through this interface. Create a new effect file called skinning.fx; this is simply an ASCII text file. This will be our shader that performs skinning. We create the effect with
D3DXCreateEffectFromFile(). Call this from the
Init function of your
Game object. Just set flags to
D3DXSHADER_DEBUG for now because the shader is not known to work yet.
//Create effect
//Only continue application if effect compiled successfully
if(FAILED(D3DXCreateEffectFromFile(g_pDevice, L"skinning.fx", NULL, NULL, D3DXSHADER_DEBUG, NULL, &g_pEffect, NULL))){
return E_FAIL;
}
Modify
OnDeviceLost and
OnDeviceGained to cater for the effect file:
void Game::OnDeviceLost()
{
try
{
//Add OnDeviceLost() calls for DirectX COM objects
g_pEffect->OnLostDevice();
m_deviceStatus = DEVICE_NOTRESET;
}
catch(...)
{
//Error handling code
}
}
void Game::OnDeviceGained()
{
try
{
g_pDevice->Reset(&m_pp);
//Add OnResetDevice() calls for DirectX COM objects
g_pEffect->OnResetDevice();
m_deviceStatus = DEVICE_LOSTREADY;
}
catch(...)
{
//Error handling code
}
}
Now we need to implement the
Render function of the
SkinnedMesh and the HLSL file. In this file we calculate both skinning and lighting of the model. We first define our vertex structure that corresponds to the vertex structure of the index blended mesh; this will be the input vertex data to the shader:
struct VS_INPUT_SKIN
{
float4 position: POSITION0;
float3 normal: NORMAL;
float2 tex0: TEXCOORD0;
float4 weights: BLENDWEIGHT0;
int4 boneIndices: BLENDINDICES0;
};
Here we get the position of the vertex that we will modify in the shader; and we get the normal, which is the direction vector of the vertex and used in lighting. The
weights are the weights of the affecting bones, which can be found by the bone indices. We use the weights and the bone matrices to determine the new position of the vertex for each vertex and normals. Therefore we store the matrices in a matrix array as follows:
extern float4x4 BoneMatrices[40];
To calculate the new vertex positions we apply each bone weight to a multiplication of the original vertex position and the bone transformation matrix and sum up the results. However there is one more thing - the combination of weights must add up to 1, which is equivelent to 100%. See, each weight applies a percentage of effect on a vertex so they must add up to 1. Therefore we calculate the last weight as
1-totalWeights; one minus the sum total so that they definitely add up to one.
Here is the complete shader for performing skin and lighting:
//World and View*Proj Matrices
matrix matWorld;
matrix matVP;
//Light Position
float3 lightPos;
//Texture
texture texDiffuse;
//Skinning variables
extern float4x4 BoneMatrices[40];
extern int MaxNumAffectingBones = 2;
//Sampler
sampler DiffuseSampler = sampler_state
{
Texture = (texDiffuse);
MinFilter = Linear; MagFilter = Linear; MipFilter = Linear;
AddressU = Wrap; AddressV = Wrap; AddressW = Wrap;
MaxAnisotropy = 16;
};
//Vertex Output / Pixel Shader Input
struct VS_OUTPUT
{
float4 position : POSITION0;
float2 tex0 : TEXCOORD0;
float shade : TEXCOORD1;
};
//Vertex Input
struct VS_INPUT_SKIN
{
float4 position : POSITION0;
float3 normal : NORMAL;
float2 tex0 : TEXCOORD0;
float4 weights : BLENDWEIGHT0;
int4 boneIndices : BLENDINDICES0;
};
VS_OUTPUT vs_Skinning(VS_INPUT_SKIN IN)
{
VS_OUTPUT OUT = (VS_OUTPUT)0;
float4 v = float4(0.0f, 0.0f, 0.0f, 1.0f);
float3 norm = float3(0.0f, 0.0f, 0.0f);
float lastWeight = 0.0f;
IN.normal = normalize(IN.normal);
for(int i = 0; i < MaxNumAffectingBones-1; i++)
{
//Multiply position by bone matrix
v += IN.weights[i] * mul(IN.position, BoneMatrices[IN.boneIndices[i]]);
norm += IN.weights[i] * mul(IN.normal, BoneMatrices[IN.boneIndices[i]]);
//Sum up the weights
lastWeight += IN.weights[i];
}
//Make sure weights add up to 1
lastWeight = 1.0f - lastWeight;
//Apply last bone
v += lastWeight * mul(IN.position, BoneMatrices[IN.boneIndices[MaxNumAffectingBones-1]]);
norm += lastWeight * mul(IN.normal, BoneMatrices[IN.boneIndices[MaxNumAffectingBones-1]]);
//Get the world position of the vertex
v.w = 1.0f;
float4 posWorld = mul(v, matWorld);
OUT.position = mul(posWorld, matVP);
//Output texture coordinate is same as input
OUT.tex0 = IN.tex0;
//Calculate Lighting
norm = normalize(norm);
norm = mul(norm, matWorld);
OUT.shade = max(dot(norm, normalize(lightPos - posWorld)), 0.2f);
return OUT;
}
//Pixel Shader
float4 ps_Lighting(VS_OUTPUT IN) : COLOR0
{
float4 color = tex2D(DiffuseSampler, IN.tex0);
return color * IN.shade;
}
technique Skinning
{
pass P0
{
VertexShader = compile vs_2_0 vs_Skinning();
PixelShader = compile ps_2_0 ps_Lighting();
}
}
The technique tells the system to use vertex and pixel shader version 2 and to pass the output of
vs_Skinning to the input of
ps_Lighting. The pixel shader
ps_Lighting essentially "Lights" the pixels of the texture.
Now that we have the vertex shader, we can use it. And render the model. In this
Render function we get a handle to the technique with
g_pEffect->GetTechniqueByName("Skinning") and pass the mesh to it; and glory be the shader will perform its work. The
Render function will be called on the root bone and traverse the bone hierarchy and render each of the mesh containers associated with the bones of the hierarchy.
Here is the
Render function:
void SkinnedMesh::Render(Bone *bone){
//Call the function with NULL parameter to use root node
if(bone==NULL){
bone=(Bone*)m_pRootNode;
}
//Check if a bone has a mesh associated with it
if(bone->pMeshContainer != NULL)
{
BoneMesh *boneMesh = (BoneMesh*)bone->pMeshContainer;
//Is there skin info?
if (boneMesh->pSkinInfo != NULL)
{
//Get the number of bones influencing the skin
//from pSkinInfo.
int numInflBones = boneMesh->pSkinInfo->GetNumBones();
for(int i=0;i < numInflBones;i++)
{
//Get the local bone matrices, uneffected by parents
D3DXMatrixMultiply(&boneMesh->localBoneMatrices[i],
&boneMesh->boneOffsetMatrices[i],
boneMesh->boneMatrixPtrs[i]);
}
//Upload bone matrices to shader.
g_pEffect->SetMatrixArray("BoneMatrices", boneMesh->localBoneMatrices, boneMesh->pSkinInfo->GetNumBones());
//Set world transform to identity; no transform.
D3DXMATRIX identity;
D3DXMatrixIdentity(&identity);
//Render the mesh
for(int i=0;i < (int)boneMesh->NumAttributeGroups;i++)
{
//Use the attribute table to select material and texture attributes
int mtrlIndex = boneMesh->attributeTable[i].AttribId;
g_pDevice->SetMaterial(&(boneMesh->Materials[mtrlIndex]));
g_pDevice->SetTexture(0, boneMesh->Textures[mtrlIndex]);
g_pEffect->SetMatrix("matWorld", &identity);
//Upload the texture to the shader
g_pEffect->SetTexture("texDiffuse", boneMesh->Textures[mtrlIndex]);
D3DXHANDLE hTech = g_pEffect->GetTechniqueByName("Skinning");
g_pEffect->SetTechnique(hTech);
g_pEffect->Begin(NULL, NULL);
g_pEffect->BeginPass(0);
//Pass the index blended mesh to the technique
boneMesh->MeshData.pMesh->DrawSubset(mtrlIndex);
g_pEffect->EndPass();
g_pEffect->End();
}
}
}
//Traverse the hierarchy; Rendering each mesh as we go
if(bone->pFrameSibling!=NULL){Render((Bone*)bone->pFrameSibling);}
if(bone->pFrameFirstChild!=NULL){Render((Bone*)bone->pFrameFirstChild);}
}
Now that we have the shader in place and the render function we can aquire an animation controller and control the animations of the model.
We get an animation controller from the
D3DXLoadHierarchyFromX function. We will add this controller to the
SkinnedMesh class in the private members:
ID3DXAnimationController* m_pAnimControl;
Then in our
SkinnedMesh Load function add this as a parameter to
D3DXLoadMeshHierarchyFromX:
D3DXLoadMeshHierarchyFromX(filename, D3DXMESH_MANAGED,
g_pDevice, &boneHierarchy,
NULL, &m_pRootNode, &m_pAnimControl)
The way animation works is there are a number of animation sets stored in the model or .x file that correspond to different animation cycles such as a walk animation or jump. Depending on the character, each animation has a name and we can set the current animation using its name. If we have different characters we will want to access or set different animations per character using name strings, e.g.
SetAnimation("Walk"),
SetAnimation("Sit") like that. For this we can use a map of strings to animation IDs. With this map we can get the ID of each animation set by using the name along with the map. A map has an array of keys and values associated with those keys. The key here is the name of the animation and the value is its animation set ID.
Lastly once we have the animation sets we can play an animation by calling
m_pAnimControl->AdvanceTime(time, NULL);First let's get the animation sets and store their names and IDs in a map. For this we will create a function in our
SkinnedMesh class
void GetAnimationSets(). Create a map by including
<map> and make sure
using namespace std; is at the top of the
SkinnedMesh cpp file. Create the map called
map<string, dword="DWORD">animationSets; For this you will also need to include
<string>.
using namespace std means we can use
map and
string without
std::map or
std::string for example if you didn't know already. We will also add another two functions
void SetAnimation(string name) and
void PlayAnimation(float time).
The skinned mesh now looks like:
class SkinnedMesh{
public:
SkinnedMesh();
~SkinnedMesh();
void Load(WCHAR filename[]);
void Render(Bone* bone);
private:
void CalculateWorldMatrices(Bone* child, D3DXMATRIX* parentMatrix);
void AddBoneMatrixPointers(Bone* bone);
void FreeBoneMatrixPointers(Bone* bone);
//Animation functions
void GetAnimationSets();
D3DXFRAME* m_pRootNode;
ID3DXAnimationController* m_pAnimControl;
map<string, int>animationSets;
public:
void SetAnimation(string name);
void PlayAnimation(D3DXMATRIX world, float time);
};
We get and save the animation sets to our map with the following function:
void SkinnedMesh::GetAnimationSets(){
ID3DXAnimationSet* pAnim=NULL;
for(int i=0;i<(int)m_pAnimControl->GetMaxNumAnimationSets();i++)
{
pAnim=NULL;
m_pAnimControl->GetAnimationSet(i, &pAnim);
//If we found an animation set, add it to the map
if(pAnim != NULL)
{
string name = pAnim->GetName();
animationSets[name]=i;//Creates an entry
pAnim->Release();
}
}
}
We set the active animation set with
SetAnimation:
void SkinnedMesh::SetAnimation(string name){
ID3DXAnimationSet* pAnim = NULL;
//Get the animation set from the name.
m_pAnimControl->GetAnimationSet(animationSets[name], &pAnim);
if(pAnim != NULL)
{
//Set the current animation set
m_pAnimControl->SetTrackAnimationSet(0, pAnim);
pAnim->Release();
}
}
When we update the game we call the following function to play the active animation:
void SkinnedMesh::PlayAnimation(D3DXMATRIX world, float time){
//The world matrix here allows us to position the model in the scene.
m_pAnimControl->AdvanceTime(time, NULL);//Second parameter not used.
//Update the matrices that represent the pose of animation.
CalculateWorldMatrices((Bone*)m_pRootNode, &world);
}
Usage:
In the
SkinnedMesh::Load function add the following line on hierarchy load success:
//Save names of sets to map
GetAnimationSets();
In the
Game::Init function, set the active animation set - for example if we have a walk cycle animation:
string set="Walk";
model1.SetAnimation(set);
And then play the animation in
Game::Update():
D3DXMATRIX identity;
D3DXMatrixIdentity(&identity);
model1.PlayAnimation(identity, deltaTime*0.5f);
There is one more thing we often want to do. That is render static non-moving meshes that are part of the hierarchy. We might for example have a mesh that doesn't have skin info; so we need to save this; Notice that we create an indexed blended mesh only if there is skin info. Well now we need to save the mesh if there is no skin info:
In our
CreateMeshContainer function:
if(pSkinInfo != NULL){
//...
}
else{
//We have a static mesh
boneMesh->MeshData.pMesh = pMeshData->pMesh;
boneMesh->MeshData.Type = pMeshData->Type;
}
Now we have the static meshes saved in
BoneMesh structures we can render them. But we need first to light the mesh with a lighting shader; Add this to the shader file:
//Vertex Input
struct VS_INPUT
{
float4 position : POSITION0;
float3 normal : NORMAL;
float2 tex0 : TEXCOORD0;
};
VS_OUTPUT vs_Lighting(VS_INPUT IN)
{
VS_OUTPUT OUT = (VS_OUTPUT)0;
float4 posWorld = mul(IN.position, matWorld);
float4 normal = normalize(mul(IN.normal, matWorld));
OUT.position = mul(posWorld, matVP);
//Calculate Lighting
OUT.shade = max(dot(normal, normalize(lightPos - posWorld)), 0.2f);
//Output texture coordinate is same as input
OUT.tex0=IN.tex0;
return OUT;
}
technique Lighting
{
pass P0
{
VertexShader = compile vs_2_0 vs_Lighting();
PixelShader = compile ps_2_0 ps_Lighting();
}
}
Now we can render the static meshes of our model; We have a static mesh if there is no
pSkinInfo. Here we set the lighting technique to active and render the mesh with texturing:
if (boneMesh->pSkinInfo != NULL)
{
//...
}
else{
//We have a static mesh; not animated.
g_pEffect->SetMatrix("matWorld", &bone->WorldMatrix);
D3DXHANDLE hTech = g_pEffect->GetTechniqueByName("Lighting");
g_pEffect->SetTechnique(hTech);
//Render the subsets of this mesh with Lighting
for(int mtrlIndex=0;mtrlIndex<(int)boneMesh->Materials.size();mtrlIndex++){
g_pEffect->SetTexture("texDiffuse", boneMesh->Textures[mtrlIndex]);
g_pEffect->Begin(NULL, NULL);
g_pEffect->BeginPass(0);
//Pass the index blended mesh to the technique
boneMesh->MeshData.pMesh->DrawSubset(mtrlIndex);
g_pEffect->EndPass();
g_pEffect->End();
}
}
That's us done! We have an animated model that we can work with. We can set the active animation and render it with skinning!
Saving an .x File
In this part we will export an animation hierarchy from 3d studio max.
Note: The vertex shader only supports a fixed number of bones for a character so you will need to create a model with about max 40 bones.
- Place the exporter plugin in the plugins directory of max. Fire up 3d Studio Max. New Empty Scene.
- Go to Helpers in the right-hand menu.
- Select CATParent.
- Click and drag in the perspective viewport to create the CATParent triangle object.
- Double click Base Human in the CATRig Load Save list.
- Model a rough human shaped character around the bones. E.g. create new box edit mesh.
- Click on the CATRig triangle. Go to motion in the menu tabs.
- Click and hold Abs and select the little man at the bottom.
- Press the stop sign to activate the walk cycle.
- Go to modifiers and select skin modifier. On the properties sheet you will see Bones:; click Add. Select all the bones. And click Select. Now if you play the animation the skin should follow the bones.
- Lastly, you need to add a material to the mesh, click the material editor icon and drag a material to the mesh.
- Now export the scene or selected model using the exporter plugin. You will need to export vertex normals animation and select Y up as the worlds up direction to suit the game. Select Animation in the export dialog. And select skinning! can't forget that. Set a frame range e.g. 0 to 50 and call the set "walk". Click Add Animation Set. And Save the model.
- Now you can check that the model exported successfully using DXViewer utility that comes with the DirectX SDK.
- Now you can try loading the model into the program.
You may have to adjust the camera. E.g.
D3DXMatrixLookAtLH(&view, &D3DXVECTOR3(0,0.0f,-20.0f), &D3DXVECTOR3(0.0f, 10.0f, 0.0f), &D3DXVECTOR3(0.0f, 1.0f, 0.0f));
Article Update Log
12 April 2014: Initial release
17 April 2014: Updated included download
22 April 2014: Updated
24 April 2014: Updated