Introduction
Many computer scientists suggest that the modern use of shaders originated from the
RenderMan Interface Specification, Version 3.0, originally published in May, 1988. In the present, shaders have proven their flexibility and usefulness when writing graphics intensive applications such as games and simulations. As the capabilities of Graphics Processing Units (GPUs) keep increasing, so do the number of shader types and shader languages.
While there are many shader languages available to the modern programmer, the most prominent and used ones are the
High Level Shading Language for the
DirectX graphics API and the
OpenGL Shading Language for the
OpenGL API.
The Problem
Every modern rendering or game engine supports both APIs in order to provide their users with maximum portability and flexibility. What does this mean to us programmers? It means we either write every single shader program twice or find a way to convert from one language to the other. This is easier said than done. The functionality between
HLSL and
GLSL doesn't differ that much, however the actual implementation of even the simplest diffuse program is completely different in both languages.
Every developer who has ever done cross platform development has ran into the same problem. Of course the problem has already been partially solved in many different ways, however all of the available tools seem to lack two-way conversion, are completely outdated or completely proprietary.
A Solution
Because of the lack of a general-purpose solution, I thought it would be great to create a flexible free tool, which deals with at least
Vertex and
Fragment/Pixel shader conversion between modern
GLSL 4.5 and
HLSL 5.0. That's how the idea for
Savvy - The Smart Shader Cross Compiler came to be. The initial idea was to create the tool with support for just the above mentioned languages, however the final implementation can easily be extended to support conversion from and to any language. What this enables is the fact that
Savvy is entirely written in
C++ and utilizes template classes as well as the latest
C++11 advancements.
The solution chosen is far from being the best for the presented problem, however it is
a solution, which is worth serious consideration.
Approach
The approach I decided to use is pure text-based parsing and conversion. The way the system works is really simple, but very powerful. The input shader is first ran through a lexical scanner (generated by the great
Flex tool), which matches predefined sequences of characters and returns a specific token. Each returned token is then processed through a grammar parser (a simple flat state machine in this case), which determines whether the text is legitimate and should be saved. The saving is performed inside a database structure, which holds all processed information. That information is later used by a shader constructor class, which constructs the output shader.
External Dependencies
The goal of the whole project was to keep the external dependencies as low as possible. The only external software used was
flex - the fast lexical analyzer, created by
Vern Paxson. It is fast, reliable and great at matching extremely complex character combinations using regular expressions. I absolutely recommend it to anyone looking to do advanced file parsing and token matching. Initially I also wanted to use a third party grammar parser, however after a lot of thought on the subject I decided that syntax checking is not going to be part of the initial release, as the scope would just become overwhelming. This made me use a simple flat state machine which would handle all the grammar. So far so good, now let's see how all of it actually fits together. I'll try to keep things as abstract as possible, without delving too much in implementation details.
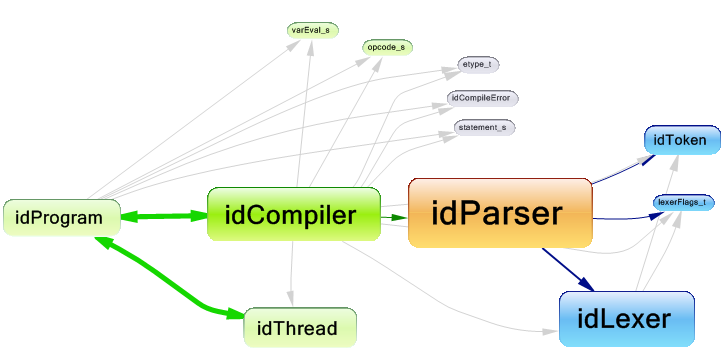
Architecture
The image below shows a very basic look of the architecture. The
Shader Converter class is the main contact point between the user and the internal components of the tool. All conversion calls are made through it. It owns a list of
Lexical Scanners,
Grammar Parsers and
Shader Constructors. All of them are pure virtual base classes, which are implemented once for each supported language. Each
Grammar Parser owns a
Database and each
Shader Constructor owns a
Shader Function Converter.
The Shader Function Converter takes care of converting all intrinsic functions, which do not have direct equivalents in the output language. The
Database also stores the output language equivalents of all built-in data types and intrinsic functions. This type of architecture makes sure that the tool is easily extendable if support for a new language is added.
![YfATfEV.png]()
Interface and Functionality
The
Shader Converter has functions for converting a shader from file to file, file to memory, memory to file and memory to memory. All the conversion functions follow the same pattern. Inside the function, all the input is first validated and then an input stream is opened from the path specified. After that, the
Lexical Scanner for the appropriate input language is called until an
End of File instruction is reached. Each call of the function
GetNextToken returns the next token in the stream. The token corresponds to a predefined set of characters in a sequence. For example, the token
SAVVY_DATA_TYPE is returned for every data type use. The returned token and its string are then used as an input to the
Parser class'
ParseToken function, which determines the state and saves the word to the database if needed. If the input and output shader languages specified are the same, the shader is simply copied over to the specified path without any alterations. Any included files are also parsed in the same fashion, by calling the parsing function recursively.
After the file has been parsed, the input steam is closed and an output stream is opened. Then the
Constructor is called and everything saved in the database is output to the stream. The order of construction is:
1. Construct Defines
2. Construct Uniform(Constant) Buffers
3. Construct Samplers(Textures)
4. Construct Input Variables
5. Construct Output Variables
6. Construct Custom User Types(structs)
7. Construct Global Variables
8. Construct FunctionsThe Function Converter
I feel like I should spend some time explaining what the
Function Converter class actually does. Its job is to make sure each intrinsic function of the input language is translated to the appropriate equivalent of the output language. Unfortunately, there are some functions which are absolutely impossible to translate as they refer to very specific graphics API calls. To give an example, consider the
HLSL function
D3DCOLORtoUBYTE4. The problem here becomes apparent, as there is no
UBYTE4 data type in
GLSL. Upon reaching a function which cannot be converted to the specified output language, an exception will be thrown (or an error code will be returned if the preprocessor directive
SAVVY_NO_EXCEPTIONS is defined) by the tool and conversion will stop.
There are, however, some functions which can be translated, despite the fact that they do not have direct alternatives in other languages. One such function is the arc hyperbolic cosine function in
GLSL -
acosh (well, technically all hyperbolic functions apply here, as none of them are supported in
HLSL). The function itself, given an input value
x can easily be defined as the following equation:
log(x + sqrt(x * x - 1));
When functions of this type are encountered, they are substituted by their inline version.
The final type of function conversions which the
Function Converter handles are those which do have alternatives, but for some reason the output language implementation takes a different amount of arguments or the argument order is swapped. An example of a function which has the exact same functionality, but is implemented differently in both languages is the arc tangent function –
atan. In
GLSL, the function has two possible blueprints. One takes one argument (the
y over
x value) and the other takes the two inputs,
x and
y, separately. This is a problem, as the
HLSL equivalent does not have an overloaded blueprint for two arguments. Instead, it uses a separate function –
atan2. To account for this difference the function converter determines the number of arguments a function call has and according to that, outputs the correct type of function call. If the input shader language has a function which takes one argument less than its output language equivalent, a dummy value will be declared on the line above the call and the last argument will be filled by it, in order to preserve the functionality.
An Odd Case
To add one more function example to the last type – the
fmod function in
HLSL and its "supposed"
GLSL equivalent –
mod. At first glance everything looks great and both versions of the shader should produce the same results, right? Wrong! The internal equations used by those functions are not the same. The
GLSL one, according to the official documentation is:
x - y * floor(x/y)
While the HLSL one is:
x = i * y + f
Both implementations produce the same results if dealing with positive numbers as inputs, however, the moment the input becomes negative, the
HLSL version fails to produce the expected results. It also seems like other cross compilers prefer the former direct approach of converting
mod to
fmod and vice versa, as it is faster when executing the shader. I decided to choose the mathematically correct equation and whenever these functions are encountered in the input shader, the proper inline equation will be constructed in the output shader.
Conversion from File to File
Here is what the declaration of the file to file conversion function looks like:
/*
Converts a shader file from a file to another file.
*/
ResultCode ConvertShaderFromFileToFile(FileConvertOptions& a_Options);
As you can see, the function takes a structure of type
FileConvertOptions, which contains all the needed data for the conversion. For example - shader input path, shader output path, entry points and shader type. Here is a sample usage of the file to file conversion:
Savvy::ShaderConverter* converter = new Savvy::ShaderConverter();
Savvy::ResultCode res;
Savvy::FileConvertOptions options;
options.InputPath = L"PathToMyInputFragShader.glsl";
options.OutputPath = L"PathToMyOutputFragShader.hlsl";
options.InputLang = Savvy::GLSL_4_5;
options.OutputLang = Savvy::HLSL_5_0;
options.ShaderType = Savvy::FRAGMENT_SHADER;
res = converter->ConvertShaderFromFileToFile(options);
Conversion from Memory
Another great feature which wasn't initially planned but was implemented at a later stage is conversion of shaders from memory to memory, memory to file and file to memory. In order to make things easier for the user, the
Blob class was created, which is very similar to the
DirectX 11 one and is just a container for raw data. Its interface is very simple, but effective for the user as it serves for sending raw character strings to the converter and also retrieving the converted ones after the conversion has been done.
The internal conversion is done by constructing a
string stream from the
Blob and having the scanners and parsers operate on that. A simple example of how one can use the
Blob to
Blob conversion is the following:
Savvy::ShaderConverter* converter = new Savvy::ShaderConverter();
Savvy::ResultCode res;
// Load file in memory
std::ifstream is("SomeFile.something");
if (!is.is_open())
{
std::cout << "Error reading file" << std::endl;
}
std::string fileStr(static_cast<std::stringstream const&>(std::stringstream() << is.rdbuf()).str());
is.close();
// Create a blob with the loaded file in memory
Savvy::Blob inputBlob(&fileStr[0], fileStr.size());
Savvy::Blob outputBlob;
Savvy::BlobConvertOptions options;
options.InputBlob = &inputBlob;
options.OutputBlob = &outputBlob;
options.InputType = Savvy::HLSL_5_0;
options.OutputType = Savvy::GLSL_4_5;
res = converter->ConvertShaderFromBlobToBlob(options);
// Output the converted blob to file to verify its integrity
std::ofstream str("BlobToBlobTest.txt");
std::string mystring(options.OutputBlob->GetRawDataPtr(), options.OutputBlob->GetDataSize());
str << mystring;
str.close();
Extending the Tool
While the current implementation only supports conversion of
Vertex and
Fragment programs between modern
GLSL and
HLSL shading languages, it is very easy to extend the tool and add support for custom languages and shader types. The supported languages are separated into supported output languages and supported input languages. If the user wishes to extend the tool to support an extra output language, they need to create their own
Constructor class by inheriting from the base class. After they have done that, the only thing needed is to call the following function supplying an
ID and a default extension for the new output language.
/*
Registers a new custom shader language for output purposes only.
If the ID of this shader type is used as an input, the conversion will fail.
*/
template<typename ConstructorClass>
ResultCode RegisterCustomOutputShaderLang(uint32 a_ID, const wchar* a_DefaultExtension);
In order to add support for a new input language, the user needs to supply custom
Lexical Scanner and
Parser classes and also register them using the following function:
/*
Registers a new custom shader language for input purposes only.
If the ID of this shader type is used as an output, the conversion will fail.
*/
template<typename ScannerClass, typename ParserClass>
ResultCode RegisterCustomInputShaderLang(uint32 a_ID);
Note that a default extension here is not needed as a shader from this language will never be constructed. Likewise, support for a new shader type (geometry, compute) can also be added.
Current Limitations
Of course no software is without its flaws.
Savvy is far from perfect. In this section I'll go in a bit more detail about the current shortcomings of the tool and the chosen approach in general.
Texture Samplers
The thing with
GLSL is that the
Texture Sampler and
Texture objects are joined together in one, while in
HLSL you have to explicitly declare a
Sampler Object together with the
Texture Object. When manually writing a shader you can use one
Sampler to sample multiple
Textures, however when programatically converting a
GLSL shader to an
HLSL one, there is no way of knowing how many samplers we might need, as
OpenGL keeps
Sampler Objects on the
C++ side. A lot of people don't even use
Samplers in
OpenGL yet, as they are quite a new extension there. In order to make sure every texture is going to be properly sampled in
HLSL, every declaration inside a
GLSL shader produces both a
Texture Object and a
Sampler Object, which is named:
NameofTextureObject + Sampler. For example:
DiffuseTextureSampler. This is less than ideal, as we are consuming more
Sampler Registers than we need, but unfortunately there is no other way at this point in time, using purely text-based conversion.
The Preprocessor
Another thing which is not 100% foolproof is the preprocessor conversion. Unfortunately there is no way of knowing which variables on global scope will be inside a specific preprocessor block. Because the tool stores everything in a database, there is no way for it to check if a specified variable is active or inactive in the current global scope. There is also no way of guaranteeing how many variables are inside a preprocessor block and of what type they are (inputs, outputs or uniforms/constant buffers). In order to avoid the issues which come with many branching preprocessor directives, I have decided not to support any conditional compilation outside of functions (Global Scope). Defines are still supported and will always be the first thing constructed. Conditional compilation is also supported inside functions without any constraints. This is possible due to the fact that every function is translated line by line and is guaranteed to keep its consistency across multiple languages.
Syntax Checking
Another big constraint of the tool is that it does not support any syntax checking, so if the user feeds it a shader which does not compile as an input, the output shader will not compile either. There are some internal checks in place, to make sure the tool isn't processing complete garbage, but they are far from being a reliable syntax verifier. In truth, syntax checking is possible to implement and might even be considered in the future, but for now it stays in the unsupported category.
Future Development
The current officially supported languages are
GLSL 4.5 and
HLSL 5.0. I have done some testing with
GLSL shaders as far back as version 3.3 and they seem to work nicely, however take my words with a pinch of salt. The officially supported shader types are
Fragment/Pixel and
Vertex.
Savvy is currently in
Beta stage and after some proper testing and code documentation will be released, together with the source in the public domain. That way anyone who is interested in the project can contribute or use it as a base to make something else. There are many features planned for the tool, the biggest one of which is to add support for the upcoming intermediate shader language
SPIR-V, which was announced at the
Game Developer Conference 2015. Adding support for extra shader types like geometry and compute is also something planned for the future. Implementing a legacy
GLSL profile is not out of the question either, if there is interest for it.
Conclusion
I must say, developing this tool was a very interesting journey. A lot of hours were put in it and a lot of valuable lessons were learned. I decided to write this article as there aren't many articles dedicated to this particular problem out there. I hope it was useful to anyone interested in shader cross-compilation and cross-platform graphics development in general. Its aim was to explain the solution I chose to overcome the problem of shader cross-compilation and also highlight some positive/negative points about the approach. If I missed anything or you have extra questions, ideas or feedback, please do share them. I love hearing other people's opinions and I'm always open to constructive criticism.
Useful Links
Article Update Log
19 April 2015: Initial version of the article released.