Introduction
I want to present an important and interesting topic in computer science, the Finite State Machine (FSM). In this part we start with the basics, gaining an understanding of what FSMs are and what they can be used for. This part is very elementary, so please be patient. In subsequent parts things will become much more complicated and interesting.
Note:
This article combines a series of 6 works originally published to GameDev.net throughout 2004 entitled "Algorithmic Forays". It was collected together and revised by the original author in 2008 and published in the book Advanced Game Programming: A GameDev.net Collection, which is one of 4 books collecting both popular GameDev.net articles and new original content in print format.
Finite State Machines - What are they?
A finite state machine is a conceptual model that can used to describe how many things work. Think about a light bulb for instance. The circuit consists of a switch that can be ON or OFF, a few wires and the bulb itself. At any moment in time the bulb is in some state - it is either turned on (emits light) or turned off (no visible effect). For a more focused discussion, let's assume that we have two buttons - one for "turn on" and one for "turn off".
How would you describe the light bulb circuit? You'd probably put it like this: When it's dark and I press ON, the bulb starts emitting light. Then if I press ON again, nothing changes. If I press OFF the bulb is turned off. Then if I press OFF again, nothing changes.
This description is very simple and intuitive, but in fact it describes a state machine!
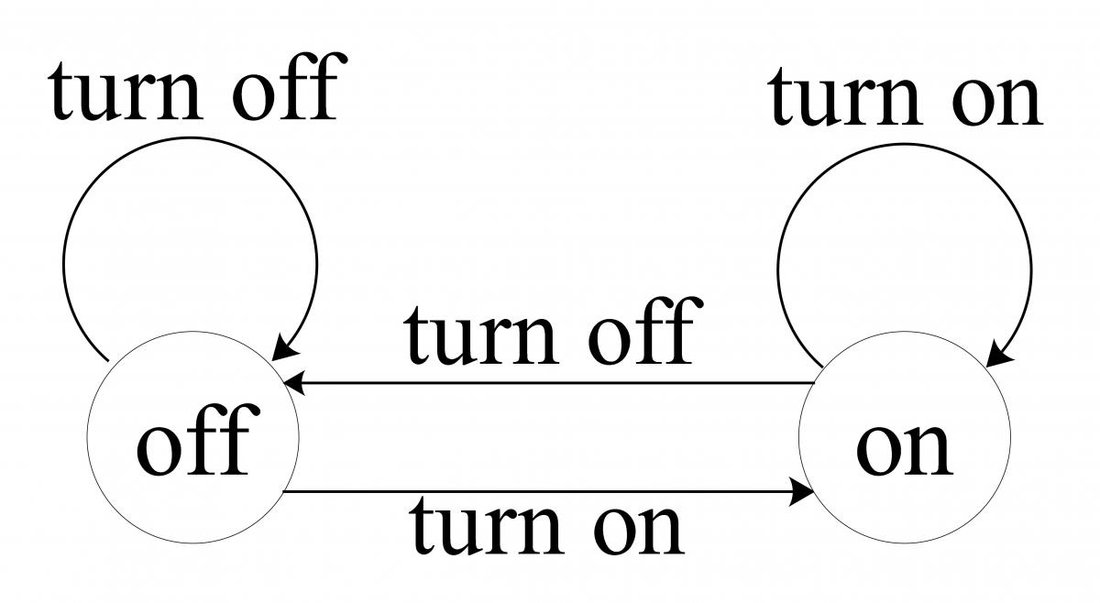
Think of it the following way: we have a machine (the bulb) with two states, ON and OFF. We have two inputs, an ON switch and an OFF switch. If we are in state ON, pressing ON changes nothing, but pressing OFF moves the machine to state OFF. If we are in state OFF, pressing OFF changes nothing, but pressing ON moves the machine to state ON.
The above is a rephrasing of the first description, just a little more formal. It is, in fact, a formal description of a state machine. Another customary way to describe state machines is with a diagram (people like diagrams and drawings more than words for some insights):
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_1.jpg]()
Textual descriptions can become quite wordy, and a simple diagram like this can contain a lot of information. Note how states are represented by circles, and transitions by arrows. This is almost all one needs to know, which makes diagrams very descriptive. This state machine can also be translated to (C++) code:
...
...
typedef enum {ON, OFF} bulb_state;
typedef enum {TURN_ON, TURN_OFF} switch_command;
...
...
bulb_state state;
switch_command command;
switch (state)
{
case ON:
if (command == TURN_ON)
{
}
else if (command == TURN_OFF)
{
state = OFF;
}
break;
case OFF:
if (command == TURN_ON)
{
state = ON;
}
else if (command == TURN_OFF)
{
}
break;
default:
assert(0);
}
If code such as this looks familiar, it's hardly surprising. Many of us write state machines in our code without even noticing. Most of the state machines we write are "implicit", in the sense that there isn't a single switch statement that handles the whole machine, but rather it's distributed throughout the whole program. If, additionally, the state variables don't have the word "state" in their name, guessing that a certain code is a state machine in disguise is even harder.
Many programs we write are state machines. Think about a chess game for a moment. If we write a program to play chess against human beings, it's actually a state machine in some sense. It waits for the human to move - an idle state. Once the human moves, it goes into active state of "thinking" about a move to make. A game can have an "end" state such as a victory for one side or a draw. If we think of a GUI for a chess game, the state machine is even more obvious. There is a basic state, when it's a human's move. If a human clicks on some piece, we go into the "clicked" state. In this state, a click on an empty tile may produce a move by the piece. Note that if we click on an empty tile in the "basic" state (no pieces selected), nothing happens. Can you see an obvious state machine here?
Finite?
In the beginning of this part, I said we were going to discuss FSMs. By now I hope you already know what a state machine is, but what has "finite" got to do with it?
Well, our computers are finite. There's only so much memory (even if it's quite large these days). Therefore, the applications are finite. Finite = Limited. For state machines it means that the amount of states is limited. 1 is limited, 2 is limited, but 107 is also limited, though quite large.
This point may seem banal to some of you, but it is important to emphasize. So now you know what a FSM is: a state machine with a finite number of states. It can be inferred that all state machines implemented in computer hardware and software must be FSMs.
Employing state machines for our needs
State machines can be also used explicitly. We can benefit a lot from knowingly incorporating state machines in our code. First and foremost, it's a great way to reason about difficult problems. If you see that your code or a part of it can actually be in several states, with inputs affecting these states and outputs resulting from them, you can reason about this code using a state machine. Draw a diagram; visualizing always helps. With a diagram errors can be spotted more easily. Think about all the inputs to your code - what should they change in every state? Does your code cover all possibilities (all inputs in all states)? Are some state transitions illegal?
Another use of state machines is for certain algorithms. In the next part you'll see how essential state machines are for a very common and important application: regular expressions.
Regular expressions (regexes)
Think of an identifier in C++ (such as
this,
temp_var2,
assert etc.). How would you describe what qualifies for an identifier? Let's see if we remember... an identifier consists of letters, digits and the underscore character (_), and must start with a letter (it's possible to start with an underscore, but better not to, as these identifiers are reserved by the language).
A regular expression is a notation that allows us to define such things precisely:
letter (letter | digit | underscore) *
In regular expressions, the vertical bar | means "or", the parentheses are used to group sub expressions (just like in math) and the asterisk (*) means "zero or more instances of the previous". So the regular expression above defines the set of all C++ identifiers (a letter followed by zero or more letters, digits or underscores). Let's see some more examples:
- abb*a - all words starting with a, ending with a, and having at least one b in-between. For example: "aba", "abba", "abbbba" are words that fit, but "aa" or "abab" are not.
- 0|1|2|3|4|5|6|7|8|9 - all digits. For example: "1" is a digit, "fx" is not.
- x(y|z)*(a|b|c) - all words starting with x, then zero or more y or z, and end with a, b or c. For example: "xa", "xya", "xzc", "xyzzzyzyyyzb".
- xyz - only the word "xyz".
There is another symbol we'll use:
eps (usually denoted with the Greek letter Epsilon)
eps means "nothing". So, for example the regular expression for "either xy or xyz" is:
xy(z|eps).
People familiar with regexes know that there are more complicated forms than * and |. However, anything can be built from *, | and
eps. For instance,
x? (zero or one instance of x) is a shorthand for
(x|eps).
x+ (one or more instances of x) is a shorthand for
xx*. Note also the interesting fact that * can be represented with +, namely:
x* is equivalent to
(x+)|eps.
[Perl programmers and those familiar with Perl syntax (Python programmers, that would include you) will recognize
eps as a more elegant alternative to the numerical notation {m, n} where both m and n are zero. In this notation,
x* is equivalent to
x{0,} (unbound upper limit),
x+ is
x{1,} and all other cases can be built from these two base cases. - Ed.]
Recognizing strings with regexes
Usually a regex is implemented to solve some recognition problem. For example, suppose your application asks a question and the user should answer Yes or No. The legal input, expressed as a regex is
(yes)|(no). Pretty simple and not too exciting - but things can get much more interesting.
Suppose we want to recognize the following regex:
(a|b)*abb, namely all words consisting of a's and b's and ending with abb. For example: "ababb", "aaabbbaaabbbabb". Say you'd like to write the code that accepts such words and rejects others. The following function does the job:
bool recognize(string str)
{
string::size_type len = str.length();
// can't be shorter than 3 chars
if (len < 3)
return false;
// last 3 chars must be "abb"
if (str.substr(len - 3, 3) != "abb")
return false;
// must contain no chars other than "a" and "b"
if (str.find_first_not_of("ab") != string::npos)
return false;
return true;
}
It's pretty clean and robust - it will recognize
(a|b)*abb and reject anything else. However, it is clear that the techniques employed in the code are very "personal" to the regex at hand.
If we slightly change the regex to
(a|b)*abb(a|b)* for instance (all sequences of a's and b's that have abb somewhere in them), it would change the algorithm completely. (We'd then probably want to go over the string, a char at a time and record the appearance of abb. If the string ends and abb wasn't found, it's a rejection, etc.). It seems that for each regex, we should think of some algorithm to handle it, and this algorithm can be completely different from algorithms for other regexes.
So what is the solution? Is there any standardized way to handle regexes? Can we even dream of a general algorithm that can produce a recognizer function given a regex? We sure can!
FSMs to the rescue
It happens so that Finite State Machines are a very useful tool for regular expressions. More specifically, a regex (any regex!) can be represented as an FSM. To show how, however, we must present two additional definitions (which actually are very logical, assuming we use a FSM for a regex).
- A start state is the state in which a FSM starts.
- An accepting state is a final state in which the FSM returns with some answer.
It is best presented with an example:
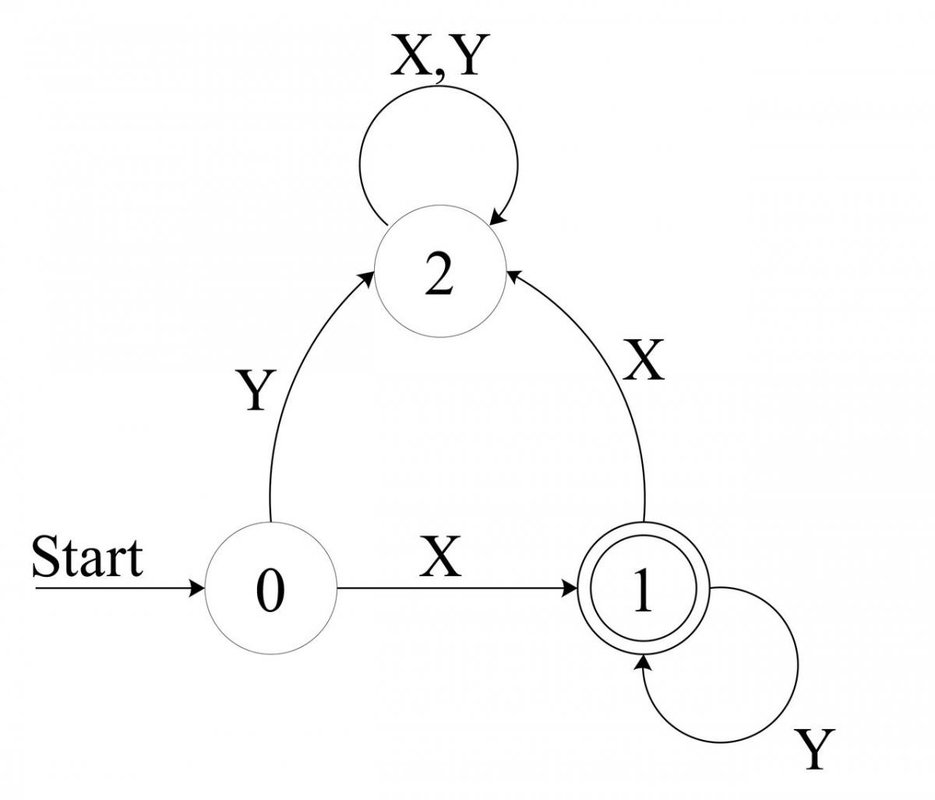
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_2.jpg]()
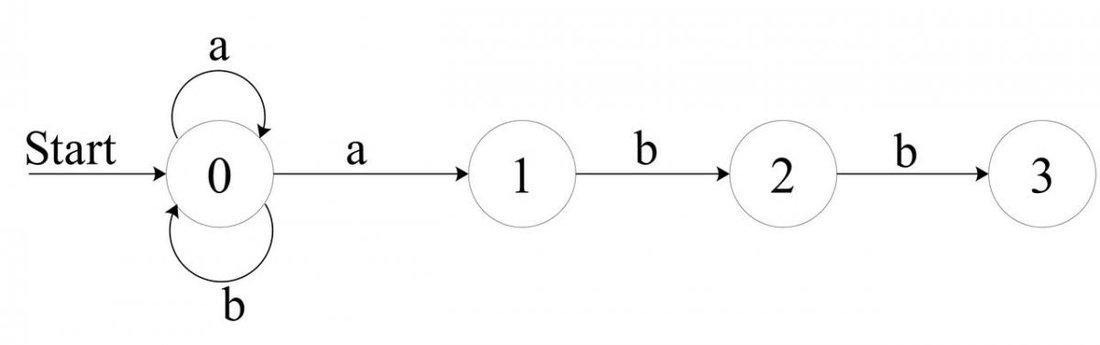
The start state 0 is denoted with a "Start" arrow. 1 is the accepting state (it is denoted with the double border). Now, try to figure out what regex this FSM represents.
It actually represents
xy* - x and then 0 or more of y. Do you see how? Note that x leads the FSM to state 1, which is the accepting state. Adding y keeps the FSM in the accepting state. If a x appears when in state 1, the FSM moves to state 2, which is non accepting and "stuck", since any input keeps the FSM in state 2 (because
xy* rejects strings where a x comes after y-s). But what happens with other letters? For simplicity we'll now assume that for this FSM our language consists of solely x and y. If our input set would be larger (say the whole lowercase alphabet), we could define that each transition not shown (for instance, on input "z" in state 0) leads us into some "unaccepting" state.
I will now present the general algorithm for figuring out whether a given FSM recognizes a given word. It's called "FSM Simulation". But first lets define an auxiliary function:
move(state, input) returns the state resulting from getting
input in state
state. For the sample FSM above, move(0, X) is 1, move (0, Y) is 0, etc. So, the algorithm goes as follows:
state = start_state
input = get_next_input
while not end of input do
state = move(state, input)
input = get_next_input
end
if state is a final state
return "ACCEPT"
else
return "REJECT"
The algorithm is presented in very general terms and should be well understood. Lets "run" it on the simple
xy* FSM, with the input "xyy". We start from the start state - 0; Get next input: x, end of input? not yet; move(0, x) moves us to state 1; input now becomes y; not yet end of input; move(1, y) moves us to state 1; exactly the same with the second y; now it's end of input; state 1 is a final state, so "ACCEPT";
Piece of cake isn't it? Well, it really is! It's a straightforward algorithm and a very easy one for the computer to execute.
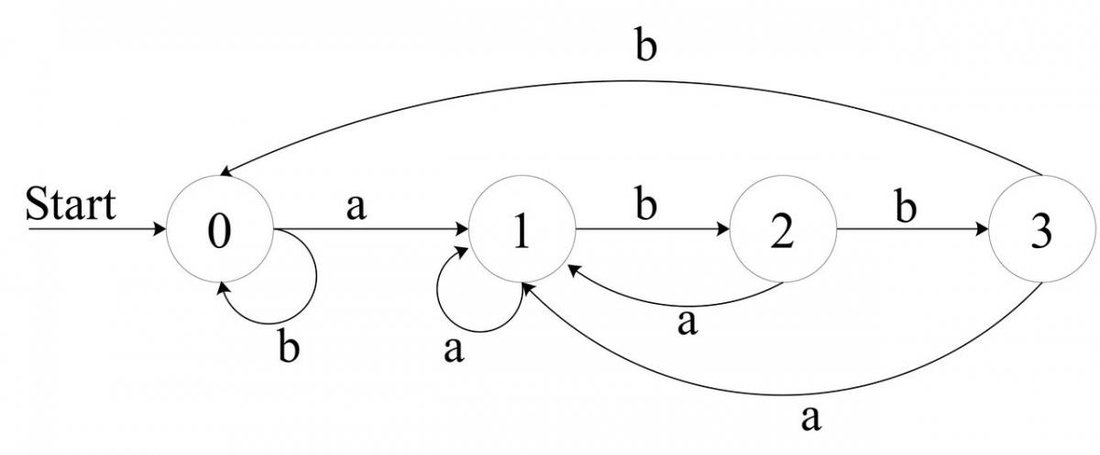
Let's go back to the regex we started with -
(a|b)*abb. Here is the FSM that represents (recognizes) it:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_3.jpg]()
Although it is much more complicated than the previous FSM, it is still simple to comprehend. This is the nature of FSMs - looking at them you can easily characterize the states they can be in, what transitions occur, and when. Again, note that for simplicity our alphabet consists of solely "a" and "b".
Paper and pencil is all you need to "run" the FSM Simulation algorithm on some simple string. I encourage you to do it, to understand better how this FSM relates to the
(a|b)*abb regex.
Just for example take a look at the final state - 3. How can we reach it? From 2 with the input b. How can we reach 2? From 1 with input b. How can we reach 1? Actually from any state with input a. So, "abb" leads us to accept a string, and it indeed fits the regex.
Coding it the FSM way
As I said earlier, it is possible to generate code straight from any regex. That is, given a regular expression, a general tool can generate the code that will correctly recognize all strings that fit the regex, and reject the others. Let's see what it takes...
The task is indeed massive, but consider dividing it to two distinct stages:
- Convert the regex to a FSM
- Write FSM code to recognize strings
Hey, we already know how to do the second stage! It is actually the FSM Simulation algorithm we saw earlier. Most of the algorithm is the same from FSM to FSM (just dealing with input). The only part that changes is the "move" function, which represents the transition diagram of some FSM, and we learned how to code the transition function in the pvery basic, the technique is the same for any FSM!
Let's now write down the full code that recognizes
(a|b)*abb.
#include <iostream>
#include <cassert>
#include <string>
using namespace std;
typedef int fsm_state;
typedef char fsm_input;
bool is_final_state(fsm_state state)
{
return (state == 3) ? true : false;
}
fsm_state get_start_state(void)
{
return 0;
}
fsm_state move(fsm_state state, fsm_input input)
{
// our alphabet includes only 'a' and 'b'
if (input != 'a' && input != 'b')
assert(0);
switch (state)
{
case 0:
if (input == 'a')
{
return 1;
}
else if (input == 'b')
{
return 0;
}
break;
case 1:
if (input == 'a')
{
return 1;
}
else if (input == 'b')
{
return 2;
}
break;
case 2:
if (input == 'a')
{
return 1;
}
else if (input == 'b')
{
return 3;
}
break;
case 3:
if (input == 'a')
{
return 1;
}
else if (input == 'b')
{
return 0;
}
break;
default:
assert(0);
}
}
bool recognize(string str)
{
if (str == "")
return false;
fsm_state state = get_start_state();
string::const_iterator i = str.begin();
fsm_input input = *i;
while (i != str.end())
{
state = move(state, *i);
++i;
}
if (is_final_state(state))
return true;
else
return false;
}
// simple driver for testing
int main(int argc, char** argv)
{
recognize(argv[1]) ? cout < 1 : cout < 0;
return 0;
}
Take a good look at the
recognize function. You should immediately see how closely it follows the FSM Simulation algorithm. The FSM is initialized to the start state, and the first input is read. Then, in a loop, the machine moves to its next state and fetches the next input, etc. until the input string ends. Eventually, we check whether we reached a final state.
Note that this
recognize function will be the same for
any regex. The only functions that change are the trivial
is_final_state and
get_start_state, and the more complicated transition function
move. But
move is very structural - it closely follows the graphical description of the FSM. As you'll see later, such transition functions are easily generated from the description.
So, what have we got so far? We know how to write code that runs a state machine on a string. What don't we know? We still don't know how to generate the FSM from a regex.
DFA + NFA = FSM
FSM, as you already know, stands for Finite State Machine. A more scientific name for it is FA - Finite Automaton (plural
automata). Finite Automata can be classified into several categories, but the one we need for the sake of regex recognition is the notion of
determinism. Something is deterministic when it involves no
chance - everything is known and can be prescribed and simulated beforehand. On the other hand, nondeterminism is about chance and probabilities. It is commonly defined as "A property of a computation which may have more than one result".
Thus, the world of FSMs can be divided to two: a deterministic FSM is called DFA (Deterministic Finite Automaton) and a nondeterministic FSM is called NFA (Nondeterministic Finite Automaton).
NFA
A
nondeterministic finite automaton is a mathematical model that consists of:
- A set of states S
- A set of input symbols A (the input symbol alphabet)
- A transition function move that maps state-symbol pairs to sets of states
- A state s0 that is the start state
- A set of states F that are the final states
I will now elaborate on a few fine points (trying to simplify and avoid mathematical implications).
A NFA
accepts an input string
X if and only if there is some path in the transition graph from the start state to some accepting (final) state, such that the edge labels along this path spell out
X.
The definition of a NFA doesn't pose a restriction on the amount of states resulting in some input in some state. So, given we're in some state
N it is completely legal (in a NFA) to transition to several different states given the input
a.
Furthermore, epsilon (
eps) transitions are allowed in a NFA. That is, there may be a transition from state to state given "no input".
I know this must sound very confusing if it's the first time you learn about NFAs, but an example I'll show a little later should make things more understandable.
DFA
By definition, a
deterministic finite automaton is a special case of a NFA, in which
- No state has an eps-transition
- For each state S and input a, there is at most one edge labeled a leaving S.
You can immediately see that a DFA is a more "normal" FSM. In fact the FSMs we were discussing earlier are DFAs.
Recognizing regexes with DFAs and with NFAs
To make this more tolerable, consider an example comparing the DFA and the NFA for the regex
(a|b)*abb we saw earlier. Here is the DFA:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_3.jpg]()
And this is the NFA:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_4.jpg]()
Can you see a NFA unique feature in this diagram? Look at state 0. When the input is
a, where can we move? To state 0 and state 1 - a multiple transition, something that is illegal in a DFA. Take a minute to convince yourself that this NFA indeed accepts
(a|b)*abb. For instance, consider the input string
abababb. Recall how NFA's
acceptance of a string is defined. So, is there a path in the NFA graph above that "spells out"
abababb? There indeed is. The path will stay in state 0 for the first 4 characters, and then will move to states 1->2->3. Consider the input string
baabab. Is there a path that spells out this string? No, there isn't, as in order to reach the final state, we must go through
abb in the end, which the input string lacks.
Both NFAs and DFAs are important in computer science theory and especially in regular expressions. Here are a few points of difference between these constructs:
- It is simpler to build a NFA directly from a regex than a DFA.
- NFAs are more compact that DFAs. You must agree that the NFA diagram is much simpler for the (a|b)*abb regex. Due to its definition, a NFA doesn't explicitly need many of the transitions a DFA needs. Note how elegantly state 0 in the NFA example above handles the (a|b)* alternation of the regex. In the DFA, the char a can't both keep the automaton in state 0 and move it to state 1, so the many transitions on a to state 1 are required from any other state.
- The compactness also shows in storage requirements. For complex regexes, NFAs are often smaller than DFAs and hence consume less space. There are even cases when a DFA for some regex is exponential in size (while an NFA is always linear) - though this is quite rare.
- NFAs can't be directly simulated in the sense DFAs can. This is due to them being nondeterministic "beings", while our computers are deterministic. They must be simulated using a special technique that generates a DFA from their states "on the fly". More on this later.
- The previous leads to NFAs being less time efficient than DFAs. In fact, when large strings are searched for regex matches, DFAs will almost always be preferable.
There are several techniques involving DFAs and NFAs to build recognizers from regexes:
- Build a NFA from the regex. "Simulate" the NFA to recognize input.
- Build a NFA from the regex. Convert the NFA to a DFA. Simulate the DFA to recognize input.
- Build a DFA directly from the regex. Simulate the DFA to recognize input.
- A few hybrid methods that are too complicated for our discussion.
At first, I was determined to spare you from the whole DFA/NFA discussion and just use the third - direct DFA - technique for recognizer generation. Then, I changed my mind, for two reasons. First, the distinction between NFAs and DFAs in the regex world is important. Different tools use different techniques (for instance, Perl uses NFA while lex and egrep use DFA), and it is valuable to have at least a basic grasp of these topics. Second, and more important, I couldn't help falling to the charms of the NFA-from-regex construction algorithm. It is simple, robust, powerful and complete – in one word, beautiful.
So, I decided to go for the second technique.
Construction of a NFA from a regular expression
Recall the basic building blocks of regular expressions:
eps which represents "nothing" or "no input"; characters from the input alphabet (we used
a and
b most often here); characters may be concatenated, like this:
abb; alternation
a|b meaning
a or
b; the star
* meaning "zero or more of the previous"; and grouping
().
What follows is
Thompson's construction - an algorithm that builds a NFA from a regex. The algorithm is syntax directed, in the sense that it uses the syntactic structure of the regex to guide the construction process.
The beauty and simplicity of this algorithm is in its modularity. First, construction of trivial building blocks is presented.
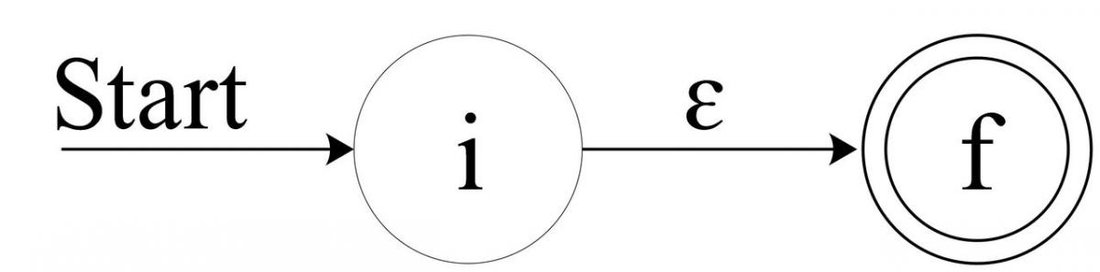
For
eps, construct the NFA:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_6.jpg]()
Here
i is a new start state and
f is a new accepting state. It's easy to see that this NFA recognizes the regex
eps.
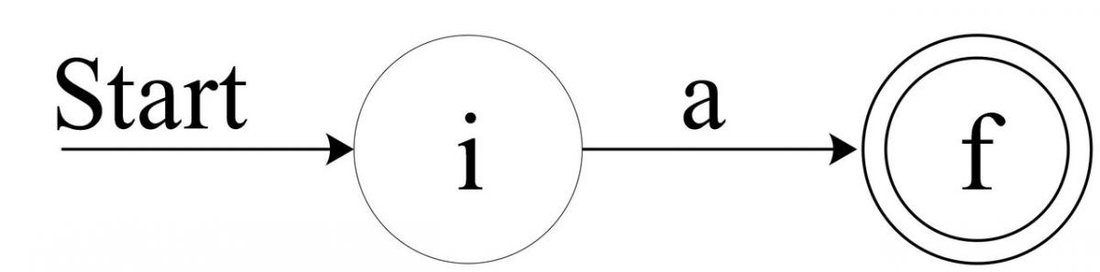
For some
a from the input alphabet, construct the NFA:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_7.jpg]()
Again, it's easy to see that this NFA recognizes the trivial regex
a.
Now, the interesting part of the algorithm: an inductive construction of complex NFAs from simple NFAs. More specifically, given that
N(s) and
N(t) are NFA's for regular expressions
s and
t, we'll see how to combine the NFAs
N(s) and
N(t) according to the combination of their regexes.
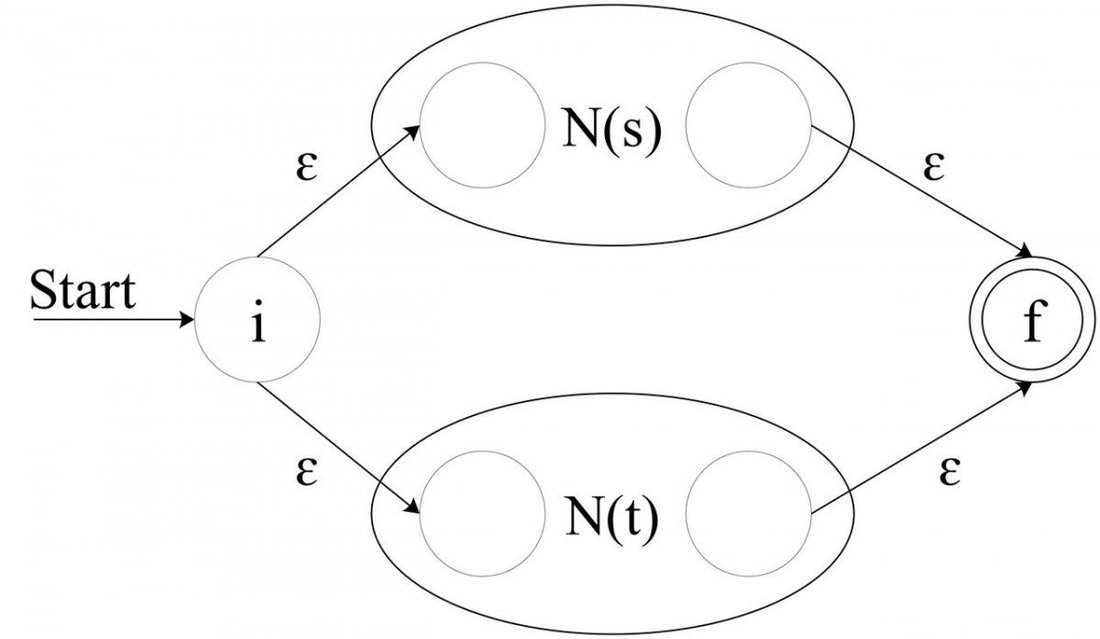
For the regular expression
s|t, construct the following composite NFA
N(s|t):
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_8.jpg]()
The
eps transitions into and out of the simple NFAs assure that we can be in either of them when the match starts. Any path from the initial to the final state must pass through either
N(s) or
N(t) exclusively. Thus we see that this composite NFA recognizes
s|t.
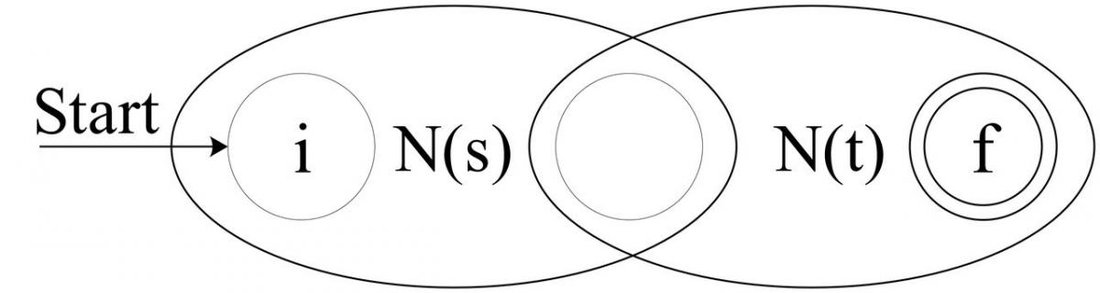
For the regular expression
st (
s and then
t), construct the composite NFA
NFA(st):
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_9.jpg]()
The composite NFA will have the start state of
N(s) and the end state of
N(t). The accepting (final) state of
N(s) is merged with the start state of
N(t). Therefore, all paths going through the composite NFA must go through
N(s) and then through
N(t), so it indeed recognizes
N(st).
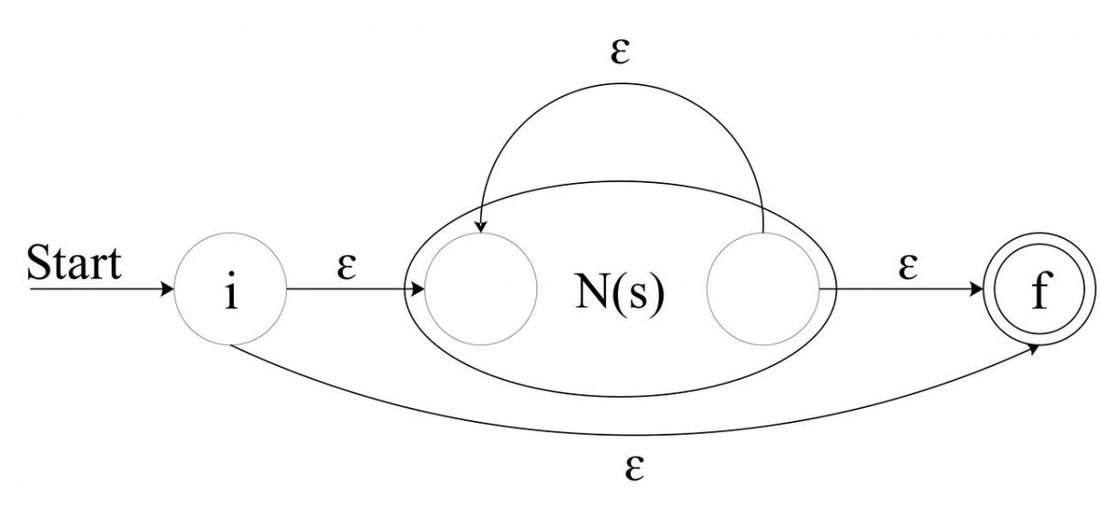
For the regular expression
s*, construct the composite NFA
N(s*):
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_10.jpg]()
Note how simply the notion of "zero or more" is represented by this NFA. From the initial state, either "nothing" is accepted with the
eps transition to the final state or the "more than" is accepted by going into
N(s). The
eps transition inside
N(s) denotes that
N(s) can appear again and again.
For the sake of completeness: a parenthesized regular expression
(s) has the same NFA as
s, namely
N(s).
As you can see, the algorithm covers all the building blocks of regular expressions, denoting their translations into NFAs.
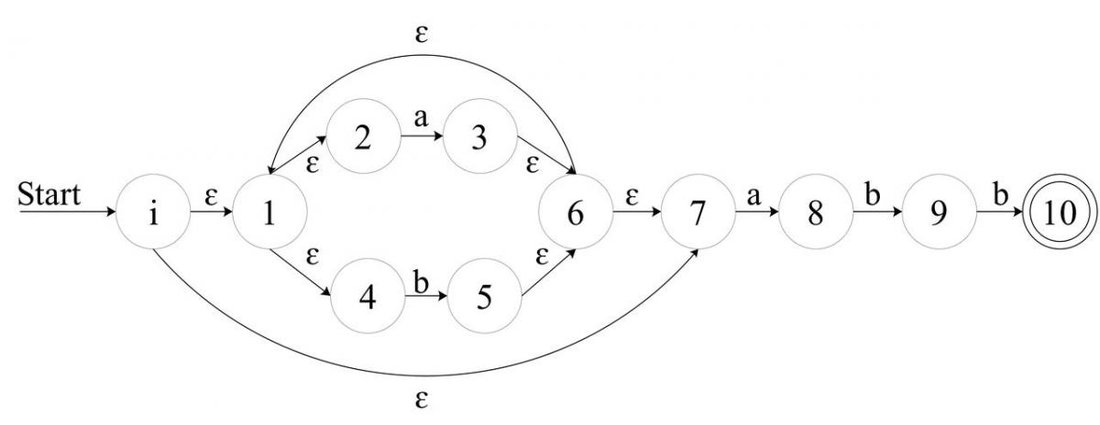
An example
If you follow the algorithm closely, the following NFA will result for (our old friend,) the regex
(a|b)*abb:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_11.jpg]()
Sure, it is much larger than the NFA we saw earlier for recognizing the same regex, but this NFA was automatically generated from a regex description using
Thompson's construction, rather than crafted by hand.
Let's see how this NFA was constructed:
First, it's easy to note that states 2 and 3 are the basic NFA for the regex
a.
Similarly, states 4 and 5 are the NFA for
b.
Can you see the
a|b? It's clearly states 1,2,3,4,5,6 (without the
eps transition from 6 to 1).
Parenthesizing
(a|b) doesn't change the NFA
The addition of states 0 and 7, plus the
eps transition from 6 to 1 is the star on
NFA(a|b), namely states 0 - 7 represent
(a|b)*.
The rest is easy. States 8 - 10 are simply the concatenation of
(a|b)* with
abb.
Try to run a few strings through this NFA until you convince yourself that it indeed recognizes
(a|b)*abb. Recall that a NFA recognizes a string when the string's characters can be spelled out on some path from the initial to the final state.
Implementation of a simple NFA
At last, let's get our hands on some code. Now that we know the theory behind NFA-from-regex construction, it's clear that we will be doing some NFA manipulations. But how will we represent NFAs in code?
NFA is not a trivial concept, and there are full-blown implementations for general NFAs that are far too complex for our needs. My plan is to code as simple an implementation as possible - one that will be enough for our needs and nothing more. After all, the regex recognizing engine is not supposed to expose its NFAs to the outer world - for us a NFA is only an intermediate representation of a regular expression, which we want to simulate in order to "accept" or "reject" input strings.
My philosophy in such cases is the KISS principle: "Keep It Simple, Stupid". The goal is first to code the simplest implementation that fits my needs. Later, I have no problem refactoring parts of the code and inserting new features, on an as-needed basis.
A very simple NFA implementation is now presented. We will build upon it later, and for now it is enough just to demonstrate the concept. Here is the interface:
#ifndef NFA_H
#define NFA_H
#include <vector>
using namespace std;
// Convenience types and constants
typedef unsigned state;
typedef char input;
enum {EPS = -1, NONE = 0};
class NFA
{
public:
// Constructed with the NFA size (amount of
// states), the initial state and the final state
NFA(unsigned size_, state initial_, state final_);
// Adds a transition between two states
void add_trans(state from, state to, input in);
// Prints out the NFA
void show(void);
private:
bool is_legal_state(state s);
state initial;
state final;
unsigned size;
vector<vector<input> > trans_table;
};
#endif // NFA_H
As promised, the public interface is kept trivial, for now. All we can do is create a NFA object (specifying the amount of states, the start state and the final state), add transitions to it, and print it out. This NFA will then consist of states 0 .. size-1, with the given transitions (which are single characters). Note that we use only one final state for now, for the sake of simplicity. Should we need more than one, it won't be difficult to add.
A word about the implementation: I don't want to go deep into graph-theory here (if you're not familiar with the basics, a web search can be very helpful), but basically a NFA is a directed graph. It is most common to implement a graph using either a matrix or an array of linked lists. The first implementation is more speed efficient, the second is better space-wise. For our NFA I picked the matrix (vector of vectors), mostly because (in my opinion) it is simpler.
The classic matrix implementation of a graph has 1 in cell (
i,
j) when there is an edge between vertex
i and vertex
j, and 0 otherwise.
A NFA is a special graph, in the sense that we are interested not only in whether there is an edge, but also in the condition for the edge (the input that leads from one state to another in FSM terminology). Thus, our matrix holds inputs (a nickname for chars, as you can see). So, for instance, '
c' in trans_table[i][j] means that the input '
c' leads from state
i to state
j in our NFA.
Here is the implementation of the NFA class:
#include <iostream>
#include <string>
#include <cassert>
#include <cstdlib>
#include "nfa.h"
using namespace std;
NFA::NFA(unsigned size_, state initial_, state final_)
{
size = size_;
initial = initial_;
final = final_;
assert(is_legal_state(initial));
assert(is_legal_state(final));
// Initialize trans_table with an "empty graph",
// no transitions between its states
for (unsigned i = 0; i < size; ++i)
{
vector<input> v;
for (unsigned j = 0; j < size; ++j)
{
v.push_back(NONE);
}
trans_table.push_back(v);
}
}
bool NFA::is_legal_state(state s)
{
// We have 'size' states, numbered 0 to size-1
if (s < 0 || s >= size)
return false;
return true;
}
void NFA::add_trans(state from, state to, input in)
{
assert(is_legal_state(from));
assert(is_legal_state(to));
trans_table[from][to] = in;
}
void NFA::show(void)
{
cout < "This NFA has " < size < " states: 0 - " < size - 1 < endl;
cout < "The initial state is " < initial < endl;
cout < "The final state is " < final < endl < endl;
for (unsigned from = 0; from < size; ++from)
{
for (unsigned to = 0; to < size; ++to)
{
input in = trans_table[from][to];
if (in != NONE)
{
cout < "Transition from " < from < " to " < to < " on input ";
if (in == EPS)
{
cout < "EPS" < endl;
}
else
{
cout < in < endl;
}
}
}
}
}
The code is very simple, so you should have no problem understanding what every part of it does. To demonstrate, let's see how we would use this class to create the NFA for
(a|b)*abb - the one we built using
Thompson's construction earlier (only the driver code is included):
#include "nfa.h"
int main()
{
NFA n(11, 0, 10);
n.add_trans(0, 1, EPS);
n.add_trans(0, 7, EPS);
n.add_trans(1, 2, EPS);
n.add_trans(1, 4, EPS);
n.add_trans(2, 3, 'a');
n.add_trans(4, 5, 'b');
n.add_trans(3, 6, EPS);
n.add_trans(5, 6, EPS);
n.add_trans(6, 1, EPS);
n.add_trans(6, 7, EPS);
n.add_trans(7, 8, 'a');
n.add_trans(8, 9, 'b');
n.add_trans(9, 10, 'b');
n.show();
return 0;
}
This would (quite expectedly) result in the following output:
This NFA has 11 states: 0 - 10
The initial state is 0
The final state is 10
Transition from 0 to 1 on input EPS
Transition from 0 to 7 on input EPS
Transition from 1 to 2 on input EPS
Transition from 1 to 4 on input EPS
Transition from 2 to 3 on input a
Transition from 3 to 6 on input EPS
Transition from 4 to 5 on input b
Transition from 5 to 6 on input EPS
Transition from 6 to 1 on input EPS
Transition from 6 to 7 on input EPS
Transition from 7 to 8 on input a
Transition from 8 to 9 on input b
Transition from 9 to 10 on input bAs I mentioned earlier: as trivial as this implementation may seem at the moment, it is the basis we will build upon later. Presenting it in small pieces will, hopefully, make the learning curve of this difficult subject less steep for you.
Implementing Thompson's Construction
Thompson's Construction tells us how to build NFAs from trivial regular expressions and then compose them into more complex NFAs. Let's start with the basics:
The simplest regular expression
The most basic regular expression is just some single character, for example
a. The NFA for such a regex is:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_7.jpg]()
Here is the implementation:
// Builds a basic, single input NFA
NFA build_nfa_basic(input in)
{
NFA basic(2, 0, 1);
basic.add_trans(0, 1, in);
return basic;
}
Just to remind you about our NFA implementation: The first line of the function creates a new (with no transitions yet) NFA of size 2 (that is: with 2 states), and sets state 0 to be the initial state and state 1 to be the final state. The second line adds a transition to the NFA that says "
in moves from state 0 to state 1". That's it - a simple regex, a simple construction procedure.
Note that this procedure is suited for the construction of an
eps transition as well.
Some changes to the NFA class
The previous implementation of a simple NFA class was just a starting point and we have quite a few changes to make.
First of all, we need direct access to all of the class's data. Instead of providing get and set accessors (which I personally dislike), all of the class members (size, initial, final and trans_table) have been made public.
Recall what I told you about the internal representation inside the NFA class - it's a matrix representing the transition table of a graph. For each
i and
j, trans_table[i][j] is the input that takes the NFA from state
i to state
j. It's NONE if there's no such transition (hence a lot of space is wasted - the matrix representation, while fast, is inefficient in memory).
Several new operations were added to the NFA class for our use in the NFA building functions. Their implementation can be found in nfa.cpp (included in the source code attached to this article). For now, try to understand how they work (it's really simple stuff), later you'll see why we need them for the implementation of various Thompson Construction stages. It may be useful to have the code of nfa.cpp in front of your eyes, and to follow the code for the operations while reading these explanations. Here they are:
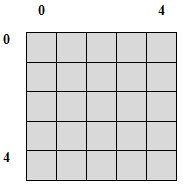
append_empty_state - I want to append a new, empty state to the NFA. This state will have no transitions to it and no transitions from it. If this is the transition table before the appending (a sample table with size 5 - states 0 to 4):
![Attached Image: table.png]()
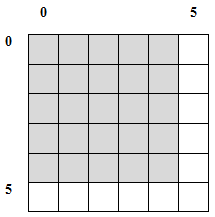
Then this is the table after the appending:
![Attached Image: table2.png]()
The shaded cells are the transitions of the original table (be they empty or not), and the white cells are the new table cells - containing NONE.
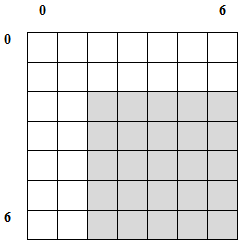
shift_states - I want to rename all NFA's states, shifting them "higher" by some given number. For instance, if I have 5 states numbered 0 - 4, and I want to have the same states, just named 2 - 6, I will call shift_states(2), and will get the following table:
![Attached Image: table3.png]()
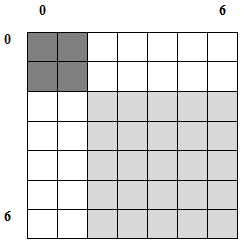
fill_states - I want to copy the states of some other NFA into the first table cells of my NFA. For instance, if I take the shifted table from above, and fill its first two states with a new small NFA, I will get (the new NFA's states are darkest):
![Attached Image: table4.png]()
Note that using fill_states after shift_states is not incidental. These two operations were created to be used together - to concatenate two NFAs. You'll see how they are employed shortly.
Now I will explain how the more complex operations of Thompson's Construction are implemented. You should understand how the operations demonstrated above work, and also have looked at their source code (a good example of our NFA's internal table manipulation). You may still lack the "feel" of why these operations are needed, but this will soon be covered. Just understand how they work, for now.
Implementing alternation: a|b
Here is the diagram of NFA alternation from earlier:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_8.jpg]()
Given two NFAs, we must build another one that includes all the states of both NFAs plus additional, unified initial and final states. The function that implements this in nfa.cpp is build_nfa_alter. Take a look at its source code now - it is well commented and you should be able to follow through all the steps with little difficulty. Note the usage of the new NFA operations to complete the task. First, the NFAs states are shifted to make room for the full NFA. fill_states is used to copy the contents of nfa1 to the unified NFA. Finally, append_empty_state is used to add another state at the end - the new final state.
Implementing concatenation: ab
Here is the diagram of NFA concatenation from earlier:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_9.jpg]()
Given two NFAs, we must build another one that includes all the states of both NFAs (note that nfa1's final and nfa2's initial states are overlapping). The function that implements this in nfa.cpp is build_nfa_concat. Just as in build_nfa_alter, the new NFA operations are used to construct, step by step, a bigger NFA that contains all the needed states of the concatenation.
Implementing star: a*
Here is the diagram of the NFA for a* from earlier:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_10.jpg]()
Although the diagram looks complex, the implementation of this construction is relatively simple, as you'll see in build_nfa_star. There's no need to shift states, because no two NFAs are joined together. There's only a creation of new initial and final states, and new
eps transitions added to implement the star operation.
Specialty of NFAs constructed by Thompson's Construction
You might have observed that all the NFAs constructed by Thompson's Construction have some very specific behavior. For instance, all the basic building blocks for single letters are similar, and the rest of the constructions just create new links between these states to allow for the alternation, concatenation and star operations. These NFAs are also special implementation-wise. For instance, note that in our NFA implementation, the first state is always the initial, and the last state is always final. You may have noted that this is useful in several operations.
A complete NFA construction implementation
With these operations implemented, we now have a full NFA construction implementation in nfa.cpp! For instance, the regex
(a|b)*abb can be built as follows:
NFA a = build_nfa_basic('a');
NFA b = build_nfa_basic('b');
NFA alt = build_nfa_alter(a, b);
NFA str = build_nfa_star(alt);
NFA sa = build_nfa_concat(str, a);
NFA sab = build_nfa_concat(sa, b);
NFA sabb = build_nfa_concat(sab, b);
With these steps completed, sabb is the NFA representing
(a|b)*abb. Note how simple it's to build NFAs this way! There's no need to specify individual transitions like we did before. In fact, it's not necessary to understand NFAs at all - just build the desired regex from its basic blocks, and that's it.
Even closer to complete automation
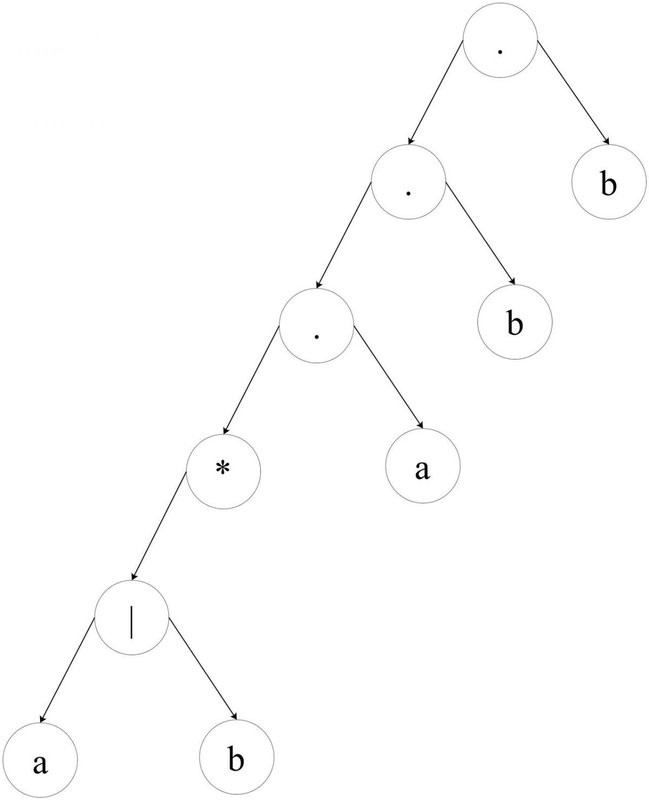
Though it has now become much simpler to construct NFAs from regular expressions, it's still not as automatic as we'd like it to be. One still has to explicitly specify the regex structure. A useful representation of structure is an expression tree. For example, the construction above closely reflects this tree structure:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_13.jpg]()
In this tree: . is concatenation, | is alternation, and * is star. So, the regex
(a|b)*abb is represented here in a tree form, just like an arithmetic expression.
Such trees in the world of parsing and compilation are called expression trees, or parse trees. For example, to implement an infix calculator (one that can calculate, for example: 3*4 + 5), the expressions are first turned into parse trees, and then these parse trees are walked to make the calculations.
Note, this is, as always, an issue of representation. We have the regex in a textual representation:
(a|b)*abb and we want it in NFA representation. Now we're wondering how to turn it from one representation to the other. My solution is to use an intermediate representation - a parse tree. Going from a regex to a parse tree is similar to parsing arithmetic expressions, and going from a parse tree to a NFA will be now demonstrated, using the Thompson's Construction building blocks described in this article.
From a parse tree to a NFA
A parse tree in our case is just a binary tree, since no operation has more than two arguments. Concatenation and alternations have two arguments, hence their nodes in the tree have two children. Star has one argument - hence only the left child. Chars are the tree leaves. Take a good look at the tree drawn above, you'll see this very clearly.
Take a look at the file regex_parse.cpp from the source code archive on the book's companion website. It has a lot in it, but you only need to focus only on some specific things for now. First, let's look at the definition of parse_node:
typedef enum {CHR, STAR, ALTER, CONCAT} node_type;
// Parse node
struct parse_node
{
parse_node(node_type type_, char data_, parse_node* left_, parse_node* right_) :
type(type_),
data(data_),
left(left_),
right(right_)
{
}
node_type type;
char data;
parse_node* left;
parse_node* right;
};
This is a completely normal definition of a binary tree node that contains data and some type by which it is identified. Let us ignore, for the moment, the question of how such trees are built from regexes (if you're very curious - it's all in regex_parse.cpp), and instead think about how to build NFAs from such trees. It's very straight forward since the parse tree representation is natural for regexes. Here is the code of the tree_to_nfa function from regex_parse.cpp:
NFA tree_to_nfa(parse_node* tree)
{
assert(tree);
switch (tree->type)
{
case CHR:
return build_nfa_basic(tree->data);
case ALTER:
return build_nfa_alter(tree_to_nfa(tree->left), tree_to_nfa(tree->right));
case CONCAT:
return build_nfa_concat(tree_to_nfa(tree->left), tree_to_nfa(tree->right));
case STAR:
return build_nfa_star(tree_to_nfa(tree->left));
default:
assert(0);
}
}
Not much of a rocket science, is it? The power of recursion and trees allows us to build NFAs from parse trees in just 18 lines of code...
From a regex to a parse tree
If you've already looked at regex_parse.cpp, you surely noted that it contains quite a lot of code, much more than I've show so far. This code is the construction of parse trees from actual regexes (strings like
(a|b)*abb).
I really hate to do this, but I won't explain how this regex-to-tree code works. You'll just have to believe me it works (or study the code - it's there!). As a note, the parsing technique I employ to turn regexes into parse trees is called Recursive Descent parsing. It's an exciting topic and there is plenty of information available on it, if you are interested.
Converting NFAs to DFAs
The N in NFA stands for non-deterministic. Our computers, however, are utterly deterministic beasts, which makes "true" simulation of an NFA impossible. But we do know how to simulate DFAs. So, what's left is to see how NFAs can be converted to DFAs.
The algorithm for constructing from an NFA a DFA that recognizes the same language is called "Subset Construction". The main idea of this algorithm is in the following observations:
- In the transition table of an NFA, given a state and an input there's a set of states we can move to. In a DFA, however, there's only one state we can move to.
- Because of eps transitions, even without an input there's a set of states an NFA can be in at any given moment. Not so with the DFA, for which we always know exactly in what state it is.
- Although we can't know in which state from the sets described above the NFA is, the set is known. Therefore, we will represent each set of NFA states by a DFA state. The DFA uses its state to keep track of all possible states the NFA can be in after reading each input symbol.
Take, for example, the familiar NFA of the
(a|b)*abb regex (generated automatically by Thompson's Construction, with the code from the last column):
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_11.jpg]()
The initial state of this NFA is 0... or is it ? Take a look at the diagram, and count in how many states this NFA can be
before any input is read. If you remember the previous columns where I explained how
eps transitions work, you should have no trouble noticing that initially, the NFA can be in any of the states {0, 1, 2, 4, 7}, because these are the states reachable by
eps transitions from the initial state.
Note: the set T is reachable by
eps from itself
by definition (the NFA doesn't have to take an
eps transition, it can also stay in its current state).
Now imagine we received the input
a. What happens next? In which states can the NFA be now? This should be easy to answer. Just go over all the states the NFA can be in
before the input, and see where the input
a leads from them. This way, a new set emerges: {1, 2, 3, 4, 6, 7, 8}. I hope you understand why: initially, the NFA can be in states {0, 1, 2, 4, 7}. But from states 0, 1 and 4 there are no transitions on
a. The only transitions on
a from that set are from state 2 (to state 3) and from state 7 (to state 8). However, the states {3, 8} is an incomplete answer. There are
eps transitions from these states - to states {1, 2, 4, 6, 7}, so the NFA can actually be in any of the states {1, 2, 3, 4, 6, 7, 8}.
If you understand this, you understand mostly how the Subset Construction algorithm works. All that's left is the implementation details. But before we get to the implementation of the conversion algorithm itself, there are a couple of prerequisites.
eps-closure
Given N - an NFA and T - a set of NFA states, we would like to know which states in N are reachable from states T by
eps transitions.
eps-closure is the procedure that answers this question. Here is the algorithm:
algorithm eps-closure
inputs: N - NFA, T - set of NFA states
output: eps-closure(T) - states reachable from T by eps transitions
eps-closure(T) = T
foreach state t in T
push(t, stack)
while stack is not empty do
t = pop(stack)
foreach state u with an eps edge from t to u
if u is not in eps-closure(T)
add u to eps-closure(T)
push(u, stack)
end
return eps-closure(T)
This algorithm iteratively finds all the states reachable by
eps transitions from the states T. First, the states T themselves are added to the output. Then, one by one the states are checked for
eps transitions, and the states these transitions lead to are also added to the output, and are pushed onto the stack (in order to be checked for
eps transitions). The process proceeds iteratively, until no more states can be reached with
eps transitions only.
For instance, for the
(a|b)*abb NFA above, eps-closure({0}) = {0, 1, 2, 4, 7}, eps-closure({8, 9}) = {8, 9}, etc.
In the attached source code, the implementation of eps-closure is in the file subset_construct.cpp, function build_eps_closure. It follows the algorithm outlined above very closely, so you should have no trouble understanding it.
move - a new NFA member function
Given T - a set of NFA states, and A - an input, we would like to know which states in the NFA are reachable from T with the input A. This operation was implemented in the function move, in nfa.cpp (member of the NFA class). The function is very simple. It traverses the set T, and looks for transitions on the given input, returning the states that can be reached. It doesn't take into account the
eps transitions from those states - there's eps-closure for that.
Keeping track of the input language of an NFA
For reasons that will soon become obvious, we must keep track of the input language used in the NFA. For example, for the regex
(a|b)*abb the language is {a, b}. A new member was added to the NFA class for this purpose - inputs. Take a look at the implementation in nfa.cpp to see how it's managed.
DFA implementation
Since we intend to build DFAs in this column, we need a DFA implementation. A very basic implementation was coded in dfa.h - take a look at it now. The DFA's transition table is implemented with a map, that maps (state, input) pairs to states. For example, (t1, i) will be mapped to t2 if input i in state t1 leads to state t2. Note that it's not the same representation as the one I used for the NFA. There are two reasons for this difference:
- I want you to see two different implementations of a graph (which is what a transition table is, as I told you before). Both are legitimate for certain purposes.
- A little bit of cheating... I know which operations I'll need from the DFA, so I'm tailoring the representation to these operations. This is a very common programming trick - one should always think about the ways a data structure will be used before he designs its exact implementation.
So take a look at dfa.h - the DFA implementation is very simple - only a transition table, a start state and a set of final states. There are also methods for showing the DFA and for simulating it...
To remind you, this is the algorithm for DFA simulation :
algorithm dfa-simulate
inputs: D - DFA, I - Input
output: ACCEPT or REJECT
s = start state of D
i = get next input character from I
while not end of I do
s = state reached with input i from state s
i = get next input character from I
end
if s is a final state
return ACCEPT
else
return REJECT
Let's now finally learn how the DFA is built.
Subset Construction
In the Introduction, I provided some observations about following NFA states, and gave an example. You saw that while it's impossible to know in what state an NFA is at any given moment, it's possible to know the set of states it can be in. Then, we can say with certainty that the NFA is in one of the states in this set, and not in any state that's not in the set.
So, the idea of Subset Construction is to build a DFA that keeps track where the NFA can be. Each state in this DFA stands for a set of states the NFA can be in after some transition. "How is this going to help us?", you may ask yourself. Good question.
Recall how we simulate a DFA (if you don't feel confident with this material, read the 2nd part of Algorithmic Forays again). When can we say that a DFA recognizes an input string? When the input string ends, we look at the state we're left in. If this is a final state - ACCEPT, if it's not a final state - REJECT.
So, say that we have a DFA, each state of which represents a set of NFA states. Since a NFA will always "pick the correct path", we can assume that if the set contains a final state, the NFA will be in it, and the string is accepted. More formally: A DFA state D represents S - a set of NFA states. If (and only if) one or more of the states in S is a final state, then D is a final state. Therefore, if a simulation ends in D, the input string is accepted.
So, you see, it's useful to keep track of sets of NFA states. This will allow us to correctly "simulate" an NFA by simulating a DFA that represents it.
Here's the Subset Construction algorithm:
algorithm subset-construction
inputs: N - NFA
output: D - DFA
add eps-closure(N.start) to dfa_states, unmarked
D.start = eps-closure(N.start)
while there is an unmarked state T in dfa_states do
mark(T)
if T contains a final state of N
add T to D.final
foreach input symbol i in N.inputs
U = eps-closure(N.move(T, i))
if U is not in dfa_states
add U to dfa_states, unmarked
D.trans_table(T, i) = U
end
The result of this procedure is D - a DFA with a transition table, a start state and a set of final states (not incidentally just what we need for our DFA class...).
Here are some points to help you understand how
subset-construction works:
- It starts by creating the initial state for the DFA. Since, as we saw in the Introduction, an initial state is really the NFA's initial state plus all the states reachable by eps transitions from it, the DFA initial state is the eps-closure of the NFA's initial state.
- A state is "marked" if all the transitions from it were explored.
- A state is added to the final states of the DFA if the set it represents contains the NFA's final state
- The rest of the algorithm is a simple iterative graph search. Transitions are added to the DFA transition table for each symbol in the alphabet of the regex. So the DFA transition actually represents a transition to the eps-closure in each case. Recall once again: a DFA state represents a set of states the NFA can be in after a transition.
This algorithm is implemented in the function subset_construct in subset_construct.cpp, take a look at it now. Here are some points about the implementation:
- dfa_states from the algorithm is represented by two sets: marked_states and unmarked_states, with the obvious meanings.
- Since DFA states are really sets of NFA states (see the state_rep typedef), something must be done about numbering them properly (we want a state to be represented by a simple number in the DFA). So, the dfa_state_num map takes care of it, with the numbers generated on-demand by gen_new_state.
- The loop runs while the unmarked_states set is not empty. Then, "some" state is marked by taking it out from the unmarked set (the first member of the set is picked arbitrarily) and putting it into the marked set.
I hope an example will clear it all up. Let's take our favorite regex -
(a|b)*abb, and show how the algorithm runs on the NFA created from it. Here's the NFA again:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_11.jpg]()
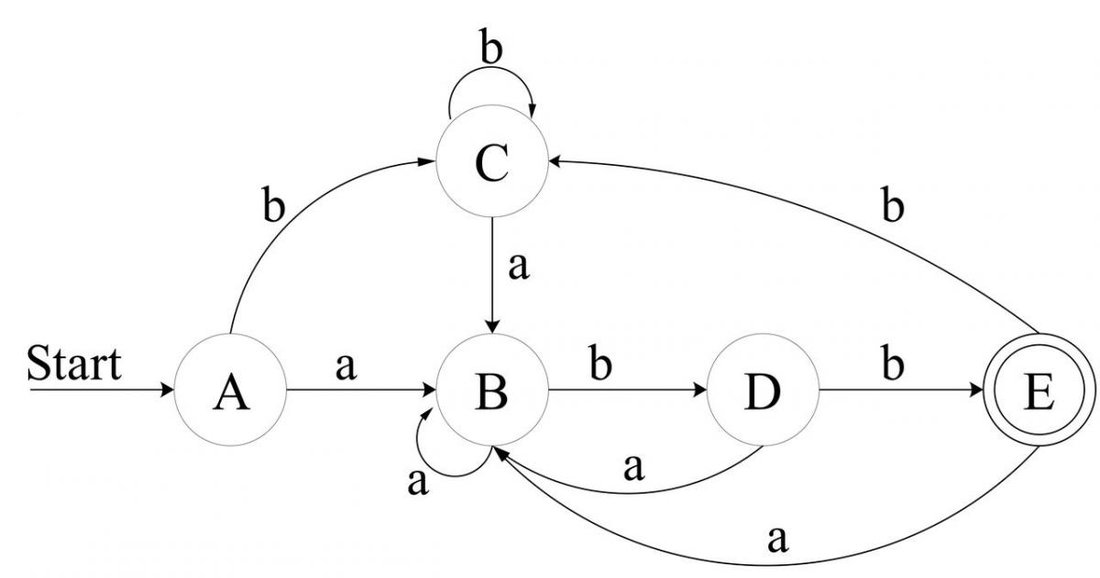
Following the algorithm: The start state of the equivalent DFA is the
eps-closure of NFA state 0, which is A = {0, 1, 2, 4, 7}. So, we enter into the loop and mark A. A doesn't contain a final state, so we don't add it to the DFA's final set. The input symbol alphabet of the regex
(a|b)*abb is {a, b}, so first we compute eps-closure(move(A, a)). Let's expand this:
eps-closure(move({0, 1, 2, 4, 7}, a)) = eps-closure({3, 8}) = {1, 2, 3, 4, 6, 7, 8}
Let's call this set B. B is not a member of dfa_states yet, so we add it there, unmarked. We also create the DFA transition D.trans_table(A, a) = B. Now we're back to the inner loop, with the input b. Of all the states in set A, the only transition on b is from 4 to 5, so we create a new set:
C = eps-closure((move(A, b)) = eps-closure({5}) = {1, 2, 4, 5, 6, 7}
So C is added, unmarked, to dfa_states. Since all the alphabet symbols are done for A, we go back to the outer loop. Are there any unmarked states? Yes, there are B and C. So we pick B and go over the process again and again, until all the sets that are states of the DFA are marked. Then, the algorithm terminates, and D.trans_table contains all the relevant transitions for the DFA. The five different sets we get for DFA states are:
A = {0, 1, 2, 4, 7}
B = {1, 2, 3, 4, 6, 7, 8}
C = {1, 2, 4, 5, 6, 7}
D = {1, 2, 4, 5, 6, 7, 9}
E = {1, 2, 4, 5, 6, 7, 10}
A is the initial state of the DFA, since it contains the NFA initial state 0. E is obviously the only final state of the NFA, since it's the only one containing the NFA final state 10. If you follow the whole algorithm through and take note of the DFA transitions created, this is the resulting diagram:
![Attached Image: AdvGameProg_FSMandRDP_Bendersky_14.jpg]()
You can easily:
- See that this is a DFA - no eps transitions, no more than a single transition on each input from a state.
- Verify that it indeed recognizes the regular expression (a|b)*abb
Conclusion
We've come a long way, and finally our mission is accomplished. We've created a real regular expression engine. It's not a complete engine like the one Lex or Perl have, but it's a start. The basis has been laid, the rest is just extensions. Let's see what we have:
- A regular expression is read into a parse tree (implemented in regex_parse.cpp) - I didn't actually explain how this part is done, but you can trust me (and I hope you verified!) that it works.
- An NFA is built from the regular expression, using Thompson's Construction (implemented in nfa.h/cpp)
- The NFA is converted to a DFA, using the Subset Construction algorithm (implemented in subset_construct.h/cpp and dfa.h)
- The resulting DFA is simulated using the DFA simulation algorithm (implemented in dfa.h)
A small main function is implemented in regex_parse.cpp. It reads a regex and a string as arguments, and says whether the string fits the regex. It does it by going through the steps mentioned above, so I advise you to take a look at it and make sure that you understand the order in which things are called.