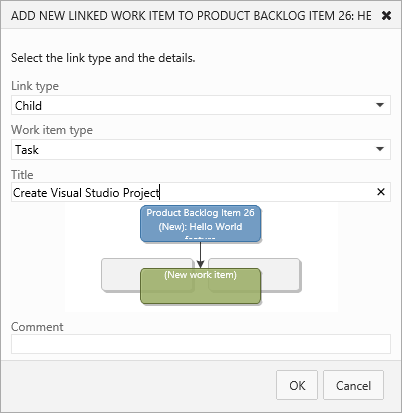
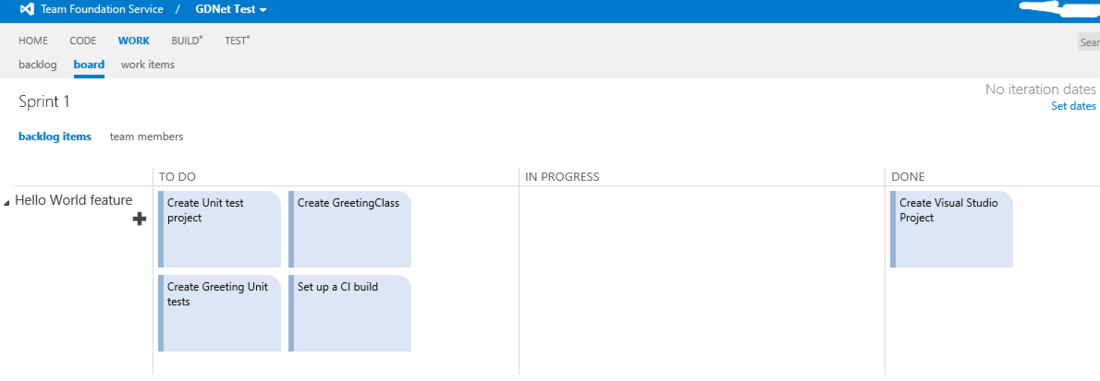
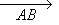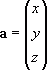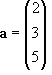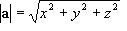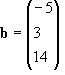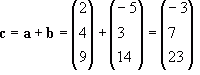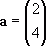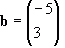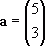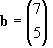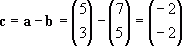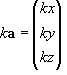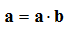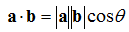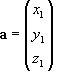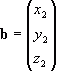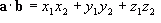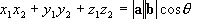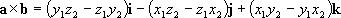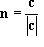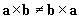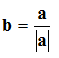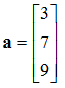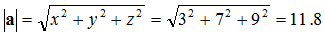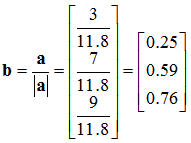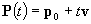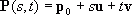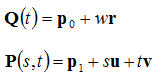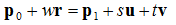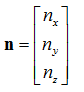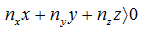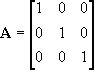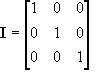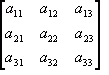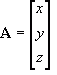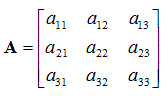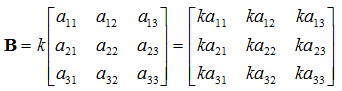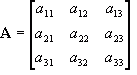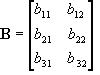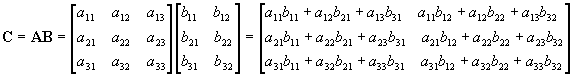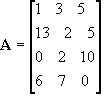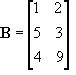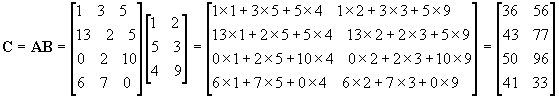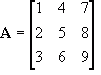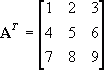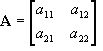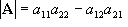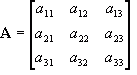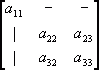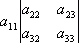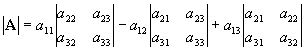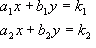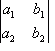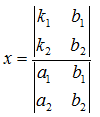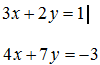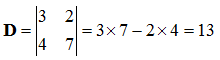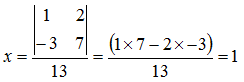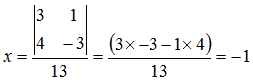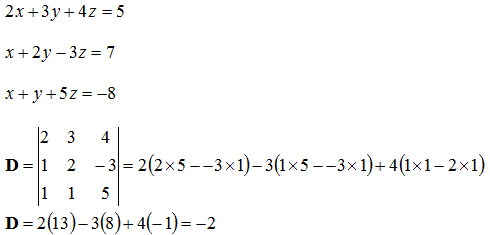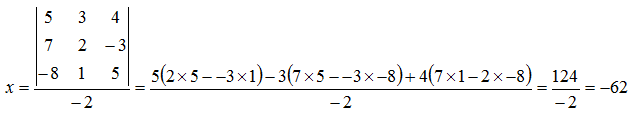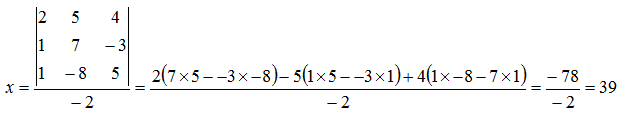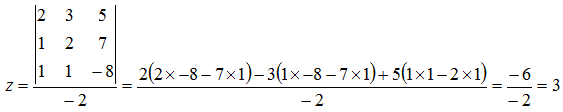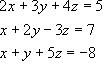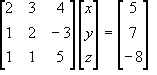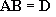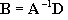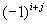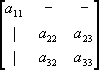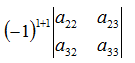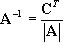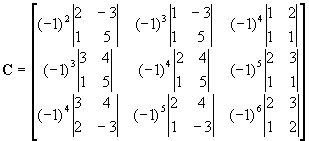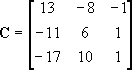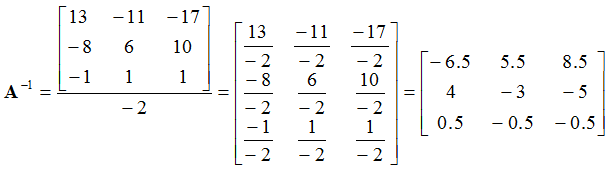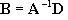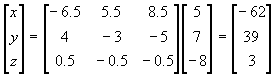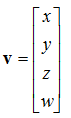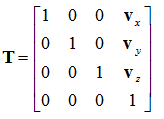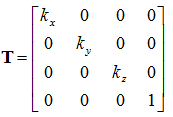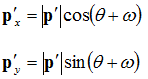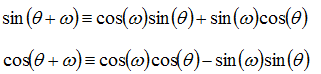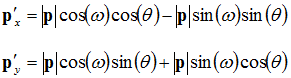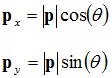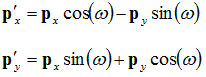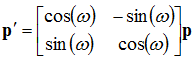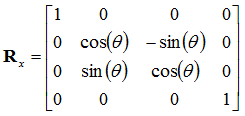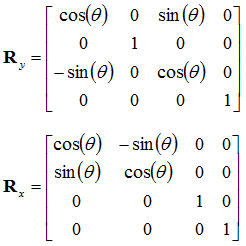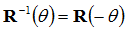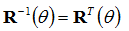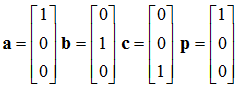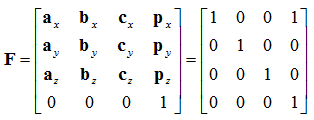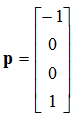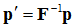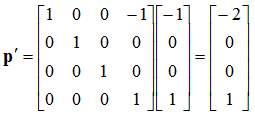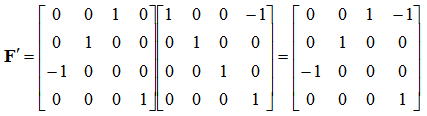Preface
This article is designed for those who need to brush up on your maths. Here we will discuss vectors, the operations we can perform on them, and why we find them so useful. We’ll then move onto what matrices and determinants are, and how we can use them to help us solve systems of equations. Finally, we’ll move onto using matrices to define transformations in space.
Note:
This article was originally published to GameDev.net back in 2002. It was revised by the original author in 2008 and published in the book Beginning Game Programming: A GameDev.net Collection, which is one of 4 books collecting both popular GameDev.net articls and new original content in print format.
Vectors
Vector Basics – What is a vector?
Vectors are the backbone of games. They are the foundation of graphics, physics modelling, and a number of other things. Vectors can be of any dimension, but are most commonly seen in two, three, or four dimensions. They essentially represent a direction, and a magnitude. Thus, consider the velocity of a ball in a football game. It will have a direction (where it's travelling), and a magnitude (the speed at which it is travelling). Normal numbers (i.e. single dimensional numbers) are called
scalars.
The notation for a vector is that of a bold lower-case letter, like
i, or an italic letter with an underscore, like
i. I'll use the former in this text. You can write vectors in a number of ways, however I'll only use two here: vector equations and column vectors.
Vectors can be written in terms of its starting and ending position, using the two end points with an arrow above them. So, if you have a vector between the two points A and B, you can write that as:
![Attached Image: ccs-8549-0-74933000-1311406833_thumb.gif]()
A vector equation takes the form:
a = x
i + y
j + z
k
The coefficients of the
i,
j, and
k parts of the equation are the vectors
components. These are how long each vector is in each of the 3 axis.
For example, the vector equation pointing to the point ( 3, 2, 5 ) from the origin ( 0, 0, 0 ) in 3D space would be:
a = 2
i + 3
j + 5
k
The second way I will represent vectors is as
column vectors. These are vectors written in the following form:
![Attached Image: ccs-8549-0-13322100-1311406871_thumb.gif]()
Where
x,
y, and
z are the components of that vector in the respective directions. These are exactly the same as the respective components of the vector equation. Thus in column vector form, the previous example could be written as:
![Attached Image: ccs-8549-0-41119900-1311406881_thumb.gif]()
There are various advantages to both of the above forms, although column vectors will continue to be used. Various mathematic texts may use the vector equation form.
Vector Mathematics
There are many ways in which you can operate on vectors, including scalar multiplication, addition, scalar product, vector product and modulus.
Modulus
The
modulus or
magnitude of a vector is simply its length. This can easily be found using Pythagorean Theorem with the vector components. The modulus is written like so:
a = |
a|
Given:
![Attached Image: ccs-8549-0-13322100-1311406871_thumb.gif]()
Then,
![Attached Image: ccs-8549-0-18438000-1311406906_thumb.gif]()
Where
x,
y and
z are the components of the vector in the respective axis.
Addition
Vector addition is rather simple. You just add the individual components together. For instance, given:
![Attached Image: ccs-8549-0-52337300-1311406947_thumb.gif]()
The addition of these vectors would be:
![Attached Image: ccs-8549-0-28558500-1311406958_thumb.gif]()
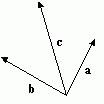
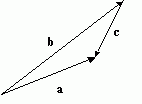
This can be represented very easily in a diagram, for example:
![Attached Image: ccs-8549-0-12549800-1311406970_thumb.gif]()
![Attached Image: ccs-8549-0-52518500-1311406982_thumb.gif]()
![Attached Image: ccs-8549-0-25839100-1311406994_thumb.gif]()
This works in the same way as moving the second vector so that its beginning is at the first vector's end, and taking the vector from the beginning of the first vector to the end of the second one. So, in a diagram, using the above example, this would be:
![Attached Image: ccs-8549-0-06202600-1311407005_thumb.gif]()
This means that you can add multiple vectors together to get the resultant vector. This is used extensively in mechanics for finding resultant forces.
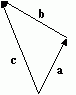
Subtracting
Subtracting is very similar to adding, and is also quite helpful. The individual components are simply subtracted from each other. The geometric representation however is quite different from addition. For example:
![Attached Image: ccs-8549-0-83651900-1311407019_thumb.gif]()
![Attached Image: ccs-8549-0-31746600-1311407031_thumb.gif]()
![Attached Image: ccs-8549-0-13826600-1311407045_thumb.gif]()
The visual representation is:
![Attached Image: ccs-8549-0-75087900-1311407058_thumb.gif]()
Here,
a and
b are set to be from the same origin. The vector
c is the vector from the end of the second vector to the end of the first, which in this case is from the end of
b to the end of
a.
It may be easier to think of this as a vector addition, where instead of having:
c =
a –
b
We have:
c = -
b +
a
Which according to what was said about the addition of vectors would produce:
![Attached Image: ccs-8549-0-75087900-1311407058_thumb.gif]()
You can see that putting
a on the end of –
b has the same result.
Scalar Multiplication
This is another simple operation; all you need to do is multiply each component by that scalar. For example, let us suggest that you have a vector
a and a scalar
k. To perform a scalar multiplication you would multiply each component of the vector by that scalar, thus:
![Attached Image: ccs-8549-0-13322100-1311406871_thumb.gif]()
![Attached Image: ccs-8549-0-84633600-1311407105_thumb.gif]()
This has the effect of lengthening or shortening the vector by the amount
k. For instance, take
k = 2; this would make the vector a twice as long. Multiplying by a negative scalar reverses the direction of the vector.
The Scalar Product (Dot Product)
The
scalar product, also known as the
dot product, is very useful in 3D graphics applications. The scalar product is written:
![Attached Image: dot.png]()
This is read “a dot b”.
The definition of the scalar product is:
![Attached Image: scalar.png]()
Θ is the angle between the two vectors
a and
b. This produces a scalar result, hence the name scalar product. This operation has the result of giving the length of the projection of
a on
b. For example:
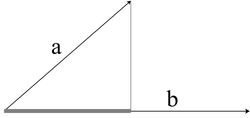
![Attached Image: BegGameProg_VectorsAndMatricesAPrimer_Dadd_5.jpg]()
The length of the thick gray horizontal line segment would be the dot product.
The scalar product can also be written in terms of Cartesian components as:
![Attached Image: ccs-8549-0-11366200-1311407231_thumb.gif]()
![Attached Image: ccs-8549-0-25055400-1311407243_thumb.gif]()
![Attached Image: ccs-8549-0-12617400-1311407255_thumb.gif]()
We can put the two dot product equations equal to each other to yield:
![Attached Image: ccs-8549-0-33111200-1311407287_thumb.gif]()
With this, we can find angles between vectors.
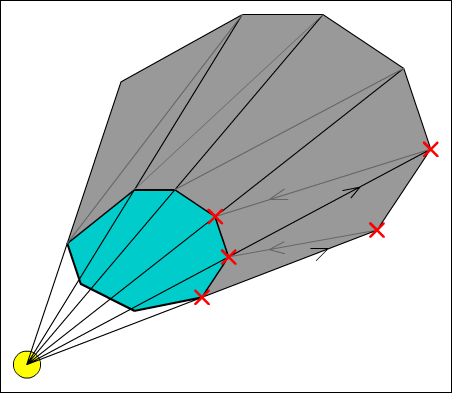
Scalar products are used extensively in the graphics pipeline to see if triangles are facing towards or away from the viewer, whether they are in the current view (known as frustum culling), and other forms of culling.
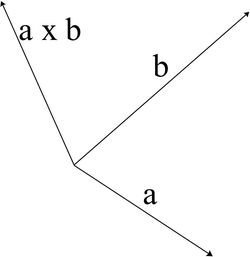
The Vector Product (Cross Product)
The
vector product, also commonly known as the
cross product, is one of the more complex operations performed on vectors. In simple terms, the vector product produces a vector that is perpendicular to the vectors having the operation applied. Great for finding normal vectors to surfaces!
![Attached Image: BegGameProg_VectorsAndMatricesAPrimer_Dadd_6.jpg]()
I’m not going to get into the derivation of the vector product here, but in expanded form it is:
![Attached Image: index.gif]()
Read “a cross b”.
Since the cross product finds the perpendicular vector, we can say that:
i x
j =
k
j x
k =
i
k x
i =
j
Note that the resultant vectors are perpendicular in accordance with the “right hand screw rule”. That is, if you make your thumb, index and middle fingers perpendicular, the cross product of your middle finger with your thumb will produce your index finger.
Using scalar multiplication along with the vector product we can find the "normal" vector to a plane. A plane can be defined by two vectors,
a and
b. The normal vector is a vector that is perpendicular to a plane and is also a unit vector. Using the formulas discussed earlier, we have:
c =
a x
b
![Attached Image: ccs-8549-0-47469800-1311407367_thumb.gif]()
This first finds the vector perpendicular to the plane made by
a and
b then scales that vector so it has a magnitude of 1.
One important point about the vector product is that:
![Attached Image: index.gif]()
This is a very important point. If you put the inputs the wrong way round then you will not get the correct normal.
Unit Vectors
These are vectors that have a unit length, i.e. a modulus of one. The
i,
j and
k vectors are examples of unit vectors aligned to the respective axis. You should now be able to recognise that vector equations are quite simply just that. Adding together 3 vectors scaled by varying degrees to produce a single resultant vector.
To find the unit vector of another vector, we use the modulus operator and scalar multiplication like so:
![Attached Image: UV1.png]()
For example:
![Attached Image: UV2.png]()
![Attached Image: UV3.png]()
![Attached Image: UV4.png]()
That is the unit vector
b in the direction of
a.
Position Vectors
These are the only type of vectors that have a position to speak of. They take their starting point as the origin of the coordinate system in which they are defined. Thus, they can be used to represent points in that space.
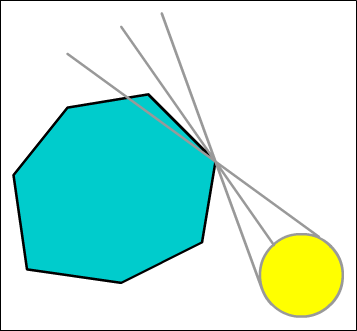
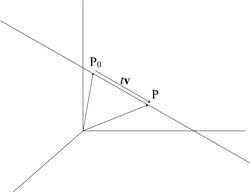
The Vector Equation of a Straight Line
The vector equation of a straight line is very useful, and is given by a point on the line and a vector parallel to it:
![Attached Image: index.gif]()
Where
p0 is a point on the line, and
v is the unit vector giving its direction.
t is called the parameter and scales
v. From this you can see that as
t varies a line is formed in the direction of
v.
![Attached Image: BegGameProg_VectorsAndMatricesAPrimer_Dadd_7.jpg]()
This equation is called the
parametric form of a straight line. Using this to find the vector equation of a line through two points is easy:
![Attached Image: ccs-8549-0-39434100-1311407462_thumb.gif]()
If
t is constrained to values between 0 and 1, then we have a
line segment starting at the point
p0 and
p1.
Using the vector equation we can define planes and test for intersections. A plane can be defined as a point on the plane, and two vectors that are parallel to the plane.
![Attached Image: ccs-8549-0-74851200-1311407475_thumb.gif]()
Where
s and
t are the parameters, and
u and
v are the vectors that are parallel to the plane. Using this, you can find the intersection of a line and a plane, as the point of intersection must line on both the plane at the line. Thus, we simply make the two equations equal to each other.
Given the line and plane:
![Attached Image: vline1.png]()
To find the intersection we equate so that:
![Attached Image: vline2.png]()
We then solve for
w,
s and
t, and plug them into either the line or plane equation to find the point. When testing for a line segment
w must be in the range 0 to 1.
Another representation of a plane is the normal-distance. This combines the normal of the plane, and its distance from the origin along that normal. This is especially useful for finding out what sides of a plane points are. For example, given the plane
p and point
a:
![Attached Image: ccs-8549-0-11366200-1311407231_thumb.gif]() p
p =
n +
d
Where,
![Attached Image: neq.png]()
The point
a is in front of the plane
p if:
![Attached Image: neq2.png]()
This is used extensively in various culling mechanisms.
Matrices
What is a Matrix anyway?
A matrix can be considered a 2D array of numbers, and take the form:
![Attached Image: ccs-8549-0-61157600-1311407567_thumb.gif]()
Matrices are very powerful, and form the basis of all modern computer graphics. We define a matrix with an upper-case bold type letter, as shown above. The dimension of a matrix is its height followed by its width, so the above example has dimension 3x3. Matrices can be of any dimensions, but in terms of computer graphics, they are usually kept to 3x3 or 4x4. There are a few types of special matrices; these are the
column matrix,
row matrix,
square matrix,
identity matrix and
zero matrix. A column matrix is one that has a width of 1, and a height of greater than 1. A row matrix is a matrix that has a width of greater than 1, and a height of 1. A square matrix is when the dimensions are the same. For instance, the above example is a square matrix, because the width equals the height. The identity matrix is a special type of matrix that has values in the diagonal from top left to bottom right as 1 and the rest as 0. The identity matrix is known by the letter
I, where:
![Attached Image: ccs-8549-0-35181600-1311407600_thumb.gif]()
The identity matrix can be any dimension, as long as it is also a square matrix.
The
elements of a matrix are all the numbers within it. They are numbered by the row/column position such that:
![Attached Image: ccs-8549-0-86930600-1311407611_thumb.gif]()
The zero matrix is one that has all its elements set to 0.
Vectors can also be used in column or row matrices. I will use column matrices here, as that is what I have been using in the previous section. A 3D vector
a in matrix form will use a matrix
A with dimension 3x1 so that:
![Attached Image: ccs-8549-0-72535500-1311407625_thumb.gif]()
Which as you can see is the same layout as using column vectors.
Matrix Arithmetic
I’m not going to go into every possible matrix manipulation (we would be here some time), instead I’ll focus on the important ones.
Scalar / Matrix Multiplication
To perform this operation all you need to do is simply multiply each element by the scalar. Thus, given matrix
A and scalar
k:
![Attached Image: scalarX.png]()
![Attached Image: scalarX2.png]() Matrix / Matrix Multiplication
Matrix / Matrix Multiplication
Multiplying a matrix by another matrix is more difficult. First, we need to know if the two matrices are
conformable. For a matrix to be conformable with another matrix, the number of rows in
A needs to equal the number of columns in
B. For instance, take matrix
A as having dimension 3x3 and matrix
B having dimension 3x2. These two matrices are conformable because the number of rows in
A is the same as the number of columns in
B. This is important as you'll see later. The product of these two matrices is another matrix with dimension 3x2.
So generally, given three matrices
A,
B and
C, where
C is the product of
A and
B.
A and
B have dimension
mx
n and
px
q respectively. They are conformable if
n=
p. The matrix
C has dimension
mx
q. It is said that the two matrices are conformable if their
inner dimensions are equal (
n and
p here).
The multiplication is performed by multiplying each row in
A by each column in
B. Given:
![Attached Image: ccs-8549-0-58828200-1311407689_thumb.gif]()
![Attached Image: ccs-8549-0-75807400-1311407700_thumb.gif]()
![Attached Image: index.gif]()
So, with that in mind let us try an example!
![Attached Image: ccs-8549-0-79987200-1311407726_thumb.gif]()
![Attached Image: ccs-8549-0-00678700-1311407738_thumb.gif]()
![Attached Image: index.gif]()
It’s as simple as that! Some things to note:
![Attached Image: ccs-8549-0-29109000-1311407760_thumb.gif]()
A matrix multiplied by the identity matrix is the same, so:
AI =
IA =
A
The Transpose
The
transpose of a matrix is it flipped along the diagonal from the top left to the bottom right and is denoted by using a superscript
T, for example:
![Attached Image: ccs-8549-0-93459600-1311407784_thumb.gif]()
![Attached Image: ccs-8549-0-35495300-1311407805_thumb.gif]()
Determinants
Determinants are a useful tool for solving certain types of equations, and are used rather extensively.
Let’s take a 2x2 matrix
A:
![Attached Image: ccs-8549-0-76083400-1311407842_thumb.gif]()
The determinant of matrix
A is written |
A| and is defined to be:
![Attached Image: ccs-8549-0-61430500-1311407863_thumb.gif]()
That is the top left to bottom right diagonal multiplied together subtracting the top right to bottom left diagonal. Things get a bit more complicated with higher dimensional determinants, let us discuss a 3x3 determinant first. Take
A as:
![Attached Image: ccs-8549-0-93920700-1311407878_thumb.gif]()
Step 1: move to the first value in the top row, a11. Take out the row and column that intersects with that value.
![Attached Image: ccs-8549-0-41315500-1311407890_thumb.gif]()
Step 2: multiply that determinant by a11.
![Attached Image: ccs-8549-0-76373600-1311407901_thumb.gif]()
We repeat this along the top row, with the sign in front of the result of step 2 alternating between a “+” and a “-“. Given this, the determinant of
A becomes:
![Attached Image: index.gif]()
Now, how do we use these for equation solving? Good question.
Given a pair of simultaneous equations with two unknowns:
![Attached Image: ccs-8549-0-36208700-1311407930_thumb.gif]()
We first
push these coefficients of the variables into a determinant, producing:
![Attached Image: ccs-8549-0-95740300-1311407941_thumb.gif]()
You can see that it is laid out in the same way. To solve the equation in terms of
x, we replace the
x coefficients in the determinant with the constants
k1 and
k2, dividing the result by the original determinant:
![Attached Image: det1.png]()
To solve for
y we replace the
y coefficients with the constants instead. This algorithm is called
Cramers Rule.
Let’s try an example to see this working, given the equations:
![Attached Image: det2.png]()
We push the coefficients into a determinant and solve:
![Attached Image: det3.png]()
To find
x substitute the constants into the
x coefficients, and divide by
D:
![Attached Image: det4.png]()
To find
y substitute the constants into the
y coefficients, and divide by
D:
![Attached Image: det5.png]()
It’s as simple as that! For good measure, let’s do an example using 3 unknowns in 3 equations:
![Attached Image: det6.png]()
Solve for
x:
![Attached Image: det7.png]()
Solve for
y:
![Attached Image: det8.png]()
Solve for
z:
![Attached Image: det9.png]()
And there we have it, how to solve a series of simultaneous equations using determinants, something that can be very useful.
Matrix Inversion
Equations can also be solved by inverting a matrix. Using the same equations as before:
![Attached Image: ccs-8549-0-56571200-1311408118_thumb.gif]()
We first push these into three matrices to solve:
![Attached Image: ccs-8549-0-90083900-1311408131_thumb.gif]()
Let’s give these names such that:
![Attached Image: ccs-8549-0-02710700-1311408147_thumb.gif]()
We need to solve for
B (this contains the unknowns after all). Since there is no “matrix divide” operation, we need to invert
A and multiply it by
D such that:
![Attached Image: ccs-8549-0-35483900-1311408160_thumb.gif]()
Now we need to know how to actually do the matrix inversion. There are many ways to do this, and the way that I’m going to use here is by no means the fastest.
To find the inverse of a matrix, we need to first find its
co-factor. We use a method similar to what we used when finding the determinant. What you do is this: at every element, eliminate the row and column that intersects it, and make it equal the determinant of the remaining part of the matrix, multiplied by the following expression:
![Attached Image: index.gif]()
Where
i and
j is the position in the matrix.
For example, given a 3x3 matrix
A, and its co-factor
C. To calculate the fist element in the cofactor matrix (c11), we first need to get rid of the row and column that intersects this so that:
![Attached Image: ccs-8549-0-44070200-1311408176_thumb.gif]()
c11 would then take the value of the following:
![Attached Image: fig.png]()
We would then repeat for all elements in matrix
A to build up the co-factor matrix
C. The inverse of matrix
A can then be calculated using the following formula.
![Attached Image: ccs-8549-0-23509400-1311408221_thumb.gif]()
The transpose of the co-factor matrix is also referred to as the
adjoint.
Given the previous example and equations, let’s find the inverse matrix of
A.
Firstly, the co-factor matrix
C would be:
![Attached Image: index.gif]()
![Attached Image: ccs-8549-0-53635100-1311408248_thumb.gif]()
|
A| is:
|
A| = -2
Thus, the inverse of
A is:
![Attached Image: inverse.png]()
We can then solve the equations by using:
![Attached Image: ccs-8549-0-36524500-1311408291_thumb.gif]()
![Attached Image: index.gif]()
We can find the values of
x,
y and
z by pulling them out of the resultant matrix, such that:
x = -62
y = 39
z = 3
Which is exactly what we got by using Cramer’s rule!
Matrices are said to be
orthogonal if its transpose equals its inverse, which can be a useful property to quick inverting of matrices.
Matrix Transformations
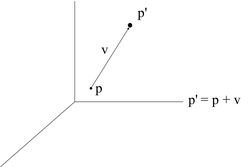
Graphics APIs use a set of matrices to define transformations in space. A transformation is a change, be it translation, rotation, or whatever. Using position vector in a column a matrix to define a point in space, a
vertex, we can define matrices that alter that point in some way.
Transformation Matrices
Most graphics APIs use three different types of primary transformations. These are translation; scaling; and rotation. We can transform a point
p using a transformation matrix
T to a point
p' like so:
p' =
Tp
We use 4 dimensional vectors from now on, of the form:
![Attached Image: 4d.png]()
We then use 4x4 transformation matrices. The reason for the 4th component here is to help us perform translations using matrix multiplication. These are called
homogeneous coordinates. I won’t go into their full derivation here, as that is quite beyond the scope of this article (their true meaning and purpose comes from points in projective space).
Translation
To translate a point onto another point, there needs to be a vector of movement, so that:
![Attached Image: BegGameProg_VectorsAndMatricesAPrimer_Dadd_8.jpg]()
Where
p’ is the translated point,
p is the original point and
v is the vector along which the translation has taken place.
By keeping the w component of the vector as 1, we can represent this transformation in matrix form as:
![Attached Image: transform.png]() Scaling
Scaling
You can scale a vertex by multiplying it by a scalar value, such that:
![Attached Image: index.gif]()
Where
k is the scalar constant. You can multiply each component of
p by a different constant. This will make it so you can scale each axis by a different amount.
In matrix form this becomes:
![Attached Image: scaling.png]()
Where
kx,
ky, and
kz are the scaling factors in the respective axis.
Rotation
Rotation is a more complex transformation, so I’ll give a more thorough derivation for this than I have the others.
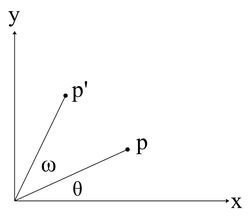
Rotation in a plane (i.e. in 2D) can be described in the following diagram:
![Attached Image: BegGameProg_VectorsAndMatricesAPrimer_Dadd_10.jpg]()
This diagram shows that we want to rotate some point
p by ω degrees to point
p'. From this we can deduce the following equations:
![Attached Image: rotation.png]()
We are dealing with rotations about the origin, thus the following can be said:
|
P'| = |
P|
Using the trigonometric identities for the sum of angles:
![Attached Image: rotation2.png]()
We can expand the previous equations to:
![Attached Image: rotation3.png]()
From looking at the diagram, you can also see that:
![Attached Image: rotation4.png]()
Substituting those into our equations, we end up with:
![Attached Image: rotation5.png]()
Which is what we want (the second point as a function of the first point).
We can then push this into matrix form:
![Attached Image: rotation6.png]()
Here, we have the rotation matrix for rotating a point in the x-y plane. We can expand this into 3D by having three different rotation matrices, one for rotating along the x axis, one in the y axis, and another for the z axis (this one is effectively what we have just done). The unused axis in each rotation remains unchanged. These rotation matrices become:
![Attached Image: rotation7.png]()
![Attached Image: rotation8.png]()
Any rotation about an axis by θ can be undone by a successive rotation by –θ, thus:
![Attached Image: rotation9.png]()
Also, notice that the cosine terms are always on the top left to bottom right diagonal, and notice the symmetry of the sine terms along this axis. This means, we can also say:
![Attached Image: rotation10.png]()
Rotation matrices that act upon the origin are orthogonal.
One important point to consider is the order of rotations (and transformations in general). A rotation along the x axis followed by a rotation along the y axis is
not the same as if it were applied in reverse. Similarly, a translation followed by a rotation does
not produce the same result as a rotation followed by a translation.
Frames
A frame can be considered a local coordinate system, or
frame of reference. That is, a set of three
basis vectors (unit vectors perpendicular to each other), plus a position, relative to some other frame. So, given the basis vectors and position:
![Attached Image: frames.png]()
That is
a,
b, and
c defines the basis vectors, with
p being its position.
We can push this into a matrix, defining the frame, like so:
![Attached Image: frames2.png]()
This matrix is useful, as it lets us transform points into a second frame – so long as those points exist in the same frame as the second frame. Thus, consider a point in some frame:
![Attached Image: frames3.png]()
Assuming the frame we defined above is in the same frame as that point, we can transform this point to be in our frame like so:
![Attached Image: frames4.png]()
That is:
![Attached Image: frames5.png]()
Which if you think about it is what you would expect. If you have a point at -1 along the x axis, and you transform it into a frame that is at +1 along the x axis and orientated the same, then
relative to that second frame the point appears at -2 along
its x axis.
This is useful for transforming vertices between different frames, and is incredibly useful for having objects moving relative to one frame, while that frame itself is moving relative to another one. You can simply multiply a vertex first by its parent frame, then by its parents frame, and so forth to eventually get its position in
world space, or the global frame.
You can also use the standard transformation matrices previously to transform frames with ease. For instance, we can transform the above frame to rotate by 90º along the y axis like so:
![Attached Image: frames6.png]()
This is exactly what you would expect (the z axis to move to where the x axis was, and the x axis point in the opposite direction to the original z axis).
Summary
Well that’s it for this article. We’ve gone through what vectors are, the operations that we can perform on them and why we find them useful. We then moved onto matrices, how they help us solve sets of equations, including how to use determinants. We then moved on to how to use matrices to help us perform transformations in space, and how we can represent that space as a matrix.
I hope you’ve found this article useful!
References
Interactive Computer Graphics – A Top Down Approach with OpenGL – Edward Angel
Mathematics for Computer Graphics Applications – Second Edition – M.E Mortenson
Advanced National Certificate Mathematics Vol.: 2 – Pedoe